HADOOP:HIVE常用知识总结
HIVE简介
hive (数据仓库工具):hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。 其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。Hive 没有专门的数据格式。 Hive 可以很好的工作在 Thrift 之上,控制分隔符,也允许用户指定数据格式。
注:thrift是一个软件框架,用来进行可扩展且跨语言的服务的开发。它结合了功能强大的软件堆栈和代码生成引擎,以构建在 C++, Java, Go,Python, PHP, Ruby, Erlang, Perl, Haskell, C#, Cocoa, JavaScript, Node.js, Smalltalk, and OCaml 这些编程语言间无缝结合的、高效的服务。
适用场景
Hive 构建在基于静态批处理的Hadoop 之上,Hadoop 通常都有较高的延迟并且在作业提交和调度的时候需要大量的开销。因此,Hive 并不能够在大规模数据集上实现低延迟快速的查询,例如,Hive 在几百MB 的数据集上执行查询一般有分钟级的时间延迟。因此,Hive 并不适合那些需要低延迟的应用,例如,联机事务处理(OLTP)。Hive 查询操作过程严格遵守Hadoop MapReduce 的作业执行模型,Hive 将用户的HiveQL 语句通过解释器转换为MapReduce 作业提交到Hadoop 集群上,Hadoop 监控作业执行过程,然后返回作业执行结果给用户。Hive 并非为联机事务处理而设计,Hive 并不提供实时的查询和基于行级的数据更新操作。Hive 的最佳使用场合是大数据集的批处理作业,例如,网络日志分析。
基础操作
hive --help //帮助信息 变量和属性:–define key=value 实际上和 –hivevar key=value 是等价的 
在CLI中,可以使用set命令替换显示或者修改变量值。
set env:HOME //显示变量
--define foo=bar //定义
set foo //显示变量
foo=bar //output
set hivevar:foo
hivevar:foo=bar //输出信息
set hivevar:foo=bar2
set hivevar:foo
hivevar:foo=bar2 //输出信息
describe k_table //显示表的信息
hive -e "select * from k_test" //一次性执行语句,执行完就退出 -e
hive -S ..... //-S开启静默模式
hive -f /path/to/file/xxx.hql //开启 -f 执行指定文件中的语句
source /path/to/file/xxx.hql //在hive中用source命令来执行脚本
//hive启动的时候会首先执行用户目录下的.hiverc 文件,比如说在.hiverc增加一些参数设置,增加jar包等操作
!echo "Hello hive" //hive在不退出的情况下就可以执行linux 命令,在前面加上 !
dfs -ls ~~~ //在hive中执行dfs命令
-- //hive脚本进行注释的方式
数据类型和文件格式
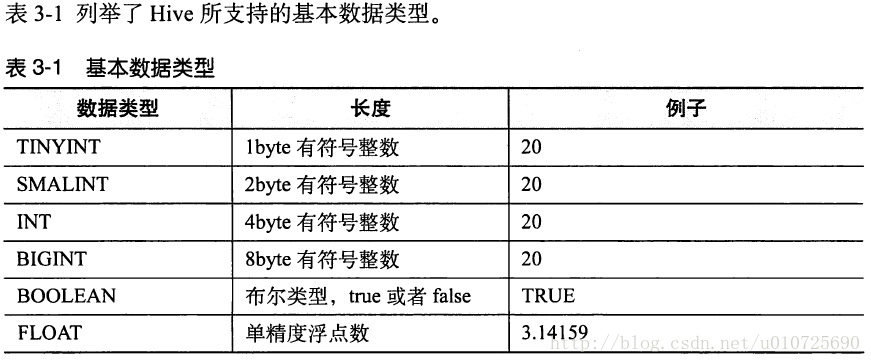
基本数据类型

复合数据类型

:: 注::
Struct 内可以声明为不同类型的字段
Array 内必须是同种类型的
Map 即字典 ,key.value操作创建一个employee表
create table employee(
name STRING,
salary FLOAT,
subord ARRAY,
ded MAPFLOAT >,
address STRUCTINT>
) 文本文件数据编码
hive 使用术语 field来替换默认分隔符的字符 
例如,创建一个表,定义表数据按照逗号分隔
create table employee(
name STRING,
salary FLOAT,
subord ARRAY,
ded MAPFLOAT >,
address STRUCTINT>
)
row format delimited fields terminated by ','; -- \t 为制表键 hive文件存储格式包括以下几类:
1、TEXTFILE
2、SEQUENCEFILE
3、RCFILE
4、ORCFILE(0.11以后出现)
其中TEXTFILE为默认格式,建表时不指定默认为这个格式,导入数据时会直接把数据文件拷贝到hdfs上不进行处理;SEQUENCEFILE,RCFILE,ORCFILE格式的表不能直接从本地文件导入数据,数据要先导入到textfile格式的表中, 然后再从表中用insert导入SequenceFile,RCFile,ORCFile表中。
一、TEXTFILE
默认格式,数据不做压缩,磁盘开销大,数据解析开销大。
可结合Gzip、Bzip2使用(系统自动检查,执行查询时自动解压),但使用这种方式,hive不会对数据进行切分,
从而无法对数据进行并行操作。
举例:
//创建一张testfile_table表,格式为textfile。
create table if not exists testfile_table(
site string, url string, pv bigint, label string
)
row format delimited fields terminated by '\t' stored as textfile; --stored 关键字指定格式
