又双叒叕来更新啦!!Hadoop——基础篇
文章目录
- Hadoop基础篇
- 大数据概论
- Hadoop入门
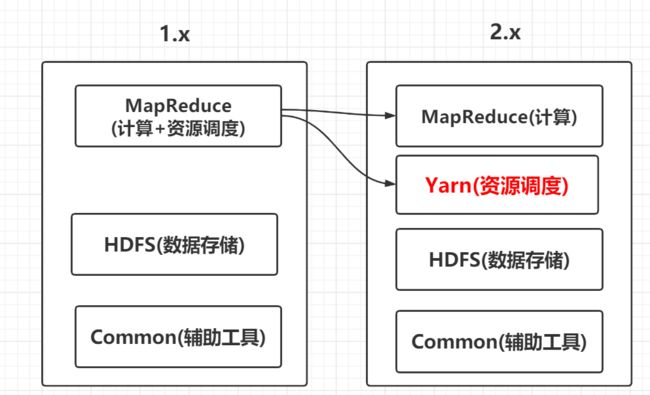
- Hadoop的组成
- HDFS架构概述
- Yarn架构
- MapReduce架构
- 大数据的技术生态体系
- 开发环境搭建
- 安装jdk
- 安装Hadoop
- 本地模式
- 伪分布式模式
- 启动HDFS并运行MapReduce程序
- 配置集群
- 启动集群
- 启动YARN并运行MapReduce程序
- 配置集群
- 启动集群
- 配置历史服务器
- 日志的聚集配置
- 完全分布式模式(重点!!)
- 准备工作
- 编写集群分发脚本xsync
- 集群配置
- 集群单点启动
- SSH免密登录
- 免密登录的原理
- 群起集群
- crond系统定时任务
- 集群时间同步
- 使用chrony搭建ntp服务器
- Hadoop源码编译
- 工具环境安装具体步骤
- 编译源码
Hadoop基础篇
大数据概论
概念
大数据(Big Data):指的是无法在一定时间范围内用常规软件工具(JavaEE)进行捕获、管理的处理的数据集合。
需要新的处理模式更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产
常用的数据存储单位:TB、PB、EB,ZB,YB,大企业的数据量已经接近EB量级。
主要解决问题
海量数据的存储和分析计算
特点(4V)
-
Volume大量!
-
Velocity高速!
-
Variety多样!
存储各种非结构化数据:音视频、图片等
-
Value(低价值密度)
数据的价值密度和数据总量的大小成反比
应用场景
- 物流仓储:分析仓库选址
- 零售行业:分析用户消费习惯,典型:纸尿裤+啤酒
- 旅游行业
- 商品广告推荐
- 保险、金融、房地产
- 人工智能
Hadoop入门

是什么?
Apache基金会的顶级开源项目,一个分布式系统基本架构。
解决数据的存储和分析计算
通常是指的是Hadoop生态圈(HBase、Hive、Zookeeper等)
发展历程
与Lucene是同一个作者——Doug Cutting,其logo和名字源于作者儿子的一个玩具大象。
海量数据场景中Lucene和Google都遇到了相同的困难:存储困难,检索速度慢
Hadoop就是DougCutting在借助谷歌的开放技术三篇论文激发灵感改造以Lucene为核心的Nutch而来。
推荐阅读:https://www.sohu.com/a/294319573_700886
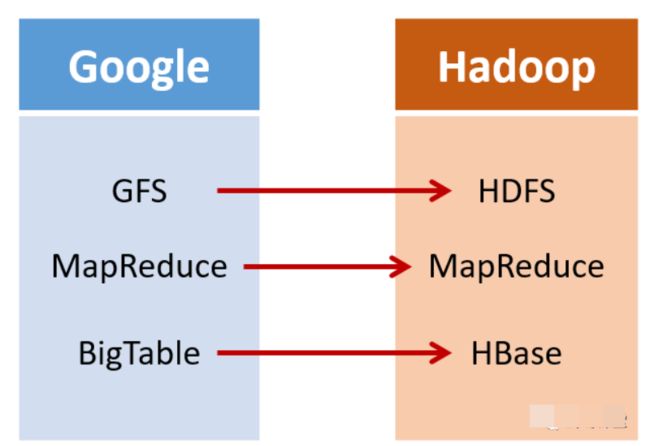
| Nutch | |
|---|---|
| GFS | HDFS(Hadoop分布式文件系统) |
| MapReduce | MapReduce |
| Big Table | HBase |
三大发行版本
- Apache:最原始基础的版本、入门学习容易上手,开源
- Cloudera:大型互联网企业中用的较多
- Hortonworks:文档完整
四大优势
- 高可靠性:hadoop底层维护多个(5个)数据副本
- 高扩展性:在集群间分配任务数据,方便扩展数以千计的节点
- 高效性:MapReduce的思想下,Hadoop是并行工作的,以加快任务处理的速度
- 高容错性:能够将自动将失败的任务重新分配
Hadoop的组成
HDFS架构概述
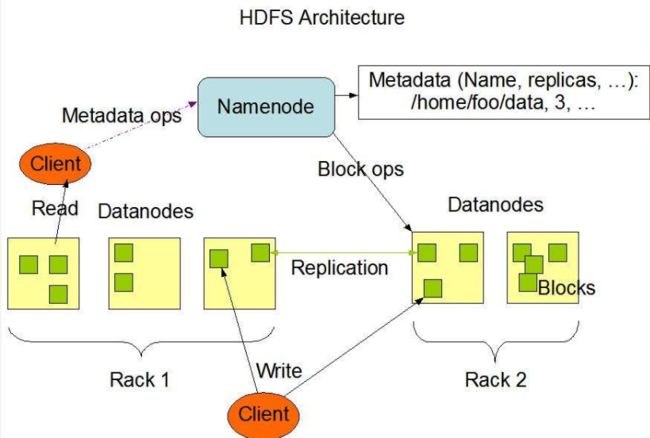
Hadoop分布式文件系统,主要负责数据存储
-
NameNode(nn)
存储文件的元数据,例如文件名、文件目录结构、文件属性(生成时间、副本数、文件权限),以及每个文件的块列表和块所在的DataNode等
-
DataNode(dn)
在本地文件系统存储文件块数据,以及块数据的校验和。
-
Secondary NameNode(2nn)
用来监控HDFS的状态的后台辅助程序,每隔一段时间获取HDFS元数据的快照。
Yarn架构
多用于资源的调度和分配

-
ResourceManager
- 处理客户端请求
- 监控NodeManager
- 启动和监控ApplicationMaster
- 资源的调度与分配
-
NodeManager
多个NodeManager隶属于一个ResourceManager,管理多个ApplicationMaster
- 管理单个节点上分配到的资源
- 处理来自ResourceManager、ApplicationMaster的命令
-
ApplicationMaster
负责每个任务(job)上进行资源请求和管理
- 负责数据切分
- 为应用程序申请资源,并分配给内部的任务
- 任务的监控和容错
-
Container
Yarn中资源的抽象,封装了某个节点上的多维度资源:内存、CPU、磁盘、网络等。
MapReduce架构
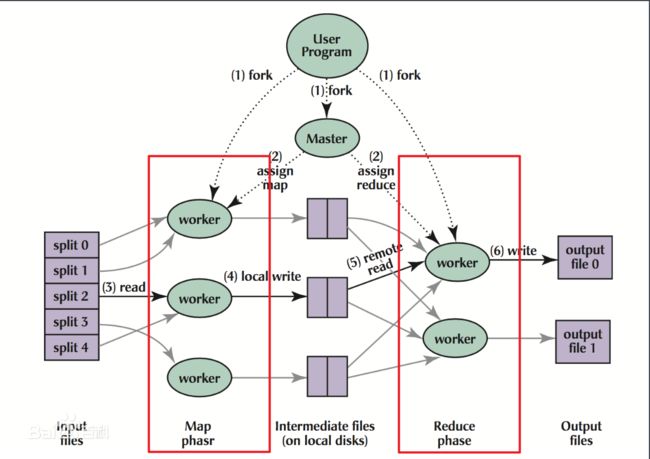
分为两个阶段:Map和Reduce
Map阶段:并行处理输入的数据
Reduce阶段:对Map阶段数据处理的结果进行汇总
来一张简单易懂的图:

大数据的技术生态体系

开发环境搭建
-
修改静态ip
-
修改主机名:
vim /etc/sysconf/network>HOSTNAME=xxx -
修改hosts文件:
vim /etc/hosts -
创建用户添加root权限:
vim /etc/sudoers->sakura ALL=(ALL) ALL -
在/opt目录下创建两个目录:/module和/software,并修改所有者和所有组。
sudo chown sakura:sakura module/ software/ -
导入java、hadoop的tar.gz的安装包
hadoop下载:https://mirror.bit.edu.cn/apache/hadoop/common/
安装jdk
-
解压到module目录下
tar -zxvf jdk-8u251-linux-x64.tar.gz -C /opt/module/ -
配置环境变量
sudo vim /etc/profile# java enviroment export JAVA_HOME=/opt/module/jdk1.8.0_251 export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar export PATH=$PATH:$JAVA_HOME/bin重新加载配置文件
source /etc/profile -
java -version检查是否安装成功
安装Hadoop
-
解压与jdk安装一样
-
配置环境变量
# hadoop enviroment export HADOOP_HOME=/opt/module/hadoop-2.7.7 export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin也需要重新加载配置文件
-
hadoop version检查是否安装成功
-
目录结构了解:
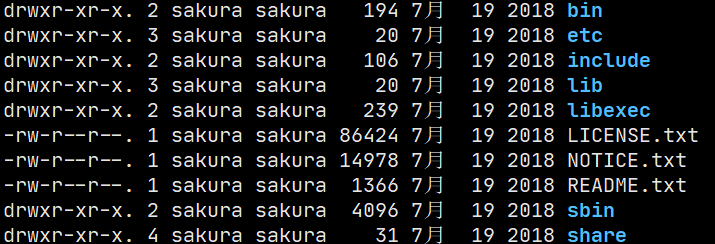
-
bin目录结构:(hadoop的组成的各部分)

-
etc/hadoop目录下存放着大量的配置文件

-
include 引用的其他文件
-
lib 本地库
-
sbin Hadoop相关的启停文件
-
share 一些说明文档和官方提供的example
官方文档:https://hadoop.apache.org/docs/r2.7.7/
-
本地模式
Hadoop官方说明中提到:Hadoop支持三种模式:
- 本地模式(Local Mode)
- 伪分布式模式(Pseudo-Distributed Mode)
- 完全分布式模式(Full-Distributed Mode)

官方给出的第一个example:Grep

-
在hadoop的根目录下创建一个input目录,拷贝 etc/hadoop/下的所有的.xml文件到input目录中

-
执行share目录中指定jar包中的example
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar grep input/ output 'dfs[a-z.]+'注意点:
-
由于这个jar包中有多个程序,我们只需要运行grep即可
-
output一定是未创建的状态,执行位置必须在input的同级目录下,才能将output输出到同级目录
-
若output已存在会报错(file already exist)

-
-
查看输出结果:
在生成的output目录下:有两个文件

前者是生成的结果,可以查看,_SUCCESS仅作为执行状态标志。
结果文件中只有一行:
1 dfsadmin
这就是grep程序过滤出来的结果,你也可以修改正则表达式,删除output目录重新执行。
官方第二个案例`WordCount`(单词数量统计)
1. 创建一个输入文件的目录 wcinput,并创建文件wc.input,并随意写入一些单词
hadoop java
c c++
python java hadoop c
hadoop java hadoop
sakura
java
sakura
2. 启动调用wordcount程序,并指定输入和输出
```shell
hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount wcinput/ wcoutput
-
查看结果:
还是两个文件:


伪分布式模式
使用分布式的配置,但是只有一台服务器
启动HDFS并运行MapReduce程序
配置集群
-
配置etc/hadoop/core-site.xml文件
一定是写在标签中的:
<property> <name>fs.defaultFSname> <value>hdfs://hadoop101:9000value> property> <property> <name>hadoop.tmp.dirname> <value>/opt/module/hadoop-2.7.7/data/tmpvalue> property>这是官网给出的core-site的配置修改:

注意:
-
我们结合使用官网文档中给出的默认配置信息对比学习。
官方给出了几个配置文件的默认配置信息:
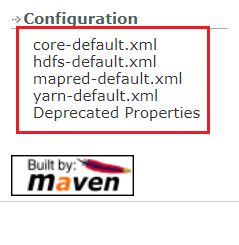
-
fs.defaultFS(Hadoop的文件系统配置)配置的是本机的文件系统
file:///
现在我将hadoop的文件系统改为了
hdfs://两者只是不同的协议。(类似于http://、jdbc:mysql://、ftp:// 等等)
配置完成后,本地模式就不能再使用了。因为hdfs://文件系统与file://不同,后者的文件是直接放在本地目录下的,前者则不同,稍后启动集群会讲到hdfs。
-
hadoop.tmp.dir(Hadoop运行产生文件的存储路径)默认位置是
/tmp/hadoop-${user.name}
为了方便学习和查找文件,将其改到了Hadoop的安装目录下
/opt/module/hadoop-2.7.7/data/tmp
-
-
修改etc/hadoop/hadoop-env.sh中的JAVA_HOME配置
# 这是默认配置 export JAVA_HOME=${JAVA_HOME} # 修改为具体的JAVA_HOME路径 export JAVA_HOME=/opt/module/jdk1.8.0_251
-
配置etc/hadoop/hdfs-site.xml
<configuration> <property> <name>dfs.replicationname> <value>1value> property> configuration>官方给出的默认配置中是3个:

而由于我们是单服务器的伪分布式模式,所有只有一台主机。
启动集群
-
格式化NameNode(第一次启动)使用/bin/hdfs命令
bin/hdfs namenode -format -
启动NameNode
sbin/hadoop-daemon.sh start namenode使用jps命令查看是否启动了NameNode
-
再启动DataNode
sbin/hadoop-daemon.sh start datanode同样使用jps命令查看状态

-
访问localhost:50070测试能否响应,若成功则表示配置成功

想要远程访问,先关闭Linux的防火墙
使用
systemctl status firewalld.service查看状态,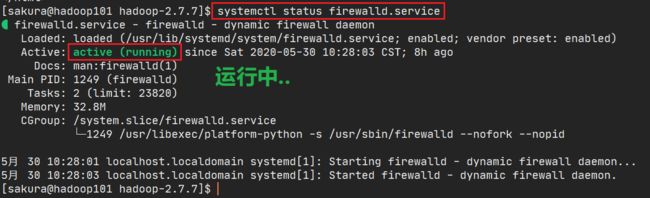
systemctl stop firewall即可关闭防火墙,然后再次查看防火墙状态。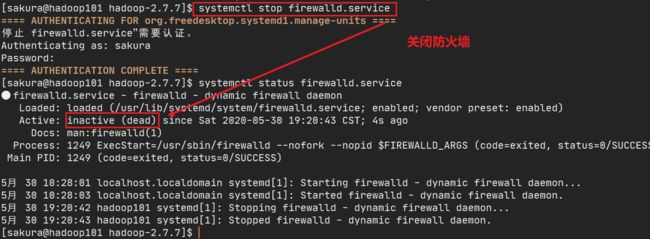
-
远程访问界面

这里由于我是修改了windows上的host文件的 把hadoop101和192.168.52.201做了映射。
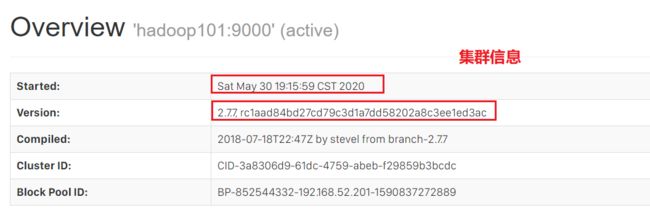

重点位置!

Logs就是输出的日志文件,最重点的地方是Browse the file system!!
上面我们配置了hdfs协议的文件系统,这里就是我们配置过后文件系统的可视化工具!!
以后hadoop获取输入和输出位置都不再是使用本机作为输入输出(file协议的文件系统)!
而是输出到一个特定的位置(我也很好奇在哪?!)然后我们通过这个可视化的工具可以查看hdfs文件系统中的内容。说明:这个文件系统的结构和Linux类似(一个根目录然后多个子目录),Linux中的命令可以通用,只不过再使用命令行操作的时候要加上固定的前缀!

我们再Linux中创建一个文件夹!
现在可不是渐渐单单的mkdir咯!!
bin/hdfs dfs -mkdir -p /home/sakura/input固定前缀其实就是使用的一个命令
hdfs dfs,它有很多选项:-mkdir只是其中一种。
刷新网页,看是否创建成功

来了把,我们再Linux中使用命令行也可以查看:
hdfs dfs -ls -R \
刚才说修改了hdfs文件系统协议**本地模式就不能用了?**偏不信,来试试看:
报错:

这次并不是输出目录存在,而是==没有这个输入文件!==龟龟,我明明写的就是正确的目录啊,本机上也有这个文件。仔细看:这次Hadoop运行寻找文件的位置不再是本机啦!!而是
hdfs://hadoop101:9000/user/sakura这个目录了!和我们在core-site中配置一致,那么我们基本上可以认为:hdfs文件系统由Linux上一个 使用9000端口的进程管理着,并且切换后hadoop的工作目录是的/user/sakura 其实这个就是我们的NameNode。。。不信用jps查看进程对比一下进程号
其实这个就是我们的NameNode。。。不信用jps查看进程对比一下进程号**关于工作目录为什么是/user/{username}**在默认的配置中也是可以找到依据的:
默认的用户home目录前缀就是/user

所以现在删掉之前的目录创建一个/user/sakura/input目录吧。
既然它要使用这个文件系统下的文件,那么如何从本机上传文件到这里面呢?
# -put选项上传文件 hdfs dfs -put wcinput/wc.input /user/sakura/input
这个块和磁盘中的文件块概念类似。
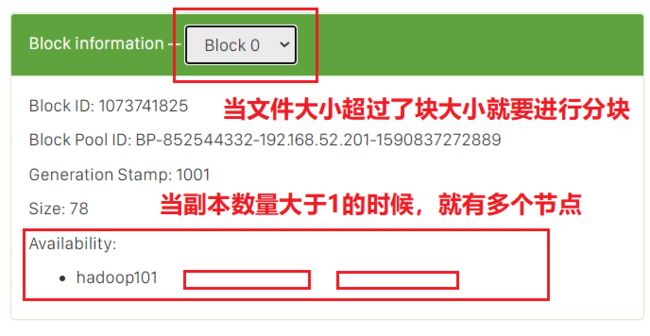
然后我们再Linux上再次运行:
可以很明显看到再map-reduce那里稍微卡顿了一下,我们来看看输出情况:

没有问题,查看输出内容:
-
方式一:下载文件到windows查看(可能会失败,据说是要修改windows的host文件?!不清楚)
-
方式二(常用!):再Linux上查看:

-
注意:如果后续要进行NameNode格式化,先要进行两个操作:
- 关闭DataNode、NameNode的进程,使用jps检查
- 删除data、logs目录
- 执行
hdfs namenode -format
问题:为什么不能一直格式化NameNode?格式化NameNode需要注意什么?
首先明确几个点:
- DataNode和NameNode之间的关系就相当于书内容和书目录的关系,两者需要项目通信和信息交流。
- DateNode和NameNode都有一个集群的ID号存放在各自的VERSION文件中,两者就是通过这个集群的ID来互相绑定的。
- 每次格式化NameNode都会重新生成新的集群ID。
我们先看正常情况下的DataNode和NameNode(默认是/tmp/hadoop-{user.name}目录)
我们修改了配置到/opt/module/hadoop-2.7.7/data/tmp
在这个目录下有两个子目录:dfs、mapred,进入dfs可以看到两个目录:data和name分别对应DataNode和NameNode。
两个目录下各自有个current目录,里面就有一个VERSION文件


当我们第一次启动DataNode和NameNode的时候,DataNode会从NameNode中拷贝一份集群ID为自己设置,然后两者就可以愉快的通信了。
可是当你将NameNode格式化之后,新的NameNode和DataNode的集群ID不一致,两个人互相不认识,无法通信,并且两者只能有一个处于运行状态!
启动YARN并运行MapReduce程序
先回顾Yarn的组成结构:
- ResourceManager(大哥)
- NodeManager(小弟)
一下的配置就是围绕这两个部分展开:
配置集群
-
配置yarn-env.sh,修改JAVA_HOME
先去掉注释,然后修改
-
配置yarn-site.xml
<property> <name>yarn.nodemanager.aux-servicesname> <value>mapreduce_shufflevalue> property> <property> <name>yarn.resourcemanager.hostnamename> <value>hadoop101value> property>说mapreduce_shuffle:shuffle机制可谓说是Hadoop的核心机制,也就是常说的洗牌机制
说hostname:由于我们Linux和Windows的hosts文件中就配置了映射,所以直接使用就可以。
在官方的默认配置中有很多端口都被其使用,等一下一个个看:

-
配置mapred-env.sh 修改JAVA_HOME
步骤和上面的一致。
-
配置mapred-site.xml.template
-
先重命名为mapred-site.xml
-
然后配置以下内容
<property> <name>mapreduce.framework.namename> <value>yarnvalue> property>这里的配置信息,官方给出的默认配置是local

并且明确说明这个值可以是
local,classic,yarn其中之一。
之前MapReduce的过程全部在Linux本地主机上运行,现在改为在yarn上运行我们可以看到更多过程以及信息。
-
启动集群
既然HDFS启动是Name Node和Data Node,那Yarn启动就是Resource Manager和Node Manager,启动文件依然在sbin目录
-
启动Resource Manager
sbin/yarn-daemon.sh start resourcemanager -
启动NodeManager
sbin/yarn-daemon.sh start nodemanager -
使用jps查看是否启动成功

-
现在我们就可以去访问那些端口咯!!在此之前先检查HDFS是不是正常工作。
实测了一下,并查看了这两个进程管理的端口,最终只有8088可以访问
由于这个设置:就只能访问8088端口的http请求:

你可在yarn-site.xml修改这个配置的值为HTTPS_ONLY,就可以使用8090端口访问了!
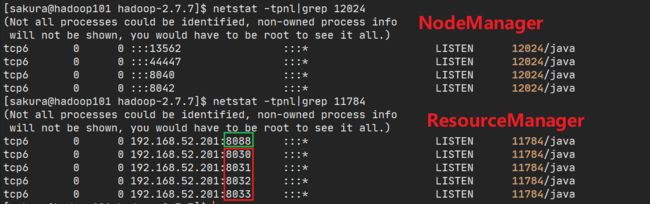
-
玩完了,我们来看看这个页面:
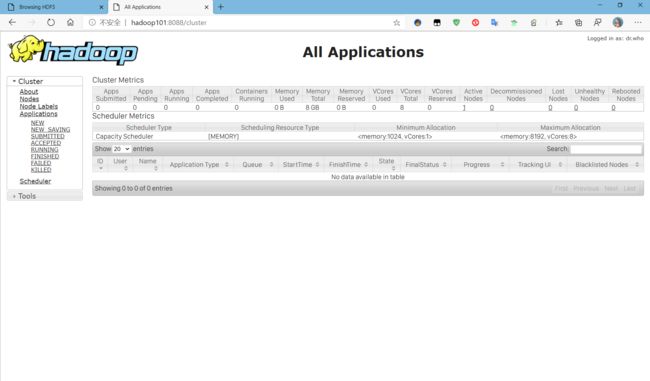
我们就是通过这个页面来查看我们任务的执行情况的,我们现在执行一个任务试试看。
这个过程相对与我们在本地主机上运行要慢一些,你会明显看到三个过程:

同时网页上这个进度条也随之变化从0到一半到结束。
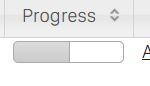

我们来看看详细的信息:


后面有个
History可以更加清楚看到整个Job的运行环境和过程,但是目前是不能访问的,需要配置历史服务器。
配置历史服务器
在官方给出的默认配置中,有这样两个选项:

分别对应历史服务器的地址以及web服务的地址。
-
配置mapred-site.xml
<property> <name>mapreduce.jobhistory.addressname> <value>hadoop101:10020value> property> <prpperty> <name>mapreduce.jobhistory.web.addressname> <value>hadoop101:19888value> prpperty> -
启动历史服务器
sbin/mr-jobhistory-daemon.sh start historyserver -
jps查看进程

-
测试访问:
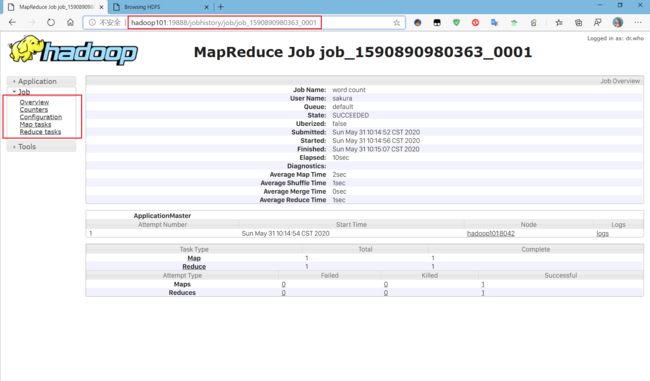
整体是没有问题的,来看看这几个标签页到底能看到些什么:
-
上图就是Overview,相当于是一个整体预览,job的最基本的数据、
-
Counters:则是对Job执行过程一些统计信息:
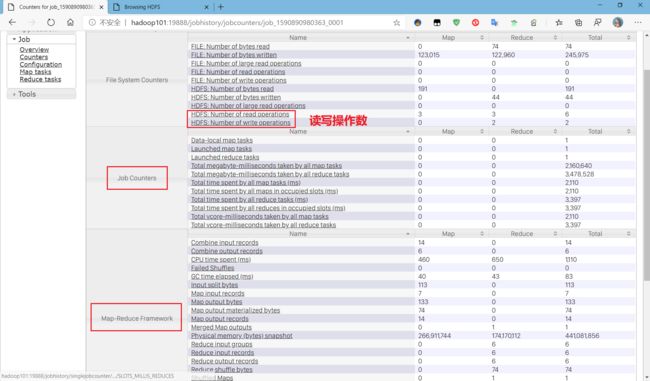
-
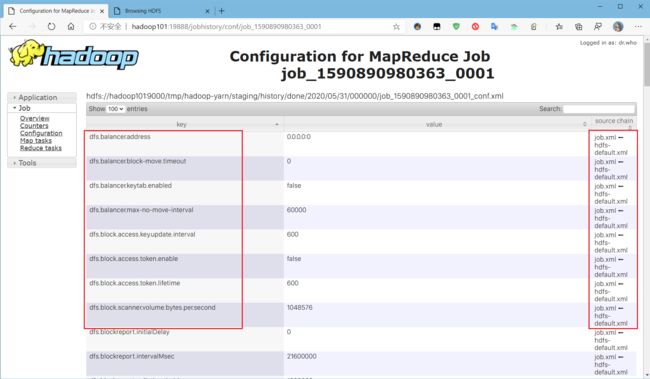
Configuration:这里查看一些Job运行时的配置信息:
-
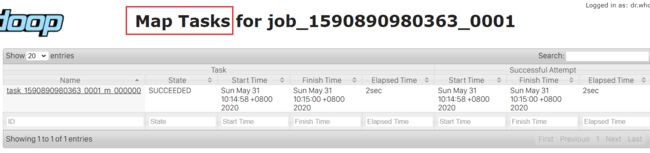
Map task:map阶段的执行状况:
-
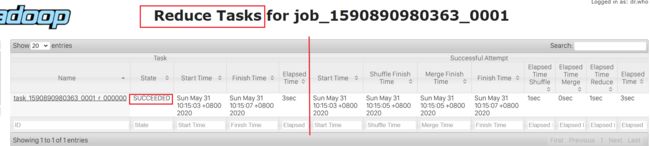
Reduce task:reduce阶段的执行状况
-
tools:一些数据的查看工具:

-
Application里面的job选项可以看到所有的历史执行Job:

-
在Overview界面可以看到一个logs的选项,但是点过去好像并没有什么作用:
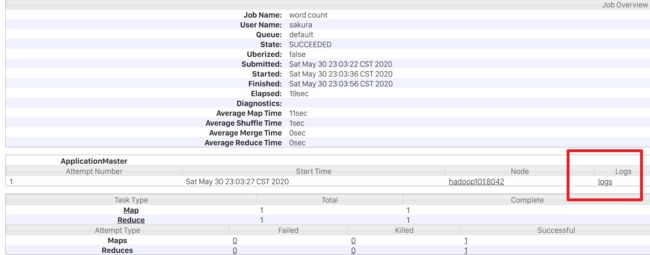
提示信息是:
Aggregation is not enabled. Try the nodemanager at hadoop101:44447:未启用聚合?
这个日志就是接下来要配置的日志的聚集
日志的聚集配置
什么是日志的聚集?
应用运行完成以后,将程序运行日志信息上传到HDFS体统。
好处
便于查看程序的运行过程和状态,方便调试。
注意:开启日志聚集功能,要先关闭NodeManager、ResourceManager、HistoryServer
-
关闭三个进程
sbin/yarn-daemon.sh stop resourcemanagersbin/yarn-daemon.sh stop nodemanagersbin/mr-jobhistory-daemon.sh stop historyserver最后使用jps检查确定全部关闭。
-
配置yarn-site.xml
```xml
yarn.log-aggregation-enable
true
yarn.log-aggregation.retain-seconds
604800
```
重新启动NodeManager、ResourceManager、HistoryServer
官方默认配置:

- 重新启动一个job
查看日志:

这里就是程序运行输出的日志,当执行过程出错可以通过查看这个日志来进行排错。
完全分布式模式(重点!!)
准备工作
-
克隆三台客户机,修改静态IP,配置host,修改主机名。
静态IP:/etc/sysconfig/network-scripts/ifcfg-xxx
修改主机名字:/etc/sysconfig/network
host:/etc/hosts
-
关闭各个主机的防火墙服务,以及自启动服务。
关闭防火墙:systemctl stop firewalld.service
关闭防火墙服务自启动:systemctl disable firewalld.service -
各个主机配置JDK和Hadoop
编写集群分发脚本xsync
-
scp:安全拷贝(SecureCopy)
可以实现服务器之间的数据拷贝。
使用语法:
scp -r $pdir/$fname $user@$hostname:$pdir/$fname不仅可以从当前主机推到目标主机,也可以从主机拉取目标主机中的文件,但是所有操作都要注意文件操作权限问题。
-
rsync远程同步工具
主要用于备份和镜像,速度快,避免复制相同的内容,支持符号链接。
rsync只针对有差异的文件做更新。
使用语法(于scp类似):
rsync -rvl ...选项说明:
- r:递归
- v:显示复制过程
- l:拷贝符号链接
-
集群分发脚本xsync
需求问题:循环复制文件到所有节点的相同目录上,例如当集群中某个主机的某一个配置文件产生了变化,我希望将这个变化同步到所有的主机上,就需要用到集群分发脚本。
-
首先我们在/home/sakura目录下创建一个bin目录
这里要确保环境变量PATH中包含了家目录中的bin文件夹,否则是无法作为全局命令使用的。
不过可以在/usr/local/bin下创建

-
创建一个shell脚本——xsync(命名随意,相当于命令名)
-
脚本代码:
#!/bin/bash # 获取输入参数个数,若个数为0直接退出 pcount=$# if [ pcount==0 ];then echo no args exit; fi # 获取参数中的文件名 p1=$1 fname=`basename $p1` echo fname=$fname # 获取上级目录到绝对路径 pdir=`cd -P $(dirname $p1); pwd` echo pdir=$pdir #获取当前用户名 user=`whoami` #循环分发 for((host=103;host<105;host++)); do echo ------------------hadoop$host----------------- rsync -rvl $pdir/$fname $user@hadoop$host:$pdir done注意:这里循环分发中采用的主机名拼接,务必保证本机上已经配置了host!
