Oracle PLSQLl的多线程编程架构 存储过程中使用多线程 定时任务 作业调度计划 JOB SCHEDULE
基于Oracle plsql的多线程编程架构 (附存储过程)
1年前 1413
作者介绍
冯守东,北京科讯华通科技发展有限公司高级项目经理。超12年Oracle开发及管理经验,多年运营商和政府企业级系统运维经验,曾获得东软最佳设计方案奖。熟悉Weblogic、TUXEDO、IBM WAS等相关中间件运维。熟悉MySQL、DB2、Informix等其他开源或商业数据,以及Openstack、Hadoop相关生态系统、网站架构设计等。
引言
1 文档编制目的
在日常编程范围内有很多大计算量的存储过程,在业务系统中使用Java实现多线程往往会有参与计算的任务不能均匀分配、不能完全发挥数据库服务器的高端性能,代码实现起来门槛较高,比较麻烦。因此,本文档将通过DIY方式介绍如何在Oracle数据库服务器实现存储过程的并行处理。
2 背景
-
有一个很大的计算过程,参与计算的对象非常多。例如数据固化、应收核定等。
-
要用PL/SQL逐行处理,当然这这样做会有大量的读取和DML操作。
-
我们使用一台多CPU的数据库服务器,并且有大量磁盘空间。
-
我们发现操作系统/SQL并不是非常容易扩展的,它只使用了1个CPU,并没有利用整个机器。
-
由于我们使用固有的单线程程序来处理数据,ORACLE并行查询不可用!
-
“一个人的活多个人做”并行处理,将固有的任务/数据分解成N个不重叠的组,同时开始PL/SQL子程序N个拷贝。
3 范围
本文档适用于所有使用Oracle 10g的项目,系统吞吐量大,有一定执行时间限制的应用场合。
4 词汇表
| 词汇名称 |
词汇含义 |
备注 |
| DBMS_SCHEDULER |
Oracle任务调度器 |
只有Oracle 10g支持新特性 |
| READ LOCK |
Oracle行排他锁 |
Oracle 任何版本 |
| Autonomous Transactions |
Oracle自治事务 |
Oracle 任何版本 |
| Dynamic SQL |
Oracle 动态SQL |
Oracle 任何版本 |
总体架构设计
1
设计原则和方法
原则:
-
提供一个脱离业务、通用性强的功能组件。
-
易于复用,代码修改少,可配置满足不同要求。
-
对控制重复执行有所考虑。
-
组件提供人性化的客户交互界面,解决进度情况展示的问题。
-
能有一个实现和效率之间的平衡。
方法:
此组件中的并行执行遵循了几乎相同的逻辑。通常可以将某个大“任务”划分为较小的部分,并且并发地执行各个部分。例如,如果需要计算一大批结果并把数据保存到数据库中,那么完全可以建立4 个或更多并行会话(P001~P004)来一起执行存储过程,任务的分派有一个任务分派器来做,分派器可以按照每个进程的负载情况均匀的分派任务。每个会话分别调用预定义的业务过程来执行分派器分派的任务。当需要提交处理结果的时候,可以在每个业务过程内进行保存。
此组件作为一种实现架构,可以使一些要求吞吐量大、执行效率高的的操作得到大幅改善,使其能够呈数量级提高。由于此架构对系统资源要求较高,通常情况下应该在非高峰期而且有足够资源的情况下之用。
2 系统整体架构
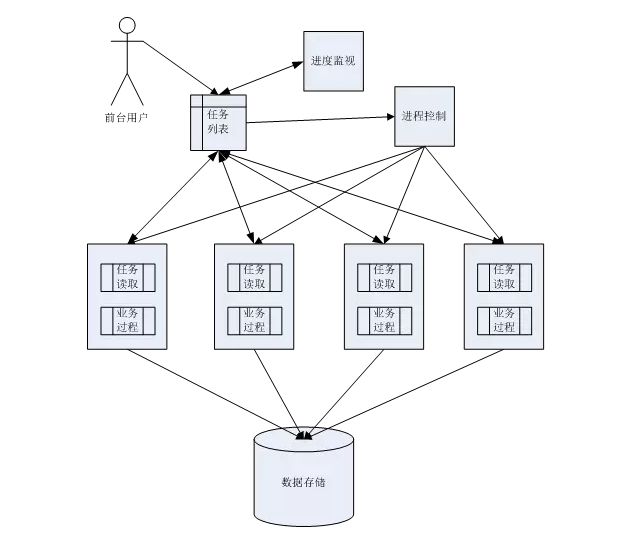
3 系统级组件
DBMS_SCHEDULER是Oracle 10G中新增的一个包,与老版本的DBMS_JOB包相比,DBMS_SCHEDULER有很多新特性。Oracle 10g引入DBMS_SCHEDULER来替代先前的DBMS_JOB,在功能方面,它比DBMS_JOB提供了更强大的功能和更灵活的机制。
DBMS_JOB这个程序包存在的问题是它只能够处理 PL/SQL 代码段,即仅能处理匿名程序块和存储程序单元。它不能在数据库外部处理操作系统命令文件或可执行文件中的任何东西。
为此,您将不得不求助于操作系统调度实用工具。另外DBMS_JOB所生成任务进程一旦生成就在数据库中一直有效,不能在任务结束后自动终止。