load data local inpath '/app/weibo.txt' overwrite into table textfile_table;
--插入数据操作:
set hive.exec.compress.output=true; --指定压缩
set mapred.output.compress=true; --指定压缩
set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec; --指定压缩
set io.compression.codecs=org.apache.hadoop.io.compress.GzipCodec; --指定压缩
insert overwrite table textfile_table select * from textfile_table; --插入数据二、SEQUENCEFILE
SequenceFile是Hadoop API提供的一种二进制文件支持,其具有使用方便、可分割、可压缩的特点。
SequenceFile支持三种压缩选择:NONE,RECORD,BLOCK。Record压缩率低,一般建议使用BLOCK压缩。
示例:
create table if not exists seqfile_table(
site string,
url string,
pv bigint,
label string
)
row format delimited
fields terminated by '\t'
stored as sequencefile;
插入数据操作:
set hive.exec.compress.output=true;
set mapred.output.compress=true;
set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec;
set io.compression.codecs=org.apache.hadoop.io.compress.GzipCodec;
SET mapred.output.compression.type=BLOCK; --指定压缩选择
insert overwrite table seqfile_table select * from textfile_table;三、RCFILE
RCFILE是一种行列存储相结合的存储方式。首先,其将数据按行分块,保证同一个record在一个块上,避免读一个记录需要读取多个block。其次,块数据列式存储,有利于数据压缩和快速的列存取。
RCFILE文件示例:
create table if not exists rcfile_table(
site string,
url string,
pv bigint,
label string
)
row format delimited
fields terminated by '\t'
stored as rcfile;
插入数据操作:
set hive.exec.compress.output=true;
set mapred.output.compress=true;
set mapred.output.compression.codec=org.apache.hadoop.io.compress.GzipCodec;
set io.compression.codecs=org.apache.hadoop.io.compress.GzipCodec;
insert overwrite table rcfile_table select * from textfile_table;四、ORCFILE 同样
五、再看TEXTFILE、SEQUENCEFILE、RCFILE三种文件的存储情况:
[hadoop@node3 ~]$ hadoop dfs -dus /user/hive/warehouse/*
hdfs://node1:19000/user/hive/warehouse/hbase_table_1 0
hdfs://node1:19000/user/hive/warehouse/hbase_table_2 0
hdfs://node1:19000/user/hive/warehouse/orcfile_table 0
hdfs://node1:19000/user/hive/warehouse/rcfile_table 102638073
hdfs://node1:19000/user/hive/warehouse/seqfile_table 112497695
hdfs://node1:19000/user/hive/warehouse/testfile_table 536799616
hdfs://node1:19000/user/hive/warehouse/textfile_table 107308067
[hadoop@node3 ~]$ hadoop dfs -ls /user/hive/warehouse/*/
-rw-r--r-- 2 hadoop supergroup 51328177 2014-03-20 00:42 /user/hive/warehouse/rcfile_table/000000_0
-rw-r--r-- 2 hadoop supergroup 51309896 2014-03-20 00:43 /user/hive/warehouse/rcfile_table/000001_0
-rw-r--r-- 2 hadoop supergroup 56263711 2014-03-20 01:20 /user/hive/warehouse/seqfile_table/000000_0