-
集群配置
| hadoop102 | hadoop103 | hadoop104 | |
|---|---|---|---|
| HDFS | NameNode、DataNode | DataNode | SecondaryNameNode、DataNode |
| YARN | NodeManager | ResourceManager、NodeManager | NodeManager |
NameNode和SecondaryNameNode不能在同一主机上,两者内存占比是1:1
ResourceManager与NameNode、2nn在同一主机上
在伪分布式的基础上,Hadoop102配置
-
core-site.xml配置修改:
中将文件系统(
fs.defaultFS)的主机地址改为hadoop102 -
hdfs-site.xml配置修改:
-
副本数量(
dfs.replication)修改为3 (默认配置) -
指定Hadoop集群的辅助名称节点(SecondaryNameNode,2nn)
<property> <name>dfs.namenode.secondary.http-addressname> <value>hadoop104:50090value> property>
-
-
yarn-site.xml配置修改:
ResourceManager的主机名(
yarn.resourcemanager.hostname)改为hadoop103 -
使用我们写的集群分发脚本,将修改的配置文件同步到其他主机上

集群单点启动
首先我们要把NameNode进行格式化:
- jps查看确认NameNode和DataNode均已关闭
- 删除所有节点上的data、logs目录
- 使用
hdfs namenode -format完成格式化
最后启动测试能否正常访问。
现在问题来了:每次单个节点单个节点启动,步骤繁琐且效率低下,有没有什么办法能让集群群起呢?
SSH免密登录
使用ssh可以连接到其他的主机/服务器,Xshell连接服务器就是使用的SSH,默认端口是22;
Linux下SSH具体使用:

但是登录过程是需要密码的,我们可以进行操作,让其免密码登录
免密登录的原理

前提知识:==所有通过私钥加密的数据,只能使用 对应的公钥进行解密,相反同理,通过公钥加密的数据,只能使用对应的私钥进行解密。==这样就保证数据在传输过程中安全性。
-
切换到家目录的隐藏目录.ssh下
-
生成密钥对
ssh-keygen -t rsa,然后三次回车- -t 指定密钥类型,默认是 rsa ,可以省略。
生成的私钥和公钥匙


-
将公钥拷贝到hadoop103,104包括本机的Authorized_keys中
ssh-copy-id hadoop102ssh-copy-id hadoop103ssh-copy-id hadoop104使用相同的步骤,在103、104上生成密钥,并拷贝。
-
由于NameNode在102主机上,需要对root用户进行相同的操作
可能root目录下没有.ssh目录,可以直接生成密钥对就会自动生成.ssh目录,然后将公钥分发。
授权完毕后,每个主机的.ssh目录下有这样几个东西:

- authorized_keys:是经过授权允许的公钥
- id_rsa、id_rsa.pub: 是生成的成对的私/公钥
- known_host: 是访问过的主机的公钥
现在使用ssh 连接其他服务器,就免去了输入密码的步骤,下面就可以开始我们集群群起的脚本编写了!
群起集群
-
jps确保所有的进程是关闭状态
-
修改NameNode主机的hadoop目录中
etc/hadoop/slaves文件,添加所有DataNode的主机名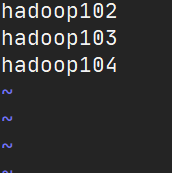 这里是不允许有任何的空格和空行出现的!
这里是不允许有任何的空格和空行出现的!修改完成,分发同步到其他主机上。
-
在NameNode主机上执行
start-dfs.sh,一键启动HDFS的组件
stop-dfs.sh可以全部停止。 -
启动完成以后,对照我们最开始规划的表,进行比对,检查是否一致。
-
然后在ResourceManager所在主机使用
start-yarn.sh启动YARN的组件,注意!!一定是在ResourceManager的主机上启动!
总结:
相比于集群的单点启动,使用群起,是按照模块进行启停。
start/stop-dfs.sh和start/stop-yarn.sh分别用于启停HDFS和YARN模块。关于之前说的为什么slaves文件中严格要求不能出现多余的空格和空行,是因为在这些模块启停脚本中会使用从这个slaves文件中读取信息:
一旦出现多余的空格和空行就会导致数据解析出错,从而导致启停出错。

crond系统定时任务
参考Linux实操篇第六节:任务调度
集群时间同步
思路:找一台机器作为时间服务器,所有的服务器与这台服务器定时进行时间同步。
时间服务器配置:
-
检查ntpd(网络时间协议)是否安装
rpm -qa|grep ntp关于CentOS 8.0不支持ntpd,使用chrony搭建时间服务器
chrony和ntpd都是对ntp协议的实现,只不过更新的chrony取代了ntpd软件
参考博客
https://blog.csdn.net/yiwangC/article/details/104661393/
-
修改ntp配置文件
- 授权所在网段上所有机器都能从这台机器上查询和同步时间
- 集群在局域网中,不使用其他互联网上的时间
- 当时间服务器丢失网络连接,仍然可以采用本地时间作为时间服务器为集群中其他节点提供时间同步。
-
修改/etc/sysconfig/ntpd文件
让硬件和软件的时间一起同步
-
重启ntpd服务
-
设置开机自启动
其他节点配置
-
编写定时任务,让机器每十分钟与时间服务器同步一次时间
crontab -e*/10 * * * * /usr/sbin/ntpdate hadoop102 -
修改本机时间,测试是否能够同步成功
使用chrony搭建ntp服务器
参考阅读:
https://blog.csdn.net/Linuxprobe18/article/details/80460068
https://liumiaocn.blog.csdn.net/article/details/88421217
-
检查是否安装chrony
未安装的话使用yum install chrony安装即可
-
设置自启动
systemctl enable --now chronyd -
查看chronyd.service状态
systemctl status chronyd.service -
修改配置文件/etc/chrony.conf
# pool 2.centos.pool.ntp.org iburst 这行注释掉!这是默认的时间同步的服务器 > 编写我们自己集群的时间服务器,表示从哪里同步时间(其他节点) server hadoop102 iburst > 增加配置,允许(allow)/禁止(deny)哪些主机访问本服务器的时间服务(时间服务器) allow 192.168.52.0/16 # 在生产环境中,其网络都是内网结构,那么内网如何保证服务器之间的时间同步呢? > 使用本地时间(时间服务器) server hadoop102 iburst > 即使没有同步到网络,也允许其他服务器进行时间同步 local stratum 10 -
防火墙配置(时间服务器)NTP使用123/UDP端口协议
firewall-cmd --add-service=ntp --permanent *#永久允许对外提供NTP时间服务* firewall-cmd --reload -
配置/etc/sysconfig/chronyd
SYNC_HWCLOCK=yes:开启软硬件时间同步 -
开启ntp时间同步
timedatectl set-ntp true -
查看同步源状态:
chronyc source -v,*号表示连接正常 ?表示未连接,或异常 -
手动同步时间
chronyc -a makestep
时间服务器配置重启:
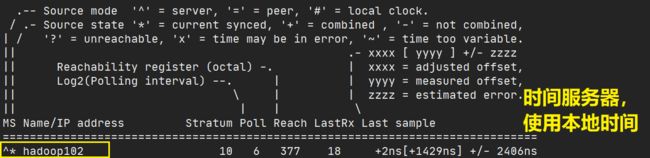

查看两台主机的时间:

Hadoop源码编译
闲的蛋疼?为什么编译源码?
一般hadoop需要在自己的linux环境下重新将源代码编译一下,为什么hadoop要自己再次编译一下,网上很多都是说:官网提供编译好的只有32位的,没有提供64位的,其实这种解释是错的。官网可下载的也有编译好的64位。
那为什么要大费周折的重新编译?主要是要重新编译本地库(Native Libraries) 代码(Linux下对应[.so]文件,window下对应[.dlI]文件),也就是编译生成linux下的[.so] 文件。
——摘自博客hadoop搭建时为什么最好重新编译源码的原因
前提工具准备:
-
一台干净的CentOS操作系统
-
Hadoop源码、jdk、maven、ant、protobuf(版本2.5.0) 的tar包

网上都能找到,动动手!
工具环境安装具体步骤
-
安装JDK,配置环境变量
-
解压安装Maven
-
解压到/opt/module目录
-
配置环境变量
# MAVEN_HOME export MAVEN_HOME=/opt/module/apache-maven-3.6.3 export PATH=$PATH:$MAVEN_HOME/binsource /etc/profile -
验证是否安装成功:mvn -version
-
后续还要对maven仓库进行配置修改,参加JavaWeb中修改Maven仓库
-
-
ant解压安装
-
环境变量
# ANT_HOME export ANT_HOME=/opt/module/apache-ant-1.9.15 export PATH=$PATH:$ANT_HOME/binsource /etc/profile
-
验证:ant -version
-
-
安装glibc-header和g++
- yum install glibc-header
- yum install gcc-c++
-
安装make和cmake
- yum install make
- yum install cmake
-
解压安装protobuf
-
进入其根目录/opt/module/protobuf-2.5.0/
-
执行以下命令:
-
./configure
(如果没有这个文件(github上下载的解压是没有这个文件的),去找一个靠谱的重新安装)
-
make
-
make check
-
make install
-
ldconfig
-
-
修改环境变量
# LD_LIBRARY_PATH export LD_LIBRARY_PATH=/opt/module/protobuf-2.5.0 export PATH=$PATH:$LD_LIBRARY_PATHsource /etc/profile
-
验证安装:protoc --version
-
-
安装openssl库
- yum install openssl-devel
-
安装ncurses-devel库
- yum install ncurses-devel
编译源码
-
解压源码到/opt目录
-
使用Maven执行编译命令
mvn package -Pdist,native -DskipTests -Dtar过程漫长,肯需要重复执行
-
查看成功生成的64位hadoop包在/opt/hadoop-2.x.x-src/hadoop-dist/target目录下
由于包很多,需要现下所以需要等待一段时间。
编译完成:(我tm倒腾了半天!!!)

关于查看Hadoop的版本是32位还是64位
进入/opt/module/hadoop-2.7.7/lib/native/目录,然后里面有这个文件
使用
file libhadoop.so.1.0.0,查看结果:
这里显示就是64位,x86-32就是32位
