Hadoop环境搭建(单机)
一、环境准备
操作系统:CentOS-6.5-x86_64-minimal.iso
安装包:

百度云:
系统安装,和静态ip配置,和实现SSH免密登录示例,看前面的文章:
https://blog.csdn.net/xingkongtianma01/article/category/7680374
https://blog.csdn.net/xingkongtianma01/article/category/7680389
关闭防火墙:
先执行 命令: service iptables stop (临时生效)
再执行 命令:chkconfig iptables off (永久生效)
(如果不关闭防火墙,就需要 多次开放专用的端口,配置文件:/etc/sysconfig/iptables )
为了方便管理,更改下主机名HOSTNAME,可以不改(主机名称更改之后,要重启(reboot)才会生效)

改完主机名之后,要添加IP和主机名的映射关系(如果在配置文件中使用主机名,映射必须有)

二、服务器配置
1.在/usr目录下创建安装包存放目录
![]()
2.将jdk和hadoop 的安装包 导入进来
3.安装JDK:
输入命令:java -version,查看是否安装了JDK,如果安装了,但版本不适合的话,需要先卸载,再执行命令(rpm -ivh jdk-8u51-linux-x64.rpm),安装我们的JDK
4.配置环境变量:
执行如下命令:
![]()
在最后位置添加 JAVA_HOME JRE_HOME CLASSPATH PATH 的配置

export JAVA_HOME=/usr/java/jdk1.8.0_51/
export JRE_HOME=/usr/java/jdk1.8.0_51//jre
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar:$JRE_HOME/lib
PATH=$PATH:$JAVA_HOME/bin:$JRE_HOME/bin
export PATH编辑完之后,执行命令 source /etc/profile 使配置生效
输入命令:java -version 查看刚刚的JDK配置是否生效
5.1 安装HADOOP:
解压hadoop的安装包
![]()
创建一个hadoop文件夹
![]()
将刚刚解压的hadoop安装文件夹移动到hadoop文件夹中并重命名
![]()
再执行如下命令:
![]()
在最后位置添加 HADOOP 的相关配置

export HADOOP_HOME=/usr/soft2019/hadoop/hadoop3.1
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
PATH=$PATH:$HADOOP_HOME/bin
export PATH编辑完之后,执行命令 source /etc/profile 使配置生效
5.2 在root目录下建立一些文件夹
mkdir /root/hadoop
mkdir /root/hadoop/tmp
mkdir /root/hadoop/var
mkdir /root/hadoop/dfs
mkdir /root/hadoop/dfs/name
mkdir /root/hadoop/dfs/data6.1 切换到 /usr/soft2019/hadoop/hadoop3.1/etc/hadoop/
![]()
6.2 修改 core-site.xml
执行命令 vi core-site.xml,在
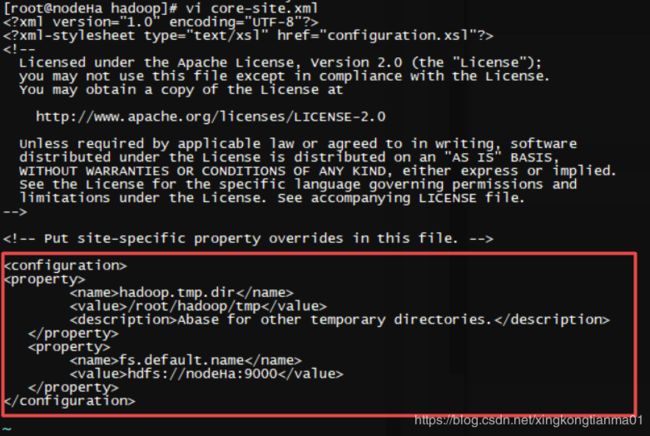
hadoop.tmp.dir
/root/hadoop/tmp
Abase for other temporary directories.
fs.default.name
hdfs://nodeHa:9000
nodeHa就是我们前面配置的HOSTNAME
6.3 修改 hadoop-env.sh
执行命令 vi hadoop-env.sh,将${JAVA_HOME} 修改为自己的JDK路径

6.4 修改 hdfs-site.xml
执行命令 vi hdfs-site.xml,在
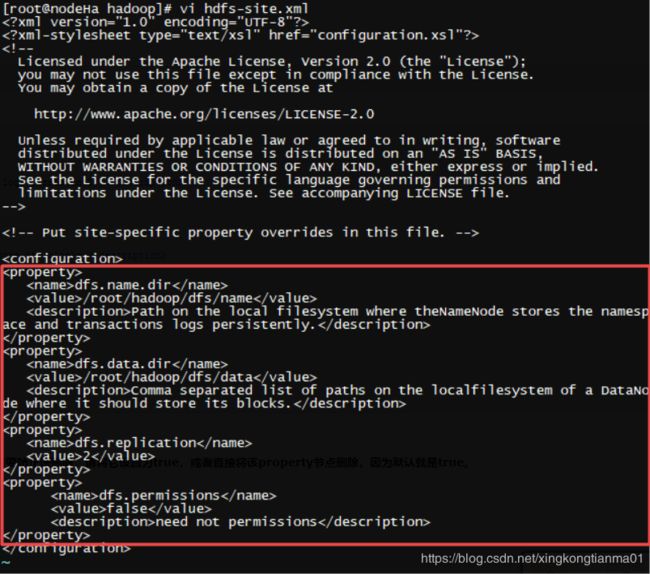
dfs.name.dir
/root/hadoop/dfs/name
Path on the local filesystem where theNameNode stores the namesp
ace and transactions logs persistently.
dfs.data.dir
/root/hadoop/dfs/data
Comma separated list of paths on the localfilesystem of a DataNo
de where it should store its blocks.
dfs.replication
2
dfs.permissions
false
need not permissions
6.5 修改 mapred-site.xml
执行命令 vi mapred-site.xml,在

mapred.job.tracker
nodeHa:9001
mapred.local.dir
/root/hadoop/var
mapreduce.framework.name
yarn
到此 Hadoop 的单机模式的配置就完成了。
7.1 切换到 /usr/soft2019/hadoop/hadoop3.1/bin/
![]()
执行命令 ./hadoop namenode -format ,初始化hadoop
7.2 执行命令 jps 查看目前启动的进程
![]()
未启动hadoop,所以没有hadoop相关的进程
8.1 切换到 /usr/soft2019/hadoop/hadoop3.1/sbin/
![]()
8.2 修改 start-dfs.sh
执行命令 vi start-dfs.sh,在前面 添加如下代码
 、
、
HDFS_DATANODE_USER=root
HADOOP_SECURE_DN_USER=hdfs
HDFS_NAMENODE_USER=root
HDFS_SECONDARYNAMENODE_USER=root执行命令 ./start-dfs.sh 启动HDFS
8.3 修改 start-yarn.sh
执行命令 vi start-yarn.sh,在前面 添加如下代码
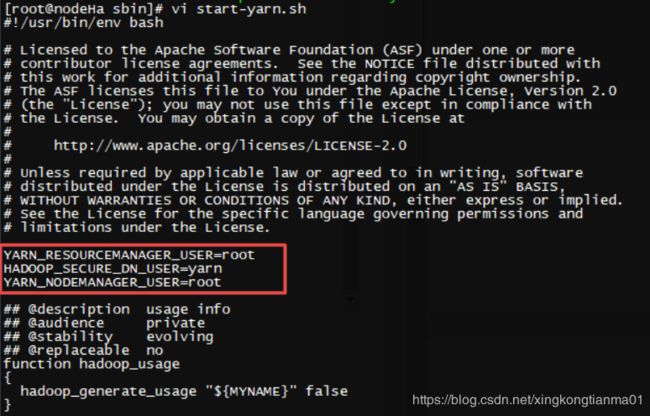
执行命令 ./start-yarn.sh 启动YARN
(或者不执行 ./start-dfs.sh 和 ./start-yarn.sh 命令,而是直接执行命令 ./start-all.sh 一次性启动多个hadoop相关的进程)
8.4 执行命令 jps 查看目前启动的进程

8.5 在浏览器中输入 http://192.168.1.77:8088/cluster

8.6 在浏览器中输入 http://192.168.1.77:9870
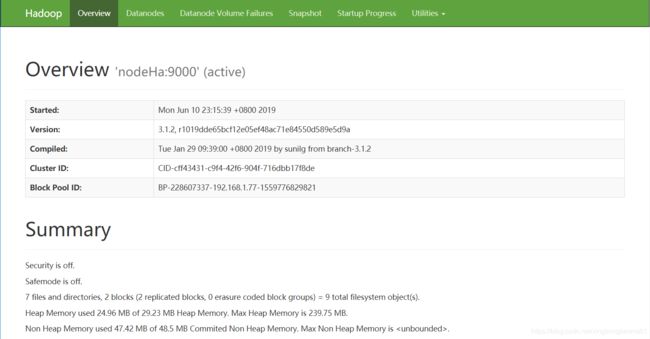
到此。hadoop单机环境搭建就完成了。看似简单,但实际配置起来还是要认真仔细。勤能补拙是良训,我们一起加油!