-rw-r--r-- 2 hadoop supergroup 56233984 2014-03-20 01:21 /user/hive/warehouse/seqfile_table/000001_0
-rw-r--r-- 2 hadoop supergroup 536799616 2014-03-19 23:15 /user/hive/warehouse/testfile_table/weibo.txt
-rw-r--r-- 2 hadoop supergroup 53659758 2014-03-19 23:24 /user/hive/warehouse/textfile_table/000000_0.gz
-rw-r--r-- 2 hadoop supergroup 53648309 2014-03-19 23:26 /user/hive/warehouse/textfile_table/000001_1.gz总结:相比TEXTFILE和SEQUENCEFILE,RCFILE由于列式存储方式,数据加载时性能消耗较大,但是具有较好的压缩比和查询响应。数据仓库的特点是一次写入、多次读取,因此,整体来看,RCFILE相比其余两种格式具有较明显的优势
数据定义
数据库常用操作
//查看所有的数据库
hive> show databases ;
//使用数据库default
hive> use default;
//查看数据库信息
hive > describe database default;
OK
db_name comment location owner_name owner_type parameters
default Default Hive database hdfs://hadoop1:8020/user/hive/warehouse public ROLE
Time taken: 0.042 seconds, Fetched: 1 row(s)
//显示地展示当前使用的数据库
hive> set hive.cli.print.current.db=true;
hive(default)>
//创建数据库命令
hive (default)> create database test comment "描述信息";
OK
Time taken: 10.128 seconds
//切换当前的数据库
hive (default)> use test;
OK
Time taken: 0.031 seconds
hive (test)>
//删除数据库
删除数据库的时候,不允许删除有数据的数据库,如果数据库里面有数据则会报错。如果要忽略这些内容,则在后面增加CASCADE关键字,则忽略报错,删除数据库。
hive> DROP DATABASE DbName CASCADE(可选);
hive> DROP DATABASE IF EXISTS DbName CASCADE;
//修改数据库
alter database test set ....
数据表常用操作
//查看当前DB有啥表
hive> SHOW TABLES IN DbName;
hive> SHOW TABLES IN liguodong;
OK
tab_name
Time taken: 0.165 seconds
//也可以使用正则表达式 hive> SHOW TABLES LIKE 'h*';
hive (default)> SHOW TABLES LIKE '*all*' ;
OK
tab_name
addressall_2015_07_09
Time taken: 0.039 seconds, Fetched: 1 row(s)
//获得表的建表语句
hive (default)> show create table address1_2015_07_09;
OK
createtab_stmt
CREATE TABLE `address1_2015_07_09`(
`addr1` bigint)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs://nameservice1/user/hive/warehouse/address1_2015_07_09'
TBLPROPERTIES (
'COLUMN_STATS_ACCURATE'='true',
'numFiles'='1',
'numRows'='0',
'rawDataSize'='0',
'totalSize'='4',
'transient_lastDdlTime'='1436408451')
Time taken: 0.11 seconds, Fetched: 17 row(s)
//创建表
CREATE [TEMPORARY] [EXTERNAL] TABLE [IF NOT EXISTS] [db_name.]table_name -- (Note: TEMPORARY available in Hive 0.14.0 and later)
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] --分区
[CLUSTERED BY (col_name, col_name, ...) [SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[SKEWED BY (col_name, col_name, ...) -- (Note: Available in Hive 0.10.0 and later)]
ON ((col_value, col_value, ...), (col_value, col_value, ...), ...)
