ASP.NET Core环境Web Audio API+SingalR+微软语音服务实现web实时语音识别
处于项目需要,我研究了一下web端的语音识别实现。目前市场上语音服务已经非常成熟了,国内的科大讯飞或是国外的微软在这块都可以提供足够优质的服务,对于我们工程应用来说只需要花钱调用接口就行了,难点在于整体web应用的开发。最开始我实现了一个web端录好音然后上传服务端进行语音识别的简单demo,但是这种结构太过简单,对浏览器的负担太重,而且响应慢,交互差;后来经过调研,发现微软的语音服务接口是支持流输入的连续识别的,因此开发重点就在于实现前后端的流式传输。
参考这位国外大牛写的博文Continuous speech to text on the server with Cognitive Services,开发的新demo可以达到理想的效果,在网页上点击“开始录音”开启一次录音,对着麦克风随意说话,网页会把实时的音频数据传递给后端,后端实时识别并返回转换结果,点击“结束录音”停止。
1 整体结构
整体结构图如下所示,在web端需要使用HTML5的Web Audio API接收麦克风输入的音频流,进行适量的处理后实时传递给服务端;web与服务端之间的音频流交互通过SignalR来实现;具体的语音识别通过调用微软语音服务实现。
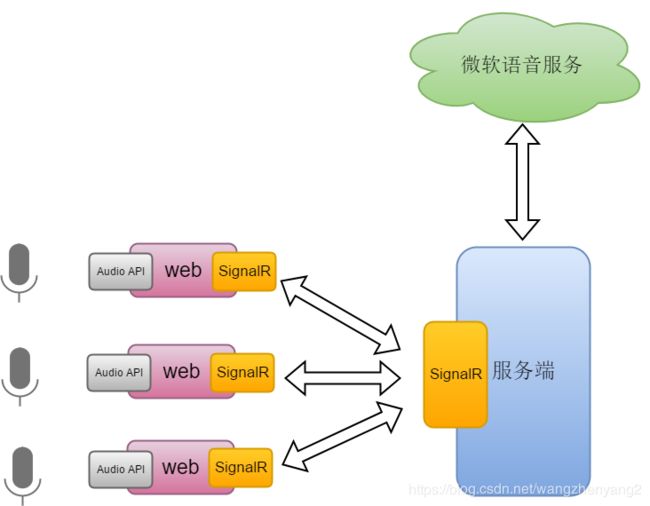 该web实时语音识别demo可以实现下面的功能:
该web实时语音识别demo可以实现下面的功能:
- 可以通过网页传入麦克风音频
- 网页可以实时显示语音识别结果,包括中间结果和最终结果
- 可以保存每一次的录音,并且录音时长可以非常长
- 支持多个web同时访问,服务端管理多个连接
2 技术栈
- ASP.NET Core开发
服务端使用较新的 ASP.NET Core技术开发,不同于传统的 ASP.NET,ASP.NET Core更加适合前后台分离的web应用,我们会用 ASP.NET Core框架开发REST API为前端服务。如果不去纠结 ASP.NET Core的框架结构,实际的开发和之前的.NET应用开发没什么不同,毕竟只是底层结构不同。 - JavaScript或TypeScript开发
前端的逻辑用JavaScript开发,具体什么框架无所谓。我是用angular开发的,因此严格的说开发语言是TypeScript了。至于网页的具体内容,熟悉html、CSS就行了。 - Web Audio API的使用和基本的音频处理的知识
采集和上传麦克风音频都在浏览器进行,对此需要使用HTML5标准下的Web API进行音频流的获取,使用音频上下文(AudioContext)实时处理音频流。具体处理音频流时,需要了解一点基本的音频知识,例如采样率、声道等参数,WAV文件格式等等。
相关资料:
HTML5网页录音和压缩
HTML5 getUserMedia/AudioContext 打造音谱图形化
Capturing Audio & Video in HTML5 - 微软语音认知服务
微软的语音识别技术是微软云服务中的成员之一,相比于国内比较熟知的科大讯飞,微软的优势在于契合 .NET Core技术栈,开发起来非常方便,支持连续识别,支持自定义训练,并且支持容器部署,这对于那些对上传云服务有安全顾虑的用户更是好消息。当然价格考虑就得看具体情况了,不过如果你有Azure账号的话,可以开通标准版本的语音识别服务,这是免费的,只有时间限制;没有账号的话可以使用微软提供的体验账号体验一个月。
官方文档: Speech Services Documentation - SignalR的使用