DBMS_SCHEDULE是直接在数据库内部的一个作业调度实用程序,强大到足够处理所有类型的作业,而不只是 PL/SQL 代码段。它可以在处理任务执行结束后自动终止。最好的一点是它是数据库自带的,无需任何额外的成本,这样我们在实现上直接使用即可。
4 流程图各部分说明
-
前台用户:主要是进行程序调度,主要是任务是把我程序执行时机。
-
任务列表:通过一个普通表实现,该表中主要包括了业务过程执行过程中所需要的入参,参数的形式为‘|’分隔的字符串。同时附加了异常及进度信息。该表是由程序开发人员根据具体的业务定义结构并生成入参数据。
-
进程控制:根据系统参数或业务参数调用DBMS_SCHEDULER生成对应个数的服务进程。依据当前进程执行情况,控制任务的重复执行。当出现紧急情况时终止所有服务进程。
-
任务读取:通过ORACLE的自制事务及锁特性,实现任务读取的一致性,即每次服务进程处理一行任务数据的时候,不被其它的服务进程重复读取。
-
业务过程:该部分同样由程序开发人员根据具体业务类型开发存储过程。该过程根据传入的过程名称和参数个数动态调用业务存储过程。
-
服务进程:ORACLE自动管理的进程,服务进程的数量取决于“进程控制”创建的进程数。服务进程主要工作1、通过“任务读取”获得“业务过程”的入参。2、调用“业务过程”生成业务数据。
-
数据存储:业务过程处理之后生成的结果。
-
进程监视:“前台用户”调用之后任务执行的监控,包括正在执行情况及最终执行结果。
系统接口设计
1 程序开发接口设计
此组件向开发人员公布3个系统接口,1个调试接口。
-
PKG_多线程服务.PRC_进程控制
入参:
PRM_PROGRAM 即要调用的业务过程名称。
PRM_PARMCOUNT 即对应业务过程的参数个数
-
PKG_多线程服务.PRC_进程停止
直接终止后台正在运行的多线程服务。
-
PKG_多线程服务.PRC_调试使用
入参:
PRM_PROGRAM 即要调用的业务过程名称。
PRM_PARMS 即对应业务过程的参数字符串。
因为是动态调用存储过程,所以SC01中的参数个数必须同业务过程个数严格对应,提供此方法主要是让开发人员调试使用。
-
任务列表SC01
开发人员要压入的任务,即业务过程的参数。参数必须以‘|’分隔,并且保证在多线程服务运行的过程中,其他模块不能对SC01进行DML操作,为实现其他模块不能操作SC01,在任何DML操作之前必须执行一个语句如下:
SELECTCOUNT(*)
INTO N_EXISTS
FROM USER_SCHEDULER_JOBSS
WHERE S.STATE = 'RUNNING'
AND S.JOB_ACTION = 'PKG_多线程服务.PRC_服务进程';
综上所述执行一个ORACLE多线程服务,开发人员只需要做一项工作即压入正确SC01参数,然后直接调用即可。
2 用户展示接口设计
前台查询SC02、SC03视图
数据库结构设计
1 数据表设计
描述:模块任务分派表Sc01
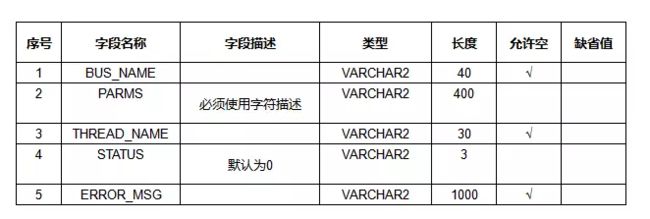
2 视图设计
-
描述:运行监视试图Sc02
CREATE OR REPLACE VIEW SC02 AS
SELECT S.JOB_CREATOR 现场创建用户,
S.JOB_NAME 线程名称,
S.JOB_ACTION 过程名称,
S.last_start_date 启动时间,
S.COMMENTS 备注,
(SELECT COUNT(*)
FROM SC01
WHERE THREAD_NAME = lower(S.JOB_NAME)
AND STATUS = '0') 未处理数,
(SELECT COUNT(*)
FROM SC01
WHERE THREAD_NAME = lower(S.JOB_NAME)
AND STATUS = '1') 运行成功数,
(SELECT COUNT(*)
FROM SC01
WHