0.2 Hadoop完全分布式搭建
搭建完全分布式(练习用)
主机相互免秘钥
3台主机分别生成自己的秘钥对
--语法:
ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
将自己的公钥拷贝给别人
--语法:
ssh-copy-id root@192.168.241.211 ~/.ssh/id_rsa.pub
ssh-copy-id root@192.168.241.212 ~/.ssh/id_rsa.pub
ssh-copy-id root@192.168.241.213 ~/.ssh/id_rsa.pub
注意:每个主机都要执行上述3个代码
将对方的地址加入到known_hosts
ssh root@bd1301
ssh root@bd1302
ssh root@bd1303
ssh root@localhost
ssh root@127.0.0.1
--关机拍摄快照
--每个主机都要执行上述代码
配置Hadoop
解压传输来的hardoop的tar包
--语法示例:
tar -zxf hadoop-2.6.5.tar.gz
将解压后的hadoop移动到软件安装目录
--语法示例:
mv hadoop-2.6.5 /opt/sxt/
进入hadoop配置文件目录
--语法示例:
cd /opt/sxt/hadoop-2.6.5/etc/hadoop/
修改hadoop配置文件的JAVE_HOME
--语法示例:
vim hadoop-env.sh
vim mapred-env.sh
vim yarn-env.sh
--修改配置3个.sh文件的JAVA_HOME
--修改为
export JAVA_HOME=/usr/java/jdk1.7.0_67
修改hadoop的xml配置文件
core-sitr.xml
--修改core-site.xml
--语法示例:
vim core-site.xml
--配置示例:
fs.defaultFS</name>
hdfs://bd1301:9000</value>
</property>
hadoop.tmp.dir</name>
/var/sxt/hadoop/full</value>
</property>
--如果此时存在就将其删除/var/sxt/hadoop/full
hdfs-site.xml
--修改hdfs-site.xml
--语法示例:
vim hdfs-site.xml
--配置示例:
dfs.namenode.secondary.http-address</name>
bd1302:50090</value>
</property>
dfs.namenode.secondary.https-address</name>
bd1302:50091</value>
</property>
dfs.replication</name>
2</value>
</property>
slaves
--修改slaves
--语法示例:
vim slaves
--配置示例:
bd1301
bd1302
bd1303
修改环境变量 并 加载环境变量
--语法示例:
vim /etc/profile
export JAVA_HOME=/usr/java/jdk1.7.0_67
export HADOOP_HOME=/opt/sxt/hadoop-2.6.5
export PATH=$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
--加载环境变量语法示例:
source /etc/profile
拷贝主机1的Hadoop 到主机2和主机3中
--语法示例:
scp -r root@bd1301:/opt/sxt/hadoop-2.6.5/ /opt/sxt/
--在2 3 主机上分别执行一次
拷贝主机1的环境变量到主机2和主机3上并加载环境变量
--语法示例:
scp -r root@bd1301:/etc/profile /etc/profile
source /etc/profile
--主机2和主机3 分别执行上述代码
格式化NameNode节点
--如果存在配置文件要先删除(没有就不用)
--删除语法示例:
rm -rf /etc/sxt/hadoop/
格式化namenode节点
语法示例:
hdfs namenode -format
配置完成 关机拍照
测试
开启集群
--语法:
start-dfs.sh
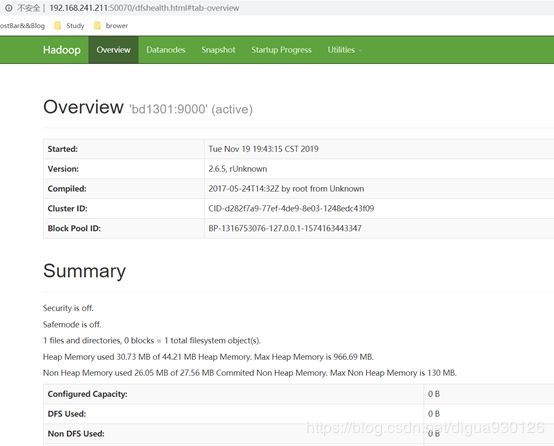
测试集群的active节点 http://192.168.241.211:50070
创建文件夹
/shsxt/gy hdfs dfs -mkdir -p /shsxt/gy
上传hadoop的jar包到 /shsxt/gy/目录
hdfs dfs -put ~/hadoop-2.6.5.tar.gz
/shsxt/gy
查看主机目录
/var/sxt/hadoop/full/dfs/data/current/BP-769381844-
关闭集群
stop-dfs.sh