[STORED AS DIRECTORIES]
[
[ROW FORMAT row_format]
[STORED AS file_format]
| STORED BY 'storage.handler.class.name' [WITH SERDEPROPERTIES (...)] -- (Note: Available in Hive 0.6.0 and later)
]
[LOCATION hdfs_path]
[TBLPROPERTIES (property_name=property_value, ...)] -- (Note: Available in Hive 0.6.0 and later)
[AS select_statement]; -- (Note: Available in Hive 0.5.0 and later; not supported for external tables)
//举个例子
create table employee(
name STRING,
salary FLOAT,
subord ARRAY,
ded MAPFLOAT >,
address STRUCTINT>
)
row format delimited fields terminated by '\t' lines terminated by '\n' stored as textfile; --指定字段分隔符和行分隔符 指定文件存储格式
//加载数据
hive (default)> load data local inpath ‘/liguodong/hivedata/datatest’ overwrite into table testtable;
hive (default)> load data local inpath ‘/liguodong/hivedata/datatest’ into table testtable; --如果没有使用overwrite,则会再拷贝一份数据,不会覆盖原来的数据。
//查找表数据
--注意:select * 不执行mapreduce,只进行一个本地的查询。
--而select 某个字段 生成一个job,执行mapreduce。
select * from employees;
select * from employees limit 10;
//删除表
--内部表删除,会连同hdfs存储的数据一同删除,而外部表删除,只会删除外部表的元数据信息。
hive (default)> drop table testtable;
OK
Time taken: 10.283 seconds
hive (default)> drop table testexttable;
OK
Time taken: 0.258 seconds
//Hive建表的其他方式
--有一个表,创建另一个表(只是复制了表结构,并不会复制内容。) 不需要执行mapreduce
create table test3 like test2;
--从其他表查询,再创建表(复制表结构的同时,把内容也复制过来了) 需要执行mapreduce
create table test2 as select name,addr from test1;
//查看表的详细信息
describe formatted/extended tableName
create EXTERNAL tableName --创建扩展表(外部表)
row format delimited fields terminated by '\t' --字段分隔符
//创建分区表
create table partitionetest(
name STRING,
country STRING,
state STRING
)
partitioned by (country STRING ,state STRING)
当用where 来进行分区过滤的时候,这些叫做分区过滤器
set hive.mapred.mode=strict --设置为严格,默认是 nostrict,这样对分区表进行查询而where字句没有分区过滤的话,就会被禁止提交这个任务查看表分区信息
show partitions employee; --查看employee表中的所有分区
show partitions employee(country='US',state='AK'); --查看指定分区的信息创建一个外部表的分区
create external table if not exists log_message (
hms INT,
severity STRING,
sever STRING,
process_id INT,
message STRING
)
partitioned by (year int ,month int,day int)
row format delimited fields terminated by '\t';增加一个表的分区
alter table log_message add if not exists
partition(year=2012,month=1,day=2)
location 'hdfs://master_sever/data/log_message/2012/01/02'
partition(year=2012,month=1,day=3)
location 'hdfs://master_sever/data/log_message/2012/01/03'
...
修改一个表的分区
alter table log_message partition(year=2012,month=1,day=2)
set location 'hdfs://master_sever/data/log_message/2012/01/02'
--这个命令不会将旧的路径转移走,也不会删除旧的数据删除分区
alter table log_message drop if exists partition(year=2012,month=1,day=2)修改列信息
alter table log_message
change column hms hours_minutes INT
comment 'aaaaaaaaaaaa' --注释
after serveri --移动到serveri之后增加列信息
alter table log_message add columns (
.... --增加的列信息
....
)删除或者替换列
alter table log_message change columns (
.... --修改的列信息
....数据操作
数据操作能力是大数据分析至关重要的能力。数据操作主要包括:更改(exchange),移动(moving),排序(sorting),转换(transforming)。Hive提供了诸多查询语句,关键字,操作和方法来进行数据操作。
一、 数据更改 数据更改主要包括:LOAD, INSERT, IMPORT, and EXPORT. 1. LOAD DATA load关键字的作用是将数据移动到hive中。如果是从HDFS加载数据,则加载成功后会删除源数据;如果是从本地加载,则加载成功后不会删除源数据。
LOAD DATA LOCAL INPATH '/apps/ca/yanh/employee_hr.txt'
OVERWRITE INTO TABLE k_test
PARTITION (country='US',state='CA'); --装载数据到k_test表中,PARTITION 可以省略注1:在指令中LOCAL关键字用于指定数据从本地加载,如果去掉该关键字,默认从HDFS进行加载! OVERWRITE关键字指定使用覆盖方式进行加载数据,否则使用附加方式进行加载。
注2:如果数据加载到分区表,则必须指定分区列。
INSERT 同RDBMS一样,Hive也支持从其他hive表提取数据插入到指定表,使用INSERT关键字。INSERT操作是Hive数据处理中最常用的将已有数据填充进指定表操作。在Hive中,INSERT可以和OVERWRITE一起使用实现覆盖插入,可以进行多表插入,动态分区插入以及提取数据至HDFS或本地。
CREATE TABLE ctas_employee AS SELECT * FROM employee; TRUNCATE TABLE employee; --删除employee中的数据,保留表结构
INSERT INTO TABLE employee SELECT * FROM ctas_employee; --使用INSERT关键字
INSERT OVERWRITE TABLE employees
PARTITION (country='US',state='CA')
select * from employees_bak re where re.country='US' and re.state='CA';--OVERWRITE 会将之前分区的内容覆盖掉
//多次插入数据
from stom_employee re
insert OVERWRITE TABLE employees
PARTITION (country='US',state='CA')
select * from where re.country='US' and re.state='CA';
insert OVERWRITE TABLE employees
PARTITION (country='US',state='CB')
select * from where re.country='US' and re.state='CB';
insert OVERWRITE TABLE employees
PARTITION (country='US',state='CC')
select * from where re.country='US' and re.state='CC';动态分区插入
insert OVERWRITE TABLE employees
PARTITION (country='US',state)
select ...,se.coun,se.st
from sta_employee se
where se.country='US'; --根据state 动态分区插入导出数据
hadoop fs -cp source_path target_path --文件格式符合的时候直接复制就可以
INSERT OVERWRITE LOCAL DIRECTORY '/tmp/test/a'
select ...; --这种方式会将字段序列化成字符串写入文件中查询
select * from tableName r where r....; --这里查询和sql类似,符号 函数,limit 别名 嵌套等方面。
select name,salary
case
when salary < 5000 then ...
when salary > 5000 then ...
END AS BRUCKET FROM employee;JOIN:hive只支持等值连接。
**类型转换:**case()
数据排序 数据排序主要包括:ORDER, and SORT. 该操作同样经常使用,以便生成已排序表从而进行后面的包括top N, maximum, minimum等取值操作。 主要操作包括ORDER BY (ASC|DESC)、SORT BY(ASC|DESC)、DISTRIBUTE BY、CLUSTER BY
DISTRIBUTE BY :该操作类似于RDBMS中的GROUP BY,根据制定的列将mapper的输出分组发送至reducer,而不是根据partition来分组数据。 注:如果使用了SORT BY,那么必须在DISTRIBUTE BY之后,且要分发的列必须出现在已选择的列中(因为SORT BY的性质)。
CLUSTER BY: CLUSTER BY类似于DISTRIBUTE BY和SORT BY的组合作用(作用于相同列),但不同于ORDER BY的是它仅在每个reducer进行排序,而不是全局排序,且不支持ASC和DESC。如果要实现全局排序,可以先进行CLUSTER BY然后再ORDER BY。
模式设计
分区,按照年 月 日 或者一些静态的字段来进行,这样查询的时候在where中指定条件的时候就指定这些分区的信息,会优化查询速度
分桶技术是将数据集分解成更容易管理的若干部分的另一个技术。例如一级分区是天,二级分区是ID,这样会由于ID过多导致出现问题,这种情况下,就可以用天作为分区 ID进行桶操作。
使用列存储表
总是使用压缩