强化学习
元素:actor(我们可以控制,决策我们的行为),Env,Reward(我们不能控制环境)
主要方法:model-baed(对Env建模,actor可以理解环境), model-free(policy-based,value-based);on-policy(学习与互动的actor为一同一个),off-policy(学习与互动actor不同);MC(eposidic),TD
本文主要介绍了Policy Gradient,Q-learning,Actor-Critic,Sparse Reward,Imitation Learning及其变体(PPO,PPO2,TRPO,A2C,A3C,DPGP)和一些tips(Double DQN, Dueling DQN,Distributional Q-function,ICM等)等相关内容,最后对比了RL与GAN等价结构。
Policy Gradient
考虑一个actor π与环境互动,收集(s,a,r,s'),其中π(a|s)为我们可以控制的policy,Env在收到actor 动作后给出下一个s'和r,这是无法控制的!且r一般为随机变量,我们考虑一个trajectory完成时的total reward,也就是所有r的和R(必然一个问题是R的方差极大)。由于R为随机变量,我们考虑最大化R的均值,也就是sample一些π的trajectory,然后求均值R'。

使用 gradient ascend来最大化R',这里参数θ只与π(a|s)有关,最后得到可sample的式子。其中 每笔trajectory的数据只能用一次,actor更新之后就不能用了。 实际操作时可以看为加权的分类问题S->A,选择cross-entropy,权重为R,R可以不可导。

tip1 : add a baseline, 可能 R都是正的,导致不论什么a都增加其几率,当sample够大这不是问题,但 sample小的话会潜在降低没有sample出a的几率。b一般与s有关。比如可以使用R的均值等。
tip2: assign suitable credit,一个 trajectory中所有a的r都一样是不合理的,只考虑t之后的r,可以考虑discount rate。当sample足够大,也不是问题,数据可以区分不同a的作用。其中 R' - b为advantage function,衡量用θ这个模型,在s中采取a相对于其他action的好坏(Critic)。
最终:

PPO (TRPO,PPO2)
原因:policy gradient为on-policy,sample一次更新完actor之后,actor就变了,不能使用原来的数据了,必须重新与Env互动收集新数据,这导致训练需要大量互动,降低效率。
Important sampling:使用其他分布q获得数据,来估计基于分布p的函数期望,用户不能直接从p中采样的情况。需要注意的是p与q不能差太多,因为函数期望虽然无偏,但是方差可能很大,当然如果sample数据足够多也没这个问题。
目标:使用θ'采样的数据,训练θ这个actor,过程中θ'是fixed的所以可以重复使用用θ'的数据训练θ许多次,增加数据利用率,提高训练速度,为openAI的default方法。显然,此方法转为了off-policy。
注意:因为θ' 是与环境交互的actor,所以advantage function 的估计需要使用θ'的数据。

此为跟新需要的gradient,其中假设在不同actor中看到的s概率一样,则可以简化。通过gradient可以反推出目标函数。
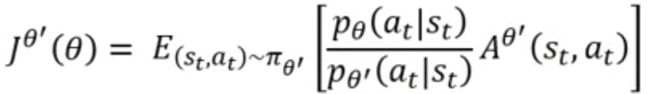
约束:由于θ'与θ不能差别太大,所以需要有个约束,比如在目标函数后加-βKL(θ,θ')作为约束(PPO);或者外面引入KL(θ,θ') < δ.(TRPO,PPO前身,用constraint计算上不好处理)
说明:因为可能参数小的变化,行为变化很大,衡量无意义。所以。KL(θ,θ')不是参数上的距离,而是行为上的距离!π(a|s)的分布接近!
tip:adaptive KL Penalty,权衡β。定义KLmin和KLmax,当KL > KLmax,说明penalty作用没发挥,则增加β的值,反之亦然。
PPO2:不用计算KL,同样可以控制θ与θ'之间差距。


说明:当A>0,也就是a是好的,我们希望增加Pθ的概率,但是,Pθ不能弄得太大,太大也就会使与Pθ'差距大,导致效果不好。反之亦然。
Q-Learning
value-based,学习Critic,评价现在的行为的相对好坏。
state value fucntion Vπ(s).: 期望累计奖励,给定π,s,衡量a的好坏。主要他必须与π相关,衡量这个actor,而不是单纯的s。
估计:
- MC(episodic),需要π经历一次整个过程后,进行统计估计,由于r为随机变量,所以此方法方差大,但是无偏的。
- TD, 根据Vπ(st)=Vπ(st+1)+rt估计,不需要每次经历完整过程。由于Vπ值都为估计值,可能存在估计不准,其中只涉及r,方差小
state-action value function(Q function) Qπ(s,a).:衡量π在s下,采取a的好坏。其中π不一定采取a,这里只是衡量如果在这采取a的情况。
形式:
- 输入s,a,输出Q
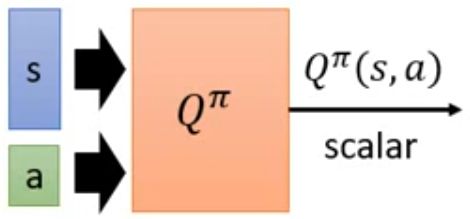 image.png
image.png - 输入s,输出每个a的Q,只能用于离散a
 image.png
image.png
目标:给定Q,找到一个比π更好的π',这里"更好"是说,对所有s,有Vπ'(s) >= Vπ(s)
决策:π'=argmax_aQπ(s,a),这里没有policy,依据Q来决定的,这个形式对连续a不好求解。
附:证明Vπ'(s) >= Vπ(s)

必用tips
-
target network
学习中数据为...(st,at,rt,st+1)...,训练目标为由于目标函数在更新后是变化的,训练十分不稳定。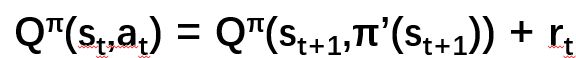 image.png
image.png
我们采用两个network,一个用来训练,一个用来计算目标target(右边的),训练时target固定住。当训练一定数目后再更新target network的参数(用训练network替换)。 -
exploration
Q-learning的policy是依赖于Q,每次选择最大Q的a,这样不利于收集数据,如果一开始没有采样到a,Q比较小,之后不会再采取这个a,无法准确估计Q(s,a)。
方法: ε-greedy :以ε概率随机选择a,通常 ε随着学习进行变小;
Boltzmann Exploration:基于Q值概率化,通过概率采样选择a,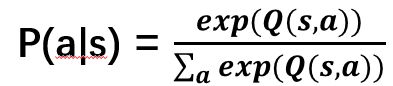 image.png
image.png Replay Buffer
把actor的每笔experience (st,at,rt,st+1)放到一个buffer里面,其中buffer里面的exp可能来自不同的actor,当buffer满了再替换旧的exp。训练过程时每次从buffer里面sample一个batch出来训练。
结果:变成了off-policy方法(可能来自于其他actor)
好处:RL训练过程中交互很耗时间,这样充分利用数据(可以反复利用数据),减少很Env互动次数;降低batch内相关性,训练效果更稳定(diverse),因为我们只用一个exp训练,并不是trajectory,所以off-policy也没关系。
高级Tips
-
Double DQN
解决Q值高估的问题。Q值一般都是被高估的,假设某个a被高估了,则target会选择被高估的a,则target总是会很大。
我们采取使用两个function Q和Q',其中Q选择a(训练用Q),Q'来估计q值(target Q'),当一个高估q的Q选择了高估的a,但是另一个可能会准确估计其q值;当Q'高估q,只有Q不选择a就ok,这样双重决策会缓解高估问题。采用target network和main network可以有效减少参数量。
 image.png
image.png -
Dueling DQN
改架构,使Q(s,a) = A(s,a) + V(s),有时候Q的值可能与a无关,而只与s有关,比如一个不好的s导致什么a都不好。当action不影响s时,没必要去衡量每个a的q值(只有在关键时刻a才重要!)
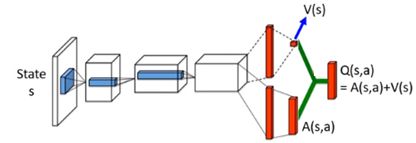 image.png
image.png
好处:当没有sample到a时,同样可以更新a,比较有效率地使用数据,加速训练。
说明:为了防止模型不训练V,可以给A(s,a)加约束。比如A(s,a)限制和为0等等。实际操作可以在A(s,a)最后一层加normalization op.
Prioritized Replay
改变sample data的分布,增加那些难训练的数据被采样的概率,TD error大的数据;同时可以改变训练过程。-
Multi-step
权衡MC与TD,结合MC与TD的好处与坏处,MC准确方差大,TD方差小,估计不准。可以通过调节N来权衡。replay buffer中存N步的exp,则target变成:
 image.png
image.png Noisy Net (State-dependent Exploration)
原本的exploration(ε-greedy)时对action加noise,现实中是不合理的(给同样s,采取的a不同,真是π不是这样的)。这里采用在每个参数上加gaussian noise,注意每次在sample net时是在每个episode开始使sample net,之后固定住net开始训练。这样在类似的s给出是类似的a,更合理,系统地探索环境(Explore in a consistent way)。-
Distributional Q-function
Q function为累计期望奖励,它为期望值,实际上在s采取a时,最终所有得到的reward为一个分布reward distribution,但是不同的分布可能期望是一样的。只用期望来代表reward会损失一些信息。
原来Q function为输出每个a的Q,Q为期望,现在输出每个a的Q的分布!实际上操作,假定reward distribution在一个范围内,拆成一些区间,输出在s采取a的reward落在某个区间的概率。在test时可以选择某个a期望最大的action执行,也可以考虑分布的方差,减低a的风险。此方法不会产生高估q值问题,因为一开始把q限制在一个范围内了(可能低估q)。
 image.png
image.png Rainbow
把以上方法全部结合起来!。。。
Q-learning总结:比较稳;只需要Q function就可以找到较好的π;容易操作。不易处理连续action情况。
如何用Q-learning处理连续a的情况:
1. sampling action: sample N a, choose maxQ(a,s)
2. gradient ascent solve the optimization problem, 存在local minimum,选择a时先要训练一个net..
3. 设计网络使优化目标好解,比如
Actor Critic (A2C, A3C, DPGP)
原始policy-based方法中梯度为
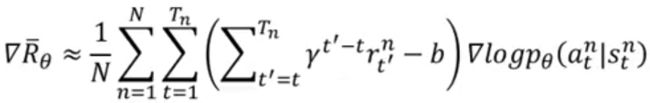
目标:直接估计累计reward的期望值代替sample的估计,使估计稳定。其中估计reward的期望值为value-based method。
根据Q function的定义:E[Gt]=Q(st,at), 所以可以用Q-learning学G。
baseline:与s有关,可以用Vπ(s)等表示,需要注意EQ(s,a)=V(s),所以Q-V有正有负!
最终:G-b = Q(s,a) - V(s),此时需要两个network分别预测Q和V,这会承担2倍风险预测不准确。
因为
为advantage function.
A2C
π先互动,收集exp,先估计V(s) (TD, MC),再估计π
tips
-
shared shallow layer:需要学习的两个network可以共享参数
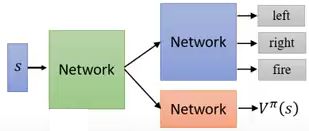 image.png
image.png output entropy as regularization for π(s),使action分布交均匀,实现exploration
A3C
A2C训练较慢,使用多个worker学习参数跟新梯度,一起更新Global Network的参数。每个worker从global network中拿参数,自己与环境互动,计算梯度,更新global network参数。注意,每个worker可能不是原始参数。

PDPG
从不同视角来看,原来Critc只评价a,现在可以引导π,告诉哪个a好;一种使用Q-learning解连续动作的方法,原来Q-learning不好解连续a的argmax的问题,现在用一个actor来解。
先训练Q,然后固定Q,训练actor使得Q最大,架构与GAN一样!generator为actor,discriminator为Q,为一个conditional GAN.
Q-learning中的技术都可以使用。
整个算法:

进而,GAN中的优化方法可以引入这里:

高级技法
Sparse Reward
agent可能大多时间没有reward,导致训练时不论采取什么a都一样好。
Reward Shaping:Env有自己固定的reward,我们引导actor刻意设计一些reward,学到期望的行为。可能有些actor在预测未来reward很难,则discount很大。设计reward不一定是Env真的reward,只是我们希望的行为,一般需要domain knowledge。
Curiosity:Intrinsic Curiosity module (ICM)

鼓励actor冒险,越难预测的s,则风险越大,增加exploration。但是不一定越难预测这个s就是好的,可能环境中的随机无关变量。进而引入feature extractor,把没有意义的无关变量过滤掉。则ICM可以为:

Curriculum Learning:为机器的学习做规划,有顺序地训练,从简单东西到难的东西(不只用于RL)。比如识别数字,先学习分辨0,1,然后学习分辨0-9。需要老师设计课程。
Reverse Curriculum Generation:给定一个goal state->根据goal state采样离goal state接近的state s1->从这个s1互动,看能否达到goal state,得到reward->删除reward 极端的state(reward太大,说明太简单,已经学会,反之亦然)->基于适中的reward的s1继续sample s2。
Hierachical RL:有许多不同等级的agent,高层的负责定目标,分配给底层的agent负责执行完成。大任务分解为小任务逐次实现。
注意:如果低级的agent不能实现目标,则高级的agent受惩罚,防止高层的agent提出太难的目标;如果agent最终实现了一个错误的goal,则假设正确的goal为这个错的!(三观不一)
Initation Learning
Appewnticeship Learning: learning by demonstration,整个任务没有reward!通过专家演示如何解决问题。
- 机器可以与环境互动,但是不会获得显示的奖励
- 有些任务很难定义reward(比如驾驶车无法判断撞男人和女人各有多少reward)
- 有些人工定义的reward可能导致无法控制的结果
方法:Behavior Cloning;Inverse Reinforcement Learning (inverse optimal control)
Behavior Cloning:监督学习,收集专家的(s,a)进行学习。
可能存在的问题:
- 专家只能提供有限的样本(专家很专业,不会经历一些极端情况,机器遇到无法决策)。
Dataset Aggregation:这种情况可以让专家在机器决策时处于机器的环境(收集专家在极端情况下的行为),但是机器还是做自己,专家给予指导,可能导致每次尝试损失一个专家。 - 机器可能只是单纯复制专家的行为,不论行为是是否相关(比如学到个人无关的坏行为),因为机器的capacity是有限的,可能只学到了坏行为(监督学习同等对待所有error)
- 训练数据与测试数据mismatch
supervised learning中我们希望训练集和测试集具有相同的分布。
但是在BC中,训练数据为(s,a)~π^(expert),其中专家的action会影响s的分布( RL特点);测试数据为(s',a')~π(actor clone expert)。当π^=π时,数据具有相同的分布;当不相等时,s与s'可能差异很大。
Inverse Reinforcement Learning:有Env,actor,Expert demonstration,但是没有reward function。利用expert行为反推reward function;接下来可利用RL找到optimal actor。
好处:可能reward function比较简单,也能导致expert的复杂行为。

方法:
- 有一个expert与环境互动得到一些专家数据
 image.png
image.png - 有一个actor π与环境互动得到数据
 image.png
image.png 反推一个reward function,原则为expert得到的分数比actor高。
利用这个reward fucntion使用RL方法学习actor,得到新数据。
-
基于新的actor与expert数据,更新reward function,遵循同样的原则,反复迭代,最终学到reward function使得actor与expert得到同样高分。
reward function:如果是线性的reward,保证收敛。或者可以使用NN,输入为trajectory,输出一个R;或者输入(s,a),输出r,最后汇总得到R。
 image.png
image.png
说明:如果actor是generator,reward function是discriminator,则整个框架就是GAN!

优点:不需要太多的training data
应用:学习不同expert开车,且能学习每个expert开车不同风格;人示范训练机器人(手把手,机器处于s的第一视角);Chat-bot(使用maximum likelihood相当于behavior cloning,这是不够的!;SeqGAN方式相对于IRL)
Third Person IL:使用domain adversial training (抽取有用的信息)+ IL,机器看人的行为学习(机器学习视角为第三视角)。