要实现web和服务端的流通信,就必须使用web socket一类的技术来进行长连接通信,微软的SignalR是基于web socket的实时通信技术,如果我们的web需要和服务端保持长连接或者需要接收服务端的消息推送,使用该技术可以方便的实现。需要注意的是 ASP.NET SignalR and ASP.NET Core SignalR是有区别的,在 .NET Core环境下需要导入的是SignalR Core
官方文档: Introduction to ASP.NET Core SignalR
Angular下调用SignalR: How to Use SignalR with .NET Core and Angular - 字节流和异步编程的概念
参考这篇博文Continuous speech to text on the server with Cognitive Services,在服务端需要自己实现一个特别的字节流来作为语音服务的数据源,因为语音服务在默认的字节流上一旦读取不到数据就会自动结束。在具体的实现中,将会用到一些信号量来进行读取控制。
3 后端细节
3.1 获取微软语音识别服务
如果没有Azure账号,可以用微软提供的试用账号:
有Azure账号的话,在Azure门户里开通语音识别服务
创建的时候可以选择F0类型的收费标准,这种是免费的:
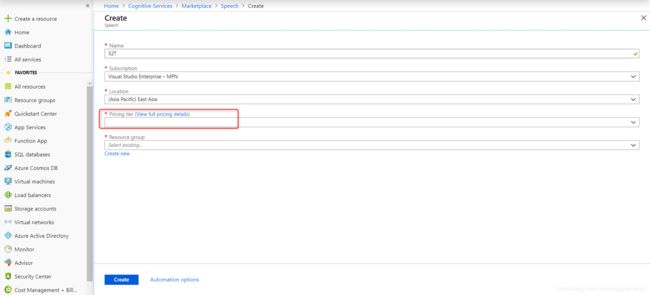
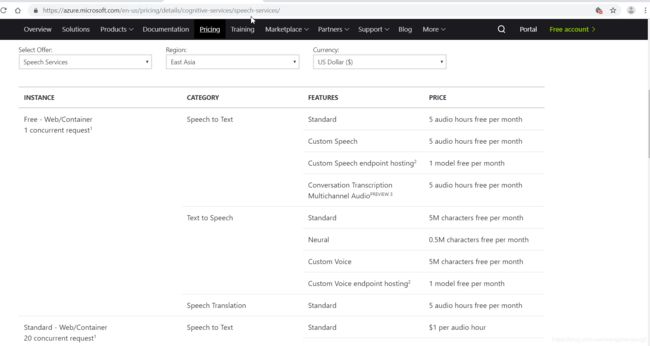
开通成功后,得到API Key的值,我们调用服务的时候传入这个参数;另一个参数是region,这个要看你创建服务的时候选择的区域,如果你选择的是East Asia,这个参数就是“eastasia”,如果用的是测试账号,统一用“westus”。
3.2 创建并配置ASP.NET Core API项目
新建一个 ASP.NET Core API项目
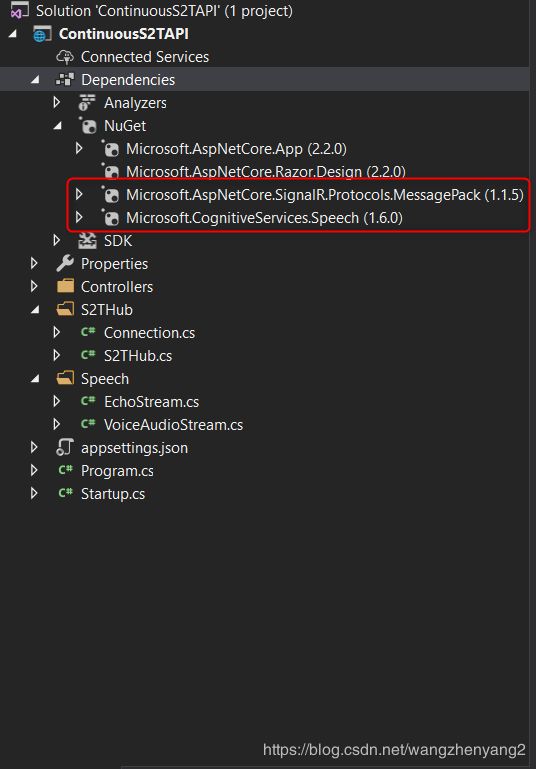
通过Nuget管理器添加语音服务和SignalR相关的包。Microsoft.CognitiveServices.Speech是微软语音服务包,Microsoft.AspNetCore.SignalR.Protocols.MessagePack用于SignalR中的MessagePack协议通信。
在Startup.cs中为 ASP.NET Core项目注入并配置SignalR服务:
public void ConfigureServices(IServiceCollection services)
{
services.AddCors(options =>
{
options.AddPolicy("CorsPolicy",
builder => builder.WithOrigins("http://localhost:4200")
.AllowAnyMethod()
.AllowAnyHeader()
.AllowCredentials());
}); // 跨域请求设置
services.AddSignalR().AddMessagePackProtocol(options =>
{
options.FormatterResolvers = new List()
{
MessagePack.Resolvers.StandardResolver.Instance
};
}); // 允许signalR以MessagePack消息进行通信
