Redis学习记录2 Redis五种基本数据结构
Redis五种基本数据结构
- String类型的使用场景:(针对于实体对象)
- 1. 单值缓存
- 2. 对象缓存
- 3. 分布式锁
- 4. 计数器
- 6. Web集群session共享
- 7. 分布式系统全局序列号
- Hash的使用场景
- 1. 对象缓存
- 2. 电商购物车
- Hash结构的优缺点:
- List类型的使用场景
- 1. 实现消息列表的消息流底层(如微博的公众号和微信公众号的消息)--小用户量的粉丝才可以这样推送消息
- SET类型的使用场景
- 1. 微信里面的抽奖活动
- 2. 微博的点赞,收藏,标签
- 3. 集合操作 之微信微博的关注模型
- ZSet集合
- 1. ZSet集合操作实现排行榜
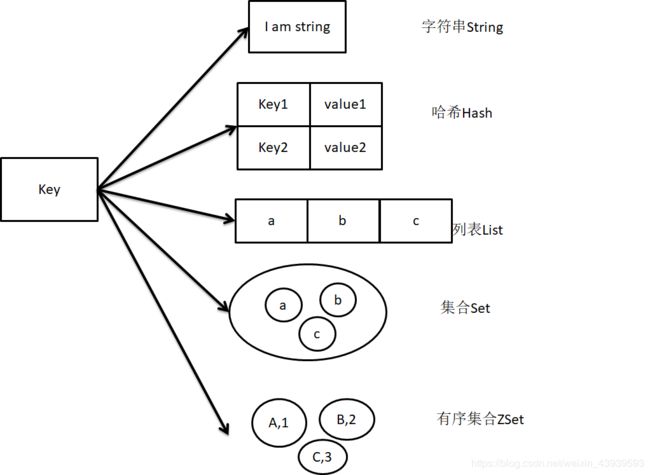
在学习String,Hash基本数据结构之前,我们先来了解一下Redis的五种基本类型的框架。
五种类型的框架
String类型的使用场景:(针对于实体对象)
1. 单值缓存
set key value //存储值
get key // 获取值

2. 对象缓存
除了可以set和get存储和获取键值对以外 还可以利用 mset以对象的方式存储和获取信息。mset,mget批量的存储与取出
1. set user:1 value(json格式数据) //这里就不详细展开了
2. mset user:1:name litianhao user:1:balance 65 //存储对象多个数据
mget user:1:name user:1:balance //获取对象多个数据
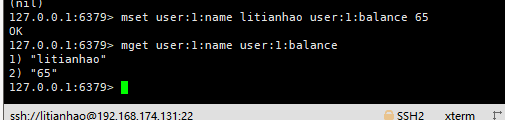
对象缓存mset的优点是修改的时候可以只针对对象中的一个key值进行操作,简单快捷。
3. 分布式锁
setnx key value
将key的值设为value,当且仅当key不存在。若给定的key已经存在,则setnx不做任何操作
setnx product:10001 true //返回1代表获取锁成功
setnx product:10001 true // 返回0代表获取锁失败
执行业务操作
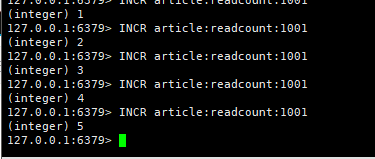
4. 计数器
博客或者帖子的阅读数,都可以用String的计数器来实现
INCR article: readcount: {文章id}
GET artical:readcount:{文章id}
通过get我们也可以看到它的浏览数是多少
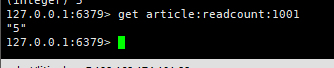
总结:这里就是我们微信里面或者博客阅读数的底层实现吧,每一次有用户打开文章进行阅读,在底层的时候就会调用一次我们的原子加操作,这样的话,我们文章的阅读数就会增加,底层其实是依靠redis的String应用场景中的计数器来完成的。
6. Web集群session共享
Spring session + redis实现session共享
7. 分布式系统全局序列号
INCRBY orderld 1000 批量生产序列号提升性能`,就是原子计数器实际上
Hash的使用场景
Hash的常用操作
HSET key field value 存储一个哈希表key的键值
HSETNX key field value 存储一个不存在哈希表key的键值
HMSET key field value [field value..] 存一个哈希表key中存储多个键值对
HGET key field 获取哈希表key对应的filed键值
HDEL key field [field ..] 删除哈希表key中的field键值
HLEN key 返回哈希表中key中的filed的数量
HGETALL key 返回哈希表key中所有的键值
1. 对象缓存
对象缓存除了用String以外,还可以用哈希的批量操作进行对对象的存储,接下来就是用HMSET做对象的批量操作。
HMSET user {userid}:name litianhao {userid}: balance 65 // 用户字段 名称 字段 名称
HMSET user 1:name litianhao 1:balance 65 // 例子
HMGET user 1:name 1:balance

2. 电商购物车
- 以用户id作为key
- 商品id作为field
- 商品数量作为value
购物车的操作

1 添加商品 hset card:1001 10088 1 往id为1001的用户的购物车中添加商品号为10088的商品1件
2 增加数量 hincrby card:1001 10088 1
3 商品总数 hlen card:1001
4 删除商品 hdel card:1001 10088
5 获取购物车中所有的商品 hgetall card:1001
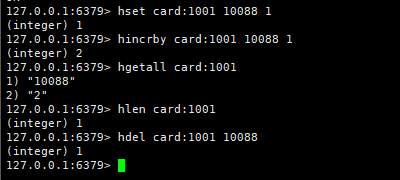
注意:Redis中存储的是商品购物车中的id,不能存储商品的名称,因为redis的内存是有限的,最终获取到商品名称时通过redis中的商品id在通过ajdx异步的去获取商品的名称。
Hash结构的优缺点:
优点:
- 同类型的数据归类存储,方便管理。对数据的管理更加集中,一个用户表都可以放在一个key下面
- 相比String类型的操作消耗内存,cpu更小
- 相比String类型更节省存储空间
缺点:
- 过期的功能不能使用在field上,只能用在key上。
- Redis集群架构下不适合大规模使用
Redis集群: 有很多很多的redis节点,一个user(key)通过一些哈希的算法映射到一个节点上,redis集群就是多个redis数据分片,有可能会出现一个节点集群占用的容量非常非常的大,甚至几个TB,其它的几点很少,有可能不到一个G。如果在集群的架构下Hash涉及到不是特别好的情况下,会导致数据倾斜,而且性能会大幅度降低,甚至宕机(redis由于是单线程)
List类型的使用场景
List的使用操作:
LPUSH key value [value..] // 将一个或多个值value插入到key列表的表头
RPUSH key value [value..] // 将一个或多个值value插入到key列表的表尾
LPOP key // 移除并返回key列表的表头元素
RPOP key // 移除并返回key列表的尾元素
LRANGE key start stop // 从 start到stop的消息取出来
BLPOP key [key..] timeout //从key列表表头弹出一个元素,若列表表头没有元素,阻塞等待timeout秒,如果为0,一直等待
BRPOP key[key..] timeout // 从key列表表尾弹出一个元素,若列表中没有元素,则阻塞等待timeout秒,如果为0,一直等待
List实现我们常用的数据结构:
Stack(栈) = LPUSH + LPOP 可以实现一个先进后出的栈结构
Queue(队列) = LPUSH + RPOP 可以实现一个先进先出的队列
Blocking MQ(阻塞队列) = LPUSH + BRPOP
1. 实现消息列表的消息流底层(如微博的公众号和微信公众号的消息)–小用户量的粉丝才可以这样推送消息

上面的含义是向id号10086推送信息"123",然后接着向10086推送信息"456",最终获取id10086的list列表中的从后到前的信息列表0 1
SET类型的使用场景
1. 微信里面的抽奖活动
主要涉及到:
- 点击参与抽奖加入到集合 SADD key {userid}
- 查看参与抽奖所有用户 SMEMBER key
- 抽取count名中奖者加入另一个集合 SRANDMEMBER key [count] / SPOP key [count]
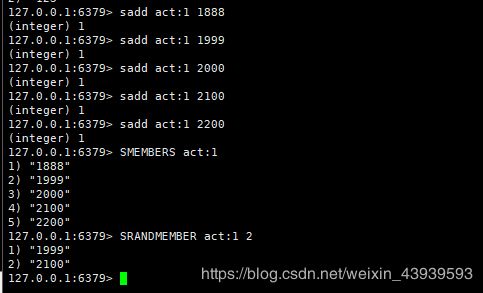
现在有抽奖活动act:1,现在参与的用户有 1888,1999,2000,2100,2200,然后SMEMBERS获取所有的用户id,然后SRANDMEMBER act:1 2 的意思是随机抽取act:1活动的两名幸运者加入获奖集合。
2. 微博的点赞,收藏,标签
-
点赞
SADD like:{消息id} {用户id}
-
取消点赞
SREM like:{消息id} {用户id}
-
检查用户是否点过赞
SISMEMBER like:{消息id} {用户id}
-
获取点赞的用户列表
SMEMBERS like:{消息id}
-
获取点赞的用户数
SCARD like:{消息id}
3. 集合操作 之微信微博的关注模型
集合的基本操作:
set1 = {a,b,c}
set2 = {b,c,d}
set3 = {c,d,e}
SINTER set1 set2 set3 -> {c} 求交集
SUNION set1 set2 set3 -> {a,b,c,d,e} 求并集
SDIFF set1 set2 set3 ->{a} 求差集 set1 - (set2 + set3)
社交中的用户与用户之间的关注模型。无非关注的对象不同
- 新浪微博或者微信共同关注的人,共同的粉丝
- 淘宝店铺的共同关注
- 美团的商家关注
- 滴滴打车的司机关注,路线的关注
- 电商商品的筛选
注意:但是有些大的明星粉丝的关注或者粉丝的集合会非常的庞大,所以针对于这些大v整个后端的实现会和我们普通人不一样,因为它的数据量巨大,所以不太利于集合的运算,因为集合的运算需要取出所有的对象元素进行交集并集运算,所以在他们的后端其实是特殊化,或者机器都是单独部署的。
ZSet集合
1. ZSet集合操作实现排行榜
- 点击新闻
- 展示当日排行top
- 微博微信的热搜与排行榜
还比如
微博、微信、陌陌 附近的人
微信摇一摇 附近的人
滴滴打车 附近的车
美团 附近的餐馆