JAVA框架之hibernate
Java框架之hibernate(一)
前言:
众所周知,Java分为标准版J2SE和企业版J2EE,在普通的Java学习中,基本是对其基本语法的学习,也就是J2SE的基本知识网络,其知识点基本涵括在:
1、基础程序设计;
2、面向对象编程
3、应用程序开发(异常处理,多线程,IO)
相对的说,J2SE在实际的开发应用中用得并不多,更多的是作为一种基础知识,基本思想融入开发,而没有实际的应用。
作为以快速解决问题为目的的实际开发中,如何使用框架解决实际问题显得重要。
在Java连接数据库方面,即JDBC方面,有三大web框架之一的hibernate框架及目前最为主流的框架mybatis。
JDBC本身是个较大的课程,包括hibernate和mybatis,基本知识,进阶知识,实际应用,对比应用这几个版块,故分几篇文章来说明这几个框架。
hibernate基础知识
1、hello hibernate
使用JDBC做数据库相关功能开发会做很多重复性的工作,比如创建连接,关闭连接,把字段逐一映射到属性中。
Hibernate把这一切都封装起来了,使得数据库访问变得轻松而简单,代码也更加容易维护。
第一次使用Hibernate会有一个比较多步骤的配置过程,以后再使用,就很简单了。
首先是对MySQL的使用:
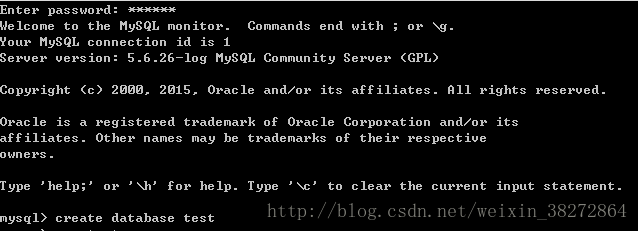
1、 打开MySQL 5.6 client ,并输入password,然后创建数据库
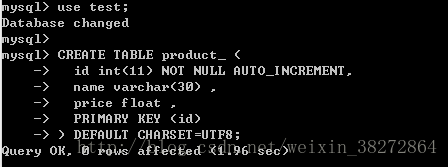
2、 创建表
准备表product_, 有3个字段,分别是:
.1、主键id(自增长)
.2、字符串格式的name
.3、浮点数格式的price
以下是MySQL语句:
use test;
CREATE TABLE product_ (
id int(11) NOT NULL AUTO_INCREMENT,
name varchar(30) ,
price float ,
PRIMARY KEY (id)
) DEFAULT CHARSET=UTF8;
/*
Query OK:你写的sql语句段被成功执行。
0 row addected:影响了0行数据。你写个delete或者update,完了以后,这会告诉你到底删除了几条,或者更新了几条。相当于个小统计。
(0.06 sec):表示你的sql执行了多少时间。
*/
3、创建实体类:
实体类 Product 用于映射数据库中的表product_

配置 Product.hbm.xml
用于映射Product类对应数据库中的product_表;
//表示类Product对应表product_
<id name="id" column="id">
<generator class="native">
generator>
id>表示类Product对应表product_
<id name="id" column="id">
<generator class="native">
generator>
id>表示属性id,映射表里的字段id
class="native"> 意味着id的自增长方式采用数据库的本地方式
这里配置的时候,只写了属性name,没有通过column=”name” 显式的指定字段,那么字段的名字也是name.
