streaming API Java 二次开发-2
ack机制满足的要求:
1.spout一定要指定messageid 如果没有,无法识别,每个环节都带有tupleid 哪一些id进行异或 通过messageid
2.bolt在发送消息的时候一定要是锚定的方式 将收到的tupleid 和发出去的tupleid 进行异或
3.acker进程必须有
spout开启ack和不开ack:
不启用:
Collector.emit(new Values(word))
启用:
构造一个全局唯一的messageid
如:String messageid =UUID.randomUUID().toString()
Collector.emit(new Values(sentence),messageID)
Bolt ack
1.启用:
Collector.emit(tuple,new Values(sentencd));
Collector.ack();
Collector.fail();
2.启用
bolt继承BaseBasicBolt,会自动锚定tuple并且自动应答,客户端只需要调用collector.emit(new Values(sentence))
不启用
Collector.emit
streaming wordcount
package streaming;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.generated.AlreadyAliveException;
import org.apache.storm.generated.AuthorizationException;
import org.apache.storm.generated.InvalidTopologyException;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import java.util.HashMap;
import java.util.Map;
import java.util.Random;
public class wordcount {
public static class DataSpout2 extends BaseRichSpout {
private SpoutOutputCollector collector;
private String datas[] = new String[]{
"hadoop","yarn","mapreduce,yarn,mapreduce","yarn,yarn,hadoop","mapreduce,yarn,mapreduce","hadoop,yarn,mapreduce","mapreduce,hadoop,mapreduce","yarn,yarn,mapreduce"
};
@Override
public void open(Map map, TopologyContext topologyContext, SpoutOutputCollector spoutOutputCollector) {
this.collector=spoutOutputCollector;
}
@Override
public void nextTuple() {
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
// 取任意一行的数据
this.collector.emit(new Values(datas[new Random().nextInt(datas.length)]));
}
@Override
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
outputFieldsDeclarer.declare(new Fields("s"));
}
}
public static class SplitBolt extends BaseRichBolt{
private OutputCollector collector;
@Override
public void prepare(Map map, TopologyContext topologyContext, OutputCollector outputCollector) {
this.collector=outputCollector;
}
@Override
public void execute(Tuple tuple) {
String[] words=tuple.getStringByField("s").split(",");
for (String word : words){
// 将word和1 两个数据值发给下游组件
this.collector.emit(new Values(word));
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
outputFieldsDeclarer.declare(new Fields("word"));
}
}
public static class CountBolt extends BaseRichBolt{
private HashMap<String, Integer> map=new HashMap<>();
@Override
public void prepare(Map map, TopologyContext topologyContext, OutputCollector outputCollector) {
}
@Override
public void execute(Tuple tuple) {
// 获取单词
String word =tuple.getStringByField("word");
if (map.containsKey(word))
{
map.put(word,map.get(word)+1);//getword 得到的是值
}
else {
map.put(word,1);
}
System.out.println(map);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
}
}
public static void main(String[] args) throws InvalidTopologyException, AuthorizationException, AlreadyAliveException {
TopologyBuilder builder =new TopologyBuilder();
// 运行dataSpout组件 需要3个线程运行
builder.setSpout("dataSpout",new DataSpout2(),3);
builder.setBolt("splitBolt",new SplitBolt(),3).shuffleGrouping("dataSpout");
builder.setBolt("countBolt",new CountBolt(),3).shuffleGrouping("splitBolt");
// 两种部署方式
// 1.本地
// 2.集群
Config config =new Config();
config.setNumWorkers(3);//设置进程数
if (args!=null&&args.length>0){
StormSubmitter.submitTopology(args[0],config,builder.createTopology());
}
else{
LocalCluster localCluster =new LocalCluster();
localCluster.submitTopology("wordcount",config,builder.createTopology());
}
}
}
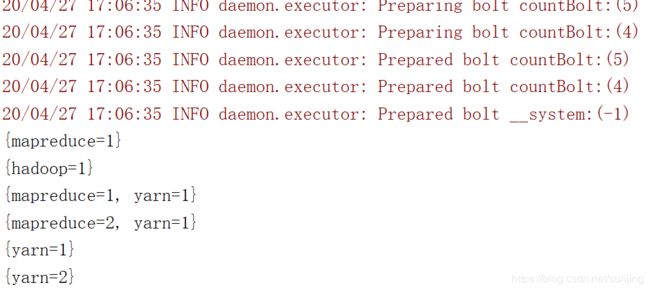
运行结果: