大数据环境部署
克隆四台虚拟机
例如已经配置好的node1
接下来以node1克隆出三台虚拟机并且配置好ip
1.克隆:
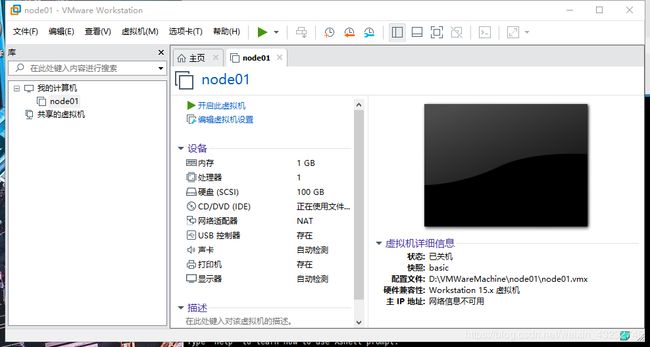 如图,此时创建了一台已经配置好ip的虚拟机。
如图,此时创建了一台已经配置好ip的虚拟机。
ip地址为:192.168.60.101
名字为:node01
![]() 点击这个按钮进入下图的界面
点击这个按钮进入下图的界面
 (图片中已经出现了一个叫basic的快照,因为这个是我之前做的了)
(图片中已经出现了一个叫basic的快照,因为这个是我之前做的了)
大家直接点击克隆就Ok了
(顺便提一下,快照的作用就是可以让你的系统恢复到basic的状态,比如有时手贱删错东西就可以事先拍摄快照,然后出事就可以恢复了)

点击下一步
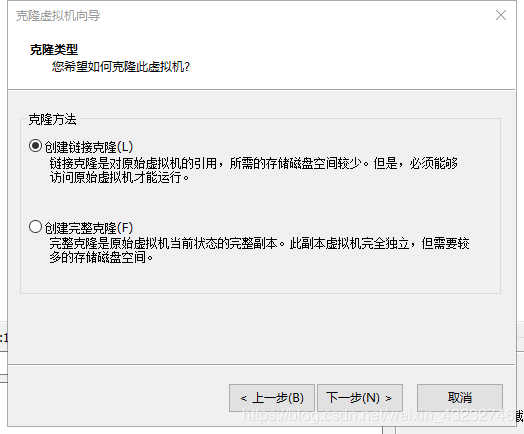
选择创建链接克隆
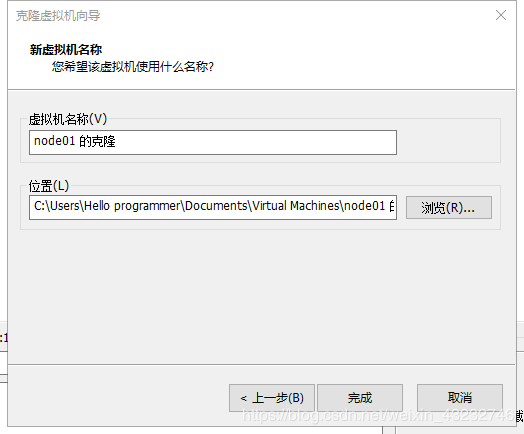
名称:node02
位置尽量和node01的位置放在一起吧
点击完成即可
以此类推,创建其余两台虚拟机;
以上就是克隆的过程
—————————————————————————————————————————————
接下来就要配置ip地址:
node01的ip为192.168.60.101;(这只是我自己的举例子,你自己的和我不一样)
node02的ip为192.168.60.102;
node03的ip为192.168.60.103;
node04的ip为192.168.60.104;
配置过程如下:
1.打开虚拟机输入 用户名:root,密码:123456(在这里是我自己的账号密码配置,你就用自己的密码登录即可)
2.切换目录到:cd /etc/sysconfig/network-scripts/
3.编辑文件ifcfg-eth0: vi ifcfg-eth0
打开文件后,按a进入编辑模式,修改ipaddr:192.168.60.102
按esc退出编辑模式
再敲 :wq 表示保存并关闭文件
这就完成了修改ip地址
4.删除文件70-persistent-net.rules,切换目录到:cd /etc/udev/rules.d/,
然后敲删除文件的命令:rm -f 70-persistent-net.rules
5.改名字:切换目录到:cd /etc/sysconfig/
打开文件:vi network
按a进入编辑模式
将node01 改成node02,按esc退出编辑模式,按 :wq,保存并关闭文件
6.重启虚拟机:init 6
7.ping百度网试试网络是否通畅:ping www.baidu.com
8.以此类推继续配置后面两台机器即可完成 克隆四台虚拟机。
安装JDK
-
下载jdk,注意:要下载linux版本的,我用的是jdk-7u86-linux-x64.rpm
-
将位于windows系统磁盘里的jdk安装包上传到虚拟机里
具体步骤:点击新建文件传输,输入账号密码,将安装包从左边拖入右边即可。 -
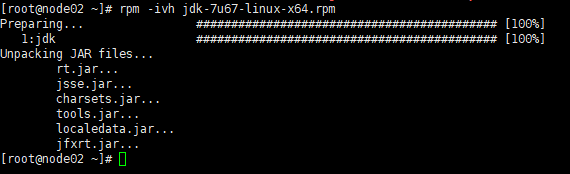
安装jdk 命令:
rpm -ivh jdk-7u86-linux-x64.rpm
.
-
配置环境变量
vi /etc/profile
按a进入编辑模式,到最后一行,复制下面两行,粘贴
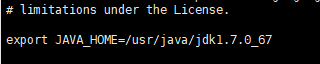
export JAVA_HOME=/usr/java/jdk1.7.0_67
export PATH=$PATH:$JAVA_HOME/bin
按esc,:wq保存并退出
- 输入命令
source /etc/profile - 输入
jps,显示进程即表示安装成功
伪分布式安装Hadoop2.6.5
- 已经完成安装jdk,并且配置好环境变量。
- 进行本机的ssh免密钥操作输入命令:
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
此时输入命令 cd ~/.ssh/
查看此目录下生成了 authorized_keys文件
永久关闭防火墙:
1.service iptables stop (即时关闭)
2.chkconfig iptables off (永久关闭)
输入命令: ssh localhost 免密登入,成功登入后,按exit退出;再输入 ssh node05 免密登入,若两次都成功登陆,即完成免密操作。
-
上传hadoop安装包到服务器。
先创建一个文件夹单独给hadoop
创建文件夹命令:mkdir -p /opt/sxt
解压hadoop到指定文件夹:tar xf hadoop-2.6.5.tar.gz -C /opt/sxt/(-C表示解压到指定目录)
可以cd一下就看到已经解压到指定目录下了 -
配置hadoop的环境变量
vi /etc/profile
export JAVA_HOME=/usr/java/jdk1.7.0_67
export HADOOP_HOME=/opt/sxt/hadoop-2.6.5
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
生效一下
source /etc/profile
5. 配置文件
配置jdk路径:hadoop-env.sh,mapred-env.sh 和 yarn-env.sh
hadoop-env.sh 必改
mapred-env.sh 和 yarn-env.sh 也改,虽然伪分布式安装不会用到,但是以后会用,所以一起改。
添加 jdk 的安装路径,以告诉hadoop去哪里调用jdk
输入命令 echo $JAVA_HOME打印安装路径,复制,分别进入这三个文件修改即可
修改后如图:
*hadoop-env.sh
![]()
*mapred-env.sh
*yarn-env.sh
![]()
—————————————————————————————————————————————
1.配置规定namenode和临时性目录位置的文件:core-site.xml
<property>
<name>fs.defaultFS</name>//主节点的信息
<value>hdfs://node05:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>//临时文件夹位置
<value>/var/sxt/hadoop/pseudo</value>//namenode和DataNode的文件都会放在这
</property>
2.配置规定副本数量和SecondaryNode的文件:hdfs-site.xml
<property>
<name>dfs.replication</name>//副本数量
<value>1</value>//因为是伪分布式,就只有本机,一个就行了
</property>
<property>
<name>dfs.namenode.secondary.http-address</name>//规定第二个主节点的服务器位置
<value>node05:50090</value>//还是本机,因为是伪分布式。
</property>
3.规定谁作为从节点的文件:slaves
localhost 改为 node05
//因为现在是伪分布式,所以主从节点都放在一起了。
—————————————————————————————————————————————
格式化:hdfs namenode -format 生成镜像文件,产生集群ID,(同一集群,同一ID)![]()
成功生成文件到我们规定好的 /var/sxt/hadoop/pseudo/中
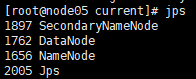
启动集群,生成namenode,DataNode和secondaryNode文件;
jps看进程,发现启动了三个角色进程
浏览器可视化进入Hadoop管理集群
永久关闭防火墙chkconfig iptables off重启
启动集群,start-dfs.sh
浏览器输入:node05:50070
—————————————————————————————————————————————
伪分布式安装Hadoop3.1.1
- 安装好jdk1.8.0.51(同上)
- 免密钥操作(同上)
- 上传Hadoop3.1.1到Linux虚拟机上(同上)
- 解压到指定目录(同上)
- 配置环境变量,即时生效(同上)
- 配置:
vi hadoop-env.sh
让底层找到jdk,若未配置,多个集群启动时会报错,因为他们找不到jdk的位置
配置角色的对应进程,区别于hadoop2,hadoop3更加严格规定角色与进程。

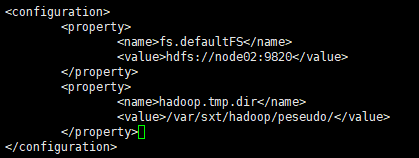
vi core-site.xml
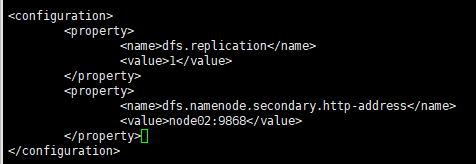
vi hdfs-site.xml
vi worker
localhost 改为 node02
—————————————————————————————————————————————
在node01上ssh免密登录node02,node03等等:
vi /etc/hosts添加下列ip
192.168.60.101 node01
192.168.60.102 node02
192.168.60.103 node03
192.168.60.104 node04
192.168.60.105 node05
- 分别在
node01,node02,node03,node04上进行免密操作
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
- 将node01的
id_dsa_pub和hosts分发给node02,node03,node04
scp ~/.ssh/id_dsa.pub root@node02:~/
scp /etc/hosts root@node02:/etc/
scp ~/.ssh/id_dsa.pub root@node03:~/
scp /etc/hosts root@node03:/etc/
scp ~/.ssh/id_dsa.pub root@node04:~/
scp /etc/hosts root@node04:/etc/
注意:期间每次分发都要输入密码
- node02,node03,node04分别输入以下命令即可:
cat ~/id_dsa.pub >> ~/.ssh/authorized_keys
—————————————————————————————————————————————
配置全分布式
-
vi hadoop.env.sh
-
vi core-site.xml
-
vi hdfs-site.xml

-
vi worker

———————————————————————————————————————————
分发Hadoop包到从节点
一个一个节点分发scp -r /software/opt/sxt/hadoop-3.1.1 node03:/software/opt/sxt/
—————————————————————————————————————————————
Hadoop全分布式启动
- 配置好每个节点的环境变量
- hdfs namenode -format
- start-dfs.sh
- 改window里的hosts
- 网页打开
—————————————————————————————————————————————
Xshell的使用技巧:
- 查看撰写栏可以一次性下达任务给集群
- open命令一次性打开n个机器需要自己设置
—————————————————————————————————————————————
ha高可用性搭建(HDFS High Availability)
就是给每个节点布置任务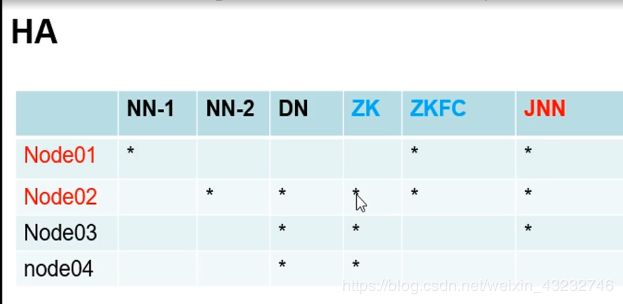
zk:分布式协调,单独部署和搭建
zkfc:和namenode放在一起,物理进程,监控作用,启动配置即可,和zk关联
jnn:存储编辑日志信息,信息同步作用
—————————————————————————————————————————————
-
做个保险
复制一下hadoop3.1.1目录下的etc/的hadoop文件cp -r hadoop hadoop-full -
修改 hadoop.env.sh文件
vi hadoop.env.shexport JAVA_HOME=/usr/java/jdk1.8.0_51 export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root #export HDFS_SECONDARYNAMENODE_USER=root export HDFS_ZKFC_USER=root //故障转移 export HDFS_JOURNALNODE_USER=root -
修改 core-site.xml文件
vi core-site.xml<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://node01:9820</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/var/sxt/hadoop/ha</value>//换一个路径名,改为ha,运行时产生ha文件夹 </property> <property> <name>hadoop.http.staticuser.user</name> <value>root</value> </property> </configuration> -
修改 hdfs-site.xml
vi hdfs-site.xml<configuration> <property> <name>dfs.replication</name> <value>2</value>//副本数量 </property> <property> <name>dfs.nameservices</name> <value>mycluster</value>//逻辑服务名称,随便改 </property> <property> <name>dfs.ha.namenodes.mycluster</name> <value>nn1,nn2</value>//逻辑名称映射到两个逻辑的node名:nn1,nn2 </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn1</name>//nn1指代的物理机 <value>node01:8020</value> </property> <property> <name>dfs.namenode.rpc-address.mycluster.nn2</name>//nn2指代的物理机 <value>node02:8020</value> </property> <property> <name>dfs.namenode.http-address.mycluster.nn1</name> <value>node01:9870</value>//配置浏览器nn1时访问时的ip和端口 </property> <property> <name>dfs.namenode.http-address.mycluster.nn2</name> <value>node02:9870</value>//配置浏览器nn2时访问时的ip和端口 </property> <property> <name>dfs.namenode.shared.edits.dir</name> <value>qjournal://node01:8485;node02:8485;node03:8485/mycluster</value>//规定journal集群位置 </property> <property> <name>dfs.client.failover.proxy.provider.mycluster</name>//规定故障转移的代理位置 <value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value> </property> <property> <name>dfs.ha.fencing.methods</name>//namenode切换状态时隔离方法的设置,保证任何时刻只有一个namenode处于活跃状态,防止脑裂,因此需要免密钥登录,使用私钥 <value>sshfence</value> </property> <property> <name>dfs.ha.fencing.ssh.private-key-files</name>//私钥位置 <value>/root/.ssh/id_rsa</value> </property> <property> <name>dfs.journalnode.edits.dir</name>//journalnode日志目录存放位置 <value>/var/sxt/hadoop/ha/journalnode</value> </property> <property> <name>dfs.ha.automatic-failover.enabled</name>//自动故障切换 <value>true</value> </property> </configuration> -
再次修改core-site.xml文件
vi core-site.xml<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://mycluster</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/var/sxt/hadoop/ha</value> </property> <property> <name>hadoop.http.staticuser.user</name> <value>root</value> </property> <property> <name>ha.zookeeper.quorum</name> <value>node02:2181,node03:2181,node04:2181</value> </property> </configuration>
—————————————————————————————————————————————
- 分发文件到node02,node03,node04。
scp core-site.xml hdfs-site.xml hadoop-env.sh node02:`pwd`
scp core-site.xml hdfs-site.xml hadoop-env.sh node03:`pwd`
scp core-site.xml hdfs-site.xml hadoop-env.sh node04:`pwd`
安装zookeeper3.4.6
-
安装到node02,node03,node04
-
先将安装包上传到node02,进行安装,安装到
/software/opt/sxt/目录下 -
配置环境变量
export JAVA_HOME=/usr/java/jdk1.8.0_51 export HADOOP_HOME=/software/opt/sxt/hadoop-3.1.1 export ZOOKEEPER_HOME=/software/opt/sxt/zookeeper-3.4.6 export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZOOKEEPER_HOME/bin -
分发到node03,04
scp /etc/profile node03:/etc/ scp /etc/profile node04:/etc/ -
改
/software/opt/sxt/zookeeper-3.4.6/conf目录下的zoo.sample.cfg文件名 为zoo.cfgmv zoo_sample.cfg zoo.cfg -
修改
zoo.cfg文件vi zoo.cfg修改
dataDir=/var/sxt/zk
添加:server.1=node02:2888:3888 server.2=node03:2888:3888 server.3=node04:2888:3888保存。
-
分发
scp -r zookeeper-3.4.6/ node03:`pwd` scp -r zookeeper-3.4.6/ node04:`pwd` -
创建目录并且添加文件
mkdir -p /var/sxt/zk //在02,03,04上都要创建 echo 1 > /var/sxt/zk/myid//node02对应 1 ,node03对应2 -
ZooKeeper配置完毕。
启动ZooKeeper
zkServer.sh start在node02,03,04下发布命令。- 查看当前zookeeper状态:
zkServer.sh status,02,03为follower,04为leader表示运行正常 - 停止ZooKeeper:
zkServer.sh stop - 集群的存活机制:过半启动才被认定为存活
如:ZooKeeper集群有3台机器,若只启动一台,并不代表集群启动,至少启动两台。 - 一般数字大的为主(leader)
- 通过客户端连接服务器:启动一个新窗口,输入命令:
zkCli.sh
格式化操作
- 选择1:利用已经有的namenode信息同步给另一台备用namenode,在备用的namenode上执行:
hdfs namenode -initializeSharedEdits即可。 - 选择2:重新格式化一个namenode节点,产生新的元数据信息(当前集群的id以及当前集群的fsimage文件),然后在另一个节点上执行:
hdfs namenode -bootstrapStandby
- 查看目录:
/var/sxt/hadoop/里面无ha文件夹 - 分别在 1,2,3节点 上启动 journalnode:
hdfs --daemon start journalnode - 再次查看目录
/var/sxt/hadoop/里面出现了ha文件夹,ha里有journalnode文件夹 - 在主节点上进行格式化,node01或node02任选一个:
hdfs namenode -format - 查看目录:
/var/sxt/hadoop/ha下出现了dfs文件夹,进入name,current ,cat Version,查看集群id(clusterID),此时node02中无dfs文件,因此需要同步 - 在node01上启动namenode节点,
hadoop-daemon.sh start namenode - 在node02上执行
hdfs namenode -bootstrapStandby,开始同步 - 再次查看目录:
/var/sxt/hadoop/ha下出现了dfs文件夹,进入name,current ,cat Version,查看集群id(clusterID),发现和node01的集群ID相同。 - 同步成功。
ZooKeeper格式化
- 执行命令:
hdfs zkfc -formatZK(前提已经启动了ZooKeeper) - 通过客户端可发现出现了新的文件夹:
mycluster - 启动hadoop集群:
start-dfs.sh - 查看各个节点的进程,发现进程都符合配置
mycluster文件夹生成了两个文件,用get获取节点信息- 测试:将node01的namenode关闭:
hdfs --daemon stop namenode,用浏览器打开集群的管理页面,发现node01将会变为待命状态,node02变为活跃态。
Hadoop API(弄好这才可以在eclipse上编程)
- 下载
eclipse,我用的是eclipse mars2.0 - 然后将
hadoop-eclipse-plugin-2.6.0.jar丢进ide目录下plugins文件夹内 - 在windows上解压hadoop3.1.1,
解压目录纯英文 - 然后下载
windows版本的hadoop3.1.1的bin文件夹,并替换掉原来的linux版本的bin - 将bin文件夹内的hadoop.dll文件丢进c盘的system32文件夹内
- 配置环境变量:此电脑,右键,属性,(左边)高级系统设置,环境变量,系统变量,新建,变量名:
HADOOP_HOME,变量值:(hadoop3.1.1在window系统里的路径);然后再新建,变量名:HADOOP_USER_NAME,变量值:root。然后往下翻双击Path变量,在里边新建,内容为:%HADOOP_HOME%\bin。 - 打开
hadoop3.1.1\share\hadoop,将里面所有文件夹内的jar文件复制 - 再创建一个 叫
hadoop-lib的文件夹,将刚刚复制的jar包放到这个文件夹内 - 打开eclipse
- 点击上方
Window,Preferences,点击左边Hadoop Map/Reduce,填写hadoop3.1.1在window下的路径。 - 点击
open Perspective ,找到map/reduce,双击,在下方Map/Reduce Location下鼠标右键,点击New Hadoop Location,不勾选Use M/R master host,host填:
,找到map/reduce,双击,在下方Map/Reduce Location下鼠标右键,点击New Hadoop Location,不勾选Use M/R master host,host填:node01(active),port填:8020。 - 点击
Window,Preferences,左侧,Java,Build Path,User Libraries,点击new,写个名字(hadoop3.1.1)然后 点击Add External jars(导入已存在的jar包),打开hadoop-lib文件,将里面的所有jar包导入即可。 - 新建一个java项目,File ,new, project ,java Project。
- 导入 jar包进java项目内,右键刚刚创建的项目,点击Build Path,Add libraries,User Libraries,勾上刚刚创建的hadoop3.1.1,点击Finish;再导入单元测试的包,相同步骤,Add libraries,JUnit,next,Finish。
- 添加配置文件,
右键项目,New,Folder,文件夹名:conf,我们有full集群和ha集群,为了方便运用两个集群在conf文件夹下新建一个名叫ha的子文件夹,conf右键New,Folder,文件名ha,到linux上新建文件传输将hadoop/etc/下的core-site.xml和hdfs-site.xml传输到window系统里,再放到ha文件夹里。右键ha,点击Build Path,点击Use as Source Folder即可。 - 右键src,新建class,开始写一下测试代码。
测试代码:
package first;
import java.io.BufferedInputStream;
import java.io.File;
import java.io.FileInputStream;
import java.io.IOException;
import java.io.InputStream;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.BlockLocation;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IOUtils;
import org.apache.hadoop.shaded.org.apache.kerby.asn1.util.IOUtil;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
public class test {
Configuration conf;
FileSystem fs;//文件系统类
@Before
public void conn() throws Exception{//连接
conf = new Configuration(true);//读配置文件,就是ha里面的xml文件
fs = FileSystem.get(conf);//用上了配置信息,客户端对象
}
@After
public void close() throws Exception{//关闭
fs.close();
}
@Test
public void mkdir() throws Exception{//创建文件夹
Path ifile = new Path("/ooxx");
if(fs.exists(ifile))
{
fs.delete(ifile,true);
}
fs.mkdirs(ifile);
}
@Test
public void upload() throws Exception{//上传文件
Path f = new Path("/001/hello.txt");
FSDataOutputStream output = fs.create(f);
InputStream input = new BufferedInputStream(new FileInputStream(new File("F:\\helloworld.txt")));
IOUtils.copyBytes(input, output, conf, true);
}
@Test
public void blks() throws Exception{//查看块信息
Path i = new Path("/user/root/weibo.csv");
FileStatus ifile = fs.getFileLinkStatus(i );
BlockLocation[] blks = fs.getFileBlockLocations(ifile, 0, ifile.getLen());
for(BlockLocation b : blks){
System.out.println(b);
}
FSDataInputStream in = fs.open(i);//读取文件
System.out.println((char)in.readByte());
System.out.println((char)in.readByte());
System.out.println((char)in.readByte());
System.out.println((char)in.readByte());
System.out.println((char)in.readByte());
System.out.println((char)in.readByte());
System.out.println((char)in.readByte());
System.out.println((char)in.readByte());
}
}
MapReduce分布式计算
MapReduce基于YARN运行
RS:ResourceManager(主,核心,集群节点资源管理)
NM:NodeManager(与RM汇报资源情况,管理Container)

- node01上配置
mapred-site.xml文件
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.application.classpath</name>
<value>$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/*:$HADOOP_MAPRED_HOME/share/hadoop/mapreduce/lib/*
- 配置
yarn-site.xml文件
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.env-whitelist</name>
<value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value>
</property>
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>cluster1</value>
</property>
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>node03</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>node04</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>node03:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>node04:8088</value>
</property>
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>node02:2181,node03:2181,node04:2181</value>
</property>
注意!!注意!!注意!!!!!!!
hadoop3.x版本
配置yarn-env.sh
export YARN_RESOURCEMANAGER_USER=root
export HADOOP_SECURE_DN_USER=yarn
export YARN_NODEMANAGER_USER=root
完事后分发一下
cd /software/opt/sxt/hadoop-3.1.1/etc/hadoop
scp mapred-site.xml yarn-site.xml yarn-env.sh node02:`pwd`
scp mapred-site.xml yarn-site.xml yarn-env.sh node03:`pwd`
scp mapred-site.xml yarn-site.xml yarn-env.sh node04:`pwd`
-
输入
start-all.sh启动启动所以,包括dfs.sh和yarn.sh -
node01的进程
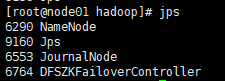
-
node02的进程
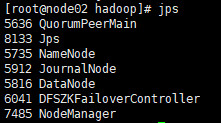
有NodeManager -
node03的进程
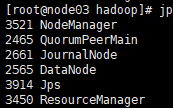
有NodeManager
有ResourceManager -
node04的进程

有NodeManager
有ResourceManager
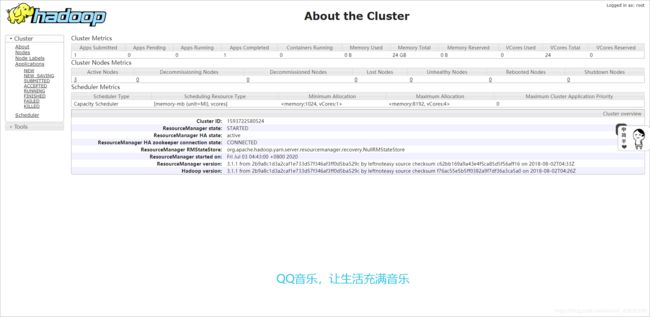
打开网址:http://node03:8088
打开网址:http://node04:8088会自动跳转至http://node03:8088因为node04处于standby状态
- 测试:使用MapReduce的wordcount:
先在hdfs中上传文件test.txt(刚刚上面Hadoop API的代码可以实现)
我是把test.txt文件上传到了/001/里
将完成任务后的文件放在/data/wc/output内
执行以下命令:
hadoop jar hadoop-mapreduce-examples-3.1.1.jar wordcount /001/test.txt /data/wc/output
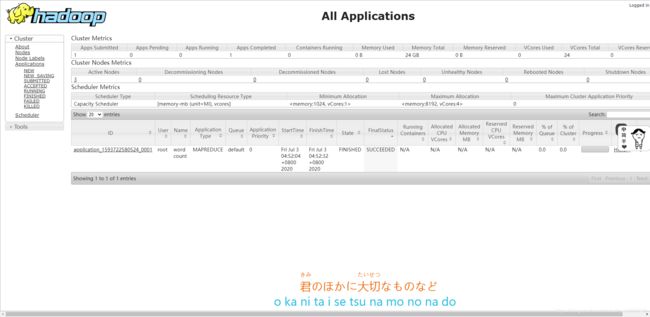
打开网址:http://node03:8088点击Application可以看进度
成功后:
网址显示:
xshell里显示:

手写MapReduce
- 打开IDE,new class.
- 大致思路:写客户端,写Map,写Reduce,三大步
- 下载 hadoop3.1.1源码包,hadoop-3.1.1-src.tar.gz 百度即可。
- ctrl点Job,然后导入源码即可。
Hive (数据仓库)
- 作用:数据分析
- 搭建:
安装mysql
-
安装命令:
yum install -y mysql-server -
启动服务:
service mysqld start -
配置启动:
chkconfig mysqld on -
启动:
mysql -
查看数据:
show databases; -
配置权限
- 命令:
use mysql>>show tables;>>desc user;>>select user,host,password from user;

- 特权语句:
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '123' WITH GRANT OPTION;
PRIVILEGES特权的意思,*.*所有表的所有权限,'root'用户名,'%'所有的ip地址,IDENTIFIED BY '123'密码是123
![]()
- 再输入:
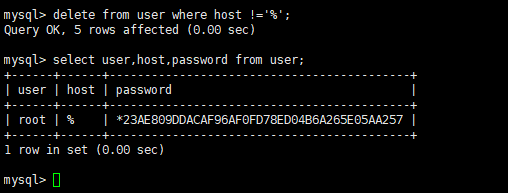
select user,host,password from user;

- 删除多余的配置项:
delete from user where host !='%';
- 刷新一下:
flush privileges; - 退出:
quit - 重新打开:
mysql -uroot -p,然后输入密码:123
Hive的安装部署
单用户模式
-
将
mysql-connector-java-5.1.32-bin.jar和apache-hive-1.2.1-bin.tar.gz传输到node02上 -
解压
apache-hive-1.2.1-bin.tar.gz到/root下:tar -zxvf apache-hive-1.2.1-bin.tar.gz -C /root/ -
配置环境变量:
vi /etc/profile
export HIVE_HOME=/root/apache-hive-1.2.1-bin
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$ZOOKEEPER_HOME/bin:$HIVE_GOME/bin
:wq >> source /etc/profile
- 配置文件:
hive-default.xml.template
改名:mv hive-default.xml.template hive-site.xml
配置文件:vi hive-site.xml
删除原有的配置:.,-1d,粘贴下面的配置信息
hive.metastore.warehouse.dir</name>
/user/hive_remote/warehouse</value>
</property>
hive.metastore.local</name>
false</value>
</property>
javax.jdo.option.ConnectionURL</name>
jdbc:mysql://node01/hive_remote?createDatabaseIfNotExist=true</value>
</property>
javax.jdo.option.ConnectionDriverName</name>
com.mysql.jdbc.Driver</value>
</property>
javax.jdo.option.ConnectionUserName</name>
root</value>
</property>
javax.jdo.option.ConnectionPassword</name>
123</value>
</property>
将mysql-connector-java-5.1.32-bin.jar拷贝到lib下:cp /root/mysql-connector-java-5.1.32-bin.jar /root/apache-hive-1.2.1-bin/lib/