services.AddMvc().SetCompatibilityVersion(CompatibilityVersion.Version_2_2);
}
// This method gets called by the runtime. Use this method to configure the HTTP request pipeline.
public void Configure(IApplicationBuilder app, IHostingEnvironment env)
{
if (env.IsDevelopment())
{
app.UseDeveloperExceptionPage();
}
else
{
// The default HSTS value is 30 days. You may want to change this for production scenarios, see https://aka.ms/aspnetcore-hsts.
app.UseHsts();
}
app.UseHttpsRedirection();
app.UseCors("CorsPolicy"); //添加跨域请求服务
app.UseSignalR(routes =>
{
routes.MapHub("/s2thub");
}); //添加SignalR服务并配置路由,访问'/s2thub'将被映射到S2THub对象上
app.UseMvc();
}
3.3 SignalR接口
新建一个S2THub文件夹,将SignalR接口放着里面。先创建一个Connection类,它代表一个客户端连接:
using System;
using System.Collections.Generic;
using System.Linq;
using System.Threading.Tasks;
using Microsoft.CognitiveServices.Speech;
using ContinuousS2TAPI.Speech;
namespace ContinuousS2TAPI.S2THub
{
public class Connection
{
public string SessionId; // 会话ID
public SpeechRecognizer SpeechClient; // 一个语音服务对象
public VoiceAudioStream AudioStream; //代表一个音频流
public List VoiceData; //存储该次会话的音频数据
}
}
然后创建继承自Hub的S2THub类,这个实例化的S2THub对象将会管理客户端的连接
public class S2THub : Hub
{
private static IConfiguration _config;
private static IHubContext _hubContext; //S2THub实例的上下文
private static Dictionary _connections; //维护客户端连接
public S2THub(IConfiguration configuration, IHubContext ctx)
{
if (_config == null)
_config = configuration;
if (_connections == null)
_connections = new Dictionary();
if (_hubContext == null)
_hubContext = ctx;
}
...
...
}
在S2THub类中,需要定义两个供客户端调用的接口AudioStart和ReceiveAudio,客户端首先需要通过调用AudioStart来通知服务端开始一次语音识别会话,接着在接收到实时的音频二进制数据后调用ReceiveAudio接口来将数据发送给服务端。这里会用到一个名为VoiceAudioStream的流对象,这是我们自定义的流对象,具体实现后文给出。
public async void AudioStart()
{
Console.WriteLine($"Connection {Context.ConnectionId} starting audio.");
var audioStream = new VoiceAudioStream(); // 创建一个供语音识别对象读取的数据流
var audioFormat = AudioStreamFormat.GetWaveFormatPCM(16000, 16, 1);
var audioConfig = AudioConfig.FromStreamInput(audioStream, audioFormat);
var speechConfig = SpeechConfig.FromSubscription("your key", "you region"); //使用你自己的key和region参数
speechConfig.SpeechRecognitionLanguage = "zh-CN"; //中文
var speechClient = new SpeechRecognizer(speechConfig, audioConfig);
speechClient.Recognized += _speechClient_Recognized; // 连续识别存在Recognized和Recognizing事件
speechClient.Recognizing += _speechClient_Recognizing;
speechClient.Canceled += _speechClient_Canceled;
string sessionId = speechClient.Properties.GetProperty(PropertyId.Speech_SessionId);
var conn = new Connection()
{
SessionId = sessionId,
AudioStream = audioStream,
SpeechClient = speechClient,
VoiceData = new List()
};
_connections.Add(Context.ConnectionId, conn); //将这个新的连接记录
await speechClient.StartContinuousRecognitionAsync(); //开始连续识别
Console.WriteLine("Audio start message.");
}
public void ReceiveAudio(byte[] audioChunk)
{
//Console.WriteLine("Got chunk: " + audioChunk.Length);
_connections[Context.ConnectionId].VoiceData.AddRange(audioChunk); //记录接收到的音频数据
_connections[Context.ConnectionId].AudioStream.Write(audioChunk, 0, audioChunk.Length);//并将实时的音频数据写入流
}
要将识别的结果返回给客户端,就需要调用客户端的接口实现推送,因此定义一个SendTranscript方法,内部会调用客户端名为IncomingTranscript的接口来推送消息:
public async Task SendTranscript(string text, string sessionId)
{
var connection = _connections.Where(c => c.Value.SessionId == sessionId).FirstOrDefault();
await _hubContext.Clients.Client(connection.Key).SendAsync("IncomingTranscript", text); //调用指定客户端的IncomingTranscript接口
}
在语音服务的识别事件中我们调用SendTranscript方法返回结果:
private async void _speechClient_Canceled(object sender, SpeechRecognitionCanceledEventArgs e)
{
Console.WriteLine("Recognition was cancelled.");
if (e.Reason == CancellationReason.Error)
{
Console.WriteLine($"CANCELED: ErrorCode={e.ErrorCode}");
Console.WriteLine($"CANCELED: ErrorDetails={e.ErrorDetails}");
Console.WriteLine($"CANCELED: Did you update the subscription info?");
await SendTranscript("识别失败!", e.SessionId);
}
}
private async void _speechClient_Recognizing(object sender, SpeechRecognitionEventArgs e)
{
Console.WriteLine($"{e.SessionId} > Intermediate result: {e.Result.Text}");
await SendTranscript(e.Result.Text, e.SessionId);
}
private async void _speechClient_Recognized(object sender, SpeechRecognitionEventArgs e)
{
Console.WriteLine($"{e.SessionId} > Final result: {e.Result.Text}");
await SendTranscript(e.Result.Text, e.SessionId);
}
最后我们重写Hub的OnDisconnectedAsync方法,这个方法会在hub连接断开时调用,可以在该方法内结束识别:
public async override Task OnDisconnectedAsync(Exception exception)
{
var connection = _connections[Context.ConnectionId];
Console.WriteLine($"Voice list length : {connection.VoiceData.Count}");
byte[] actualLength = System.BitConverter.GetBytes(connection.VoiceData.Count);
string rootDir = AppContext.BaseDirectory;
System.IO.DirectoryInfo directoryInfo = System.IO.Directory.GetParent(rootDir);
string root = directoryInfo.Parent.Parent.FullName;
var savePath = $"{root}\\voice{connection.SessionId}.wav";
using (var stream = new System.IO.FileStream(savePath, System.IO.FileMode.Create)) // 保存音频文件
{
byte[] bytes = connection.VoiceData.ToArray();
bytes[4] = actualLength[0];
bytes[5] = actualLength[1];
bytes[6] = actualLength[2];
bytes[7] = actualLength[3];
bytes[40] = actualLength[0];
bytes[41] = actualLength[1];
bytes[42] = actualLength[2];
bytes[43] = actualLength[3]; // 计算并填入音频数据长度
stream.Write(bytes, 0, bytes.Length);
}
await connection.SpeechClient.StopContinuousRecognitionAsync(); //结束识别
connection.SpeechClient.Dispose();
connection.AudioStream.Dispose();
_connections.Remove(Context.ConnectionId); //移除连接记录
Console.WriteLine($"connection : {Context.ConnectionId} closed");
await base.OnDisconnectedAsync(exception);
}
3.4 自定义音频流
SpeechRecognizer对象可以接收一个特殊的流对象PullAudioStreamCallback作为数据源,如果传入了这个对象,SpeechRecognizer会主动从该流对象里读取数据。这个一个虚类,如果你只是给一段音频文件做识别,通过MemoryStream和BinaryStreamReader的简单组合就可以了(可以看微软的官方demo),但是SpeechRecognizer会在流中读取到0个字节后停止识别,在我们的场景中默认的流类型无法满足需求,当没有数据读取到时它们无法block住,PullAudioStreamCallback期望的效果是只有当明确流结束时读取流的Read()方法才返回0。因此需要定义我们自己的音频流对象
首先定义一个继承自MemoryStream的EchoStream, 该流对象会在没有数据进入时进行等待而不是直接返回0
public class EchoStream:MemoryStream
{
private readonly ManualResetEvent _DataReady = new ManualResetEvent(false);
private readonly ConcurrentQueue _Buffers = new ConcurrentQueue();
public bool DataAvailable { get { return !_Buffers.IsEmpty; } }
public override void Write(byte[] buffer, int offset, int count)
{
_Buffers.Enqueue(buffer.Take(count).ToArray());
_DataReady.Set();
}
public override int Read(byte[] buffer, int offset, int count)
{
//Debug.WriteLine("Data available: " + DataAvailable);
_DataReady.WaitOne();
byte[] lBuffer;
if (!_Buffers.TryDequeue(out lBuffer))
{
_DataReady.Reset();
return -1;
}
if (!DataAvailable)
_DataReady.Reset();
Array.Copy(lBuffer, buffer, lBuffer.Length);
return lBuffer.Length;
}
}
然后定义PullAudioStreamCallback对象,作为语音服务的输入源。服务端会把客户端上传的byte[]数据通过Write()方法写入流,而语音服务会调用Read()方法读取数据,可以看到,通过一个ManualResetEvent信号量,使得流对象必须在调用Close()方法之后才会在Read()方法中返回0
public class VoiceAudioStream : PullAudioInputStreamCallback
{
private readonly EchoStream _dataStream = new EchoStream();
private ManualResetEvent _waitForEmptyDataStream = null;
public override int Read(byte[] dataBuffer, uint size) //S2T服务从PullAudioInputStream中读取数据, 读到0个字节并不会关闭流
{
if (_waitForEmptyDataStream != null && !_dataStream.DataAvailable)
{
_waitForEmptyDataStream.Set();
return 0;
}
return _dataStream.Read(dataBuffer, 0, dataBuffer.Length);
}
public void Write(byte[] buffer, int offset, int count) //Client向PullAudioInputStream写入数据
{
_dataStream.Write(buffer, offset, count);
}
public override void Close()
{
if (_dataStream.DataAvailable)
{
_waitForEmptyDataStream = new ManualResetEvent(false); //通过ManualResetEvent强制流的使用者必须调用close来手动关闭流
_waitForEmptyDataStream.WaitOne();
}
_waitForEmptyDataStream.Close();
_dataStream.Dispose();
base.Close();
}
}
4 前端细节
前端是用Angular框架写的,这个Demo我们需要用到SignalR相关的库。使用npm install @aspnet/signalr和npm install @aspnet/signalr-protocol-msgpack安装这两个包,并导入到组件中:
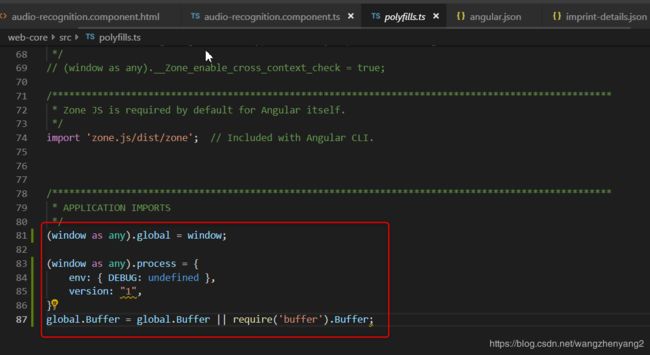
此外在polyfills.ts文件中添加如下代码,否则可能会有浏览器兼容问题
在组件的初始化代码中,初始化Hub对象,并检查当前浏览器是否支持实时音频,目前主要是firefox和chrome支持浏览器流媒体获取。通过this.s2tHub.on('IncomingTranscript', (message) => { this.addMessage(message); });这句代码,给客户端注册了一个IncomingTranscript方法以供服务端调用
constructor(private http: HttpClient) {
this.s2tHub = new signalR.HubConnectionBuilder()
.withUrl(this.apiurl) //apiurl是SignalR Hub的地址,我这里是'https://localhost:5001/s2thub'
.withHubProtocol(new signalRmsgpack.MessagePackHubProtocol())
.configureLogging(signalR.LogLevel.Information)
.build(); // 创建Hub对象
this.s2tHub.on('IncomingTranscript', (message) => {
this.addMessage(message);
}); // 在客户端注册IncomingTranscript接口
}
ngOnInit() {
if (navigator.mediaDevices.getUserMedia) { // 检测当前浏览器是否支持流媒体
this.addMessage('This browser support getUserMedia');
this.supportS2T = true;
} else {
this.addMessage('This browser does\'nt support getUserMedia');
this.supportS2T = false;
}
}
点击"Start"后,启动Hub连接,开始向服务端发送数据。先是调用服务端的AudioStart接口通知服务端开始识别;然后调用ReceiveAudio接口先向服务端发送44字节的wav头数据,语音识别服务目前支持的音频类型是PCM和WAV,16000采样率,单声道,16位宽;最后在startStreaming中开始处理实时音频流。
async startRecord() {
if (!this.supportS2T) {
return;
}
let connectSuccess = true;
if (this.s2tHub.state !== signalR.HubConnectionState.Connected) {
await this.s2tHub.start().catch(err => { this.addMessage(err); connectSuccess = false; } );
}
if (!connectSuccess)
{
return;
}
this.s2tHub.send('AudioStart');
this.s2tHub.send('ReceiveAudio', new Uint8Array(this.createStreamRiffHeader()));
this.startStreaming();
}
private createStreamRiffHeader() {
// create data buffer
const buffer = new ArrayBuffer(44);
const view = new DataView(buffer);
/* RIFF identifier */
view.setUint8(0, 'R'.charCodeAt(0));
view.setUint8(1, 'I'.charCodeAt(0));
view.setUint8(2, 'F'.charCodeAt(0));
view.setUint8(3, 'F'.charCodeAt(0));
/* file length */
view.setUint32(4, 0, true); // 因为不知道数据会有多长,先将其设为0
/* RIFF type & Format */
view.setUint8(8, 'W'.charCodeAt(0));
view.setUint8(9, 'A'.charCodeAt(0));
view.setUint8(10, 'V'.charCodeAt(0));
view.setUint8(11, 'E'.charCodeAt(0));
view.setUint8(12, 'f'.charCodeAt(0));
view.setUint8(13, 'm'.charCodeAt(0));
view.setUint8(14, 't'.charCodeAt(0));
view.setUint8(15, ' '.charCodeAt(0));
/* format chunk length */
view.setUint32(16, 16, true); // 16位宽
/* sample format (raw) */
view.setUint16(20, 1, true);
/* channel count */
view.setUint16(22, 1, true); // 单通道
/* sample rate */
view.setUint32(24, 16000, true); // 16000采样率
/* byte rate (sample rate * block align) */
view.setUint32(28, 32000, true);
/* block align (channel count * bytes per sample) */
view.setUint16(32, 2, true);
/* bits per sample */
view.setUint16(34, 16, true);
/* data chunk identifier */
view.setUint8(36, 'd'.charCodeAt(0));
view.setUint8(37, 'a'.charCodeAt(0));
view.setUint8(38, 't'.charCodeAt(0));
view.setUint8(39, 'a'.charCodeAt(0));
/* data chunk length */