Product.hbm.xml
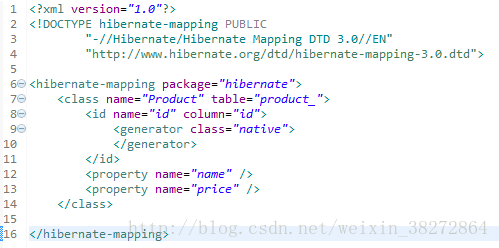
<property name="name" />
<property name="price" />对应于MySQL中的name和price字段
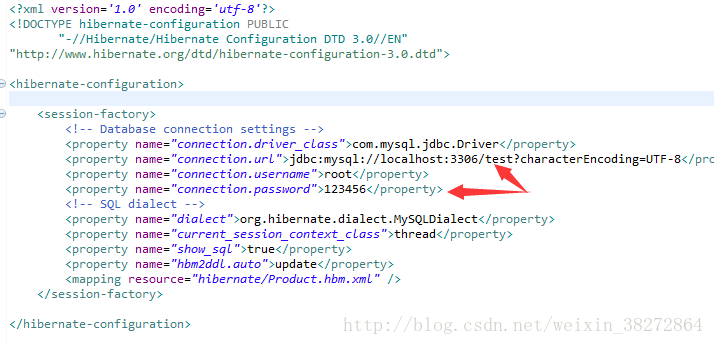
配置 hibernate.cfg.xml
配置访问数据库要用到的驱动,url,账号密码等等
其他配置及含义:
"dialect">org.hibernate.dialect.MySQLDialect 这表示使用MYSQL方言。
什么方言呢? 因为在代码层面,开发人员不用关心底层到底用Oracle还是Mysql,写的代码都是一样的。 可是Oracle和Mysql所用的sql语句的语法是有所区别的,那么这件事就交给Hibernate来做了。这个时候就需要告诉Hibernate底层用的是什么数据库,它才知道应该用什么样的“方言” 去对话。
<property name="current_session_context_class">threadproperty>这是Hibernate事务管理方式,及每个线程一个事务
<property name="show_sql">trueproperty>这表示是否在控制台显示执行的sql语句
<property name="hbm2ddl.auto">updateproperty>这表示是否会自动更新数据库的表结构,有这句话,其实是不需要创建表的,因为Hibernate会自动去创建表结构
<mapping resource="hibernate/Product.hbm.xml" />这表示Hibernate会去识别Product这个实体类
hibernate.cfg.xml:
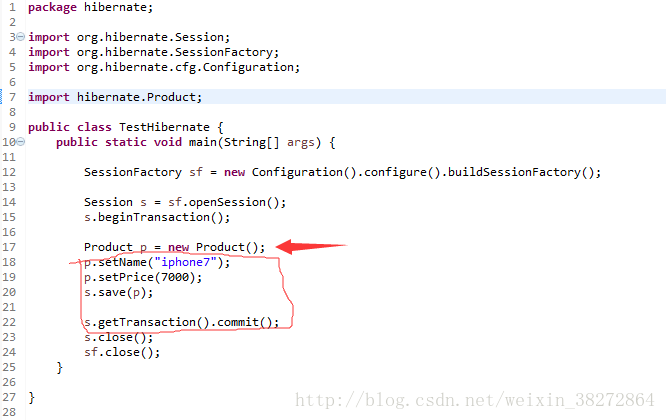
测试类 TestHibernate:
创建一个Product对象,并通过hibernate把这个对象,插入到数据库中
hibernate的基本步骤是:
1. 获取SessionFactory
2. 通过SessionFactory 获取一个Session
3. 在Session基础上开启一个事务
4. 通过调用Session的save方法把对象保存到数据库
5. 提交事务
6. 关闭Session
7. 关闭SessionFactory
TestHibernate:
2、Hibernate多数据插入:
使用循环语句:
for (int i = 0; i < 10; i++) {
Product p = new Product();
p.setName("iphone"+i);
p.setPrice(i);
s.save(p);
}
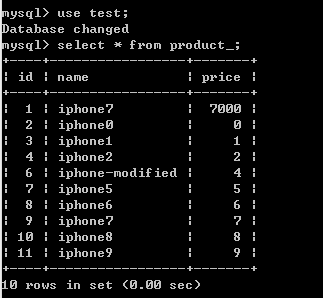
插入结果:
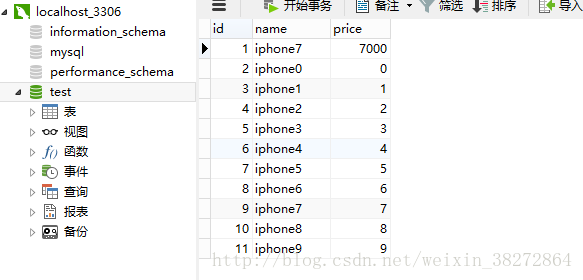
最后的数据插入的结果:
Naive premium版:
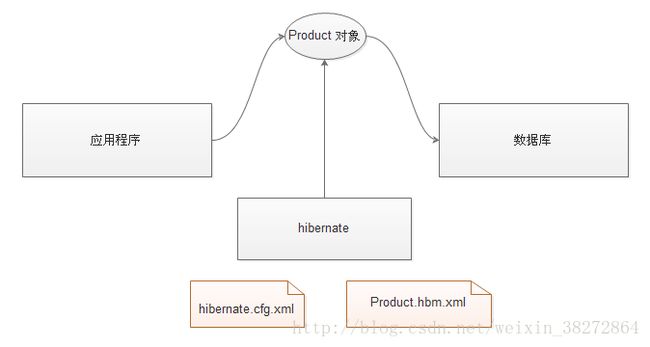
Hibernate基本原理:
应用程序通过Hibernate把 一个 Product对象插入到数据库的product_表中
hibernate.cfg.xml 配置文件提供链接数据库的基本信息
账号 密码 驱动 数据库ip 端口
Product.hbm.xml 提供对象与表的映射关系
对应哪个表? 什么属性,对应什么字段
3、HIBERNATE 对象的三种状态 瞬时 持久 脱管:
Product p = new Product();
p.setName("p1");
System.out.println("此时p是瞬时状态");
s.save(p);
System.out.println("此时p是持久状态");
s.getTransaction().commit();
s.close();
System.out.println("此时p是脱管状态");
sf.close();new 了一个Product();,在数据库中还没有对应的记录,这个时候Product对象的状态是瞬时的。
通过Session的save把该对象保存在了数据库中,该对象也和Session之间产生了联系,此时状态是持久的。
最后把Session关闭了,这个对象在数据库中虽然有对应的数据,但是已经和Session失去了联系,相当于脱离了管理,状态就是脱管的。
4、HIBERNATE/通过ID获取一个对象
Product p =(Product) s.get(Product.class, 6);
System.out.println("id=6的产品名称是: "+p.getName());运行结果:略;
5、删除:
Product p =(Product) s.get(Product.class, 5);
s.delete(p);6、修改:
Product p =(Product) s.get(Product.class, 6);
System.out.println(p.getName());
p.setName("iphone-modified");
s.update(p);结果:
7、HIBERNATE 使用HQL进行查询:
HQL(Hibernate Query Language)是hibernate专门用于查询数据的语句,有别于SQL,HQL跟接近于面向对象的思维方式。
比如使用的是类的名字Product,而非表格的名字product_
String name = "iphone";
Query q =s.createQuery("from Product p where p.name like ?");
q.setString(0, "%"+name+"%");
List ps= q.list();
for (Product p : ps) {
System.out.println(p.getName());
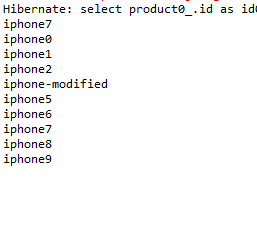
} 使用HQL,根据name进行模糊查询:
1. 首先根据hql创建一个Query对象
2. 设置参数(和基1的PreparedStatement不一样,Query是基0的)
3. 通过Query对象的list()方法即返回查询的结果了。
注: 使用hql的时候,不需要在前面加 select *
运行结果:
8、HIBERNATE 使用CRITERIA进行查询:
使用Criteria进行数据查询。
与HQL和SQL的区别是Criteria 完全是 面向对象的方式在进行数据查询,将不再看到有sql语句的痕迹:
String name = "iphone";
Criteria c= s.createCriteria(Product.class);
c.add(Restrictions.like("name", "%"+name+"%"));
List ps = c.list();
for (Product p : ps) {
System.out.println(p.getName());
} 9、HIBERNATE 使用标准SQL语句进行查询:
通过标准SQL语句进行查询
Hibernate依然保留了对标准SQL语句的支持,在一些场合,比如多表联合查询,并且有分组统计函数的情况下,标准SQL语句依然是效率较高的一种选择:
使用标准SQL,根据name进行模糊查询:
使用Session的createSQLQuery方法执行标准SQL语句
因为标准SQL语句有可能返回各种各样的结果,比如多表查询,分组统计结果等等。 不能保证其查询结果能够装进一个Product对象中,所以返回的集合里的每一个元素是一个对象数组。 然后再通过下标把这个对象数组中的数据取出来。
String name = "iphone";
String sql = "select * from product_ p where p.name like '%"+name+"%'";
Query q= s.createSQLQuery(sql);
List<Object[]> list= q.list();
for (Object[] os : list) {
for (Object filed: os) {
System.out.print(filed+"\t");
}
System.out.println();
}