view.setUint32(40, 0, true); // 因为不知道数据会有多长,先将其设为0
return buffer;
}
在startStreaming方法中,首先调用window.navigator.mediaDevices.getUserMedia获取到麦克风输入流,然后创建AudioContext对象,用它创建多个音频处理节点,这些节点依次连接:
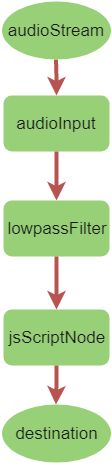
audioInput节点是音频输入节点,以音频流为输入;lowpassFilter节点作为一个滤波节点,对输入音频做低通滤波进行简单的降噪;jsScriptNode节点是主要的处理节点,可以为该节点添加事件处理,每当有数据进入该节点就进行处理和上传;最后是destination节点,它是Web Audio Context终结点,默认情况下会连接到本地的扬声器。
private startStreaming() {
window.navigator.mediaDevices.getUserMedia({
audio: true
}).then(mediaStream => {
this.addMessage('get media stream successfully');
this.audioStream = mediaStream;
this.context = new AudioContext();
this.audioInput = this.context.createMediaStreamSource(this.audioStream); // 源节点
this.lowpassFilter = this.context.createBiquadFilter();
this.lowpassFilter.type = 'lowpass';
this.lowpassFilter.frequency.setValueAtTime(8000, this.context.currentTime); //滤波节点
this.jsScriptNode = this.context.createScriptProcessor(4096, 1, 1);
this.jsScriptNode.addEventListener('audioprocess', event => {
this.processAudio(event);
}); // 处理事件
this.audioInput.connect(this.lowpassFilter);
this.lowpassFilter.connect(this.jsScriptNode);
this.jsScriptNode.connect(this.context.destination);
}).catch(err => {
this.addMessage('get media stream failed');
});
}
在jsScriptNode节点的audioprocess事件中,我们通过降采样、取单通道音频等处理获得正确格式的音频数据,再调用服务端的ReceiveAudio方法上传数据块
private processAudio(audioProcessingEvent: any) {
var inputBuffer = audioProcessingEvent.inputBuffer;
// The output buffer contains the samples that will be modified and played
var outputBuffer = audioProcessingEvent.outputBuffer;
var isampleRate = inputBuffer.sampleRate;
var osampleRate = 16000;
var inputData = inputBuffer.getChannelData(0);
var outputData = outputBuffer.getChannelData(0);
var output = this.downsampleArray(isampleRate, osampleRate, inputData);
for (var i = 0; i < outputBuffer.length; i++) {
outputData[i] = inputData[i];
}
this.s2tHub.send('ReceiveAudio', new Uint8Array(output.buffer)).catch(err => {this.addMessage(err); });
}
private downsampleArray(irate: any, orate: any, input: any): Int16Array { // 降采样
const ratio = irate / orate;
const olength = Math.round(input.length / ratio);
const output = new Int16Array(olength);
var iidx = 0;
var oidx = 0;
for (var oidx = 0; oidx < output.length; oidx++) {
const nextiidx = Math.round((oidx + 1) * ratio);
var sum = 0;
var cnt = 0;
for (; iidx < nextiidx && iidx < input.length; iidx++) {
sum += input[iidx];
cnt++;
}
// saturate output between -1 and 1
var newfval = Math.max(-1, Math.min(sum / cnt, 1));
// multiply negative values by 2^15 and positive by 2^15 -1 (range of short)
var newsval = newfval < 0 ? newfval * 0x8000 : newfval * 0x7FFF;
output[oidx] = Math.round(newsval);
}
return output;
}
最后,定义stopRecord方法,断开AudioContext连接和Hub连接:
async stopRecord() {
this.jsScriptNode.disconnect(this.context.destination);
this.lowpassFilter.disconnect(this.jsScriptNode);
this.audioInput.disconnect(this.lowpassFilter);
this.s2tHub.stop();
}
5 扩展
- 自定义语音模型
可以上传训练数据进行自定义模型的训练,得到的自定义语音服务可以适应更加特定的业务场景。 不过自定义模型是需要开通标准收费服务的 - 容器部署
微软目前也支持服务的容器部署,通过服务的本地部署,可以提高信息传输速度,并且减小私有信息安全性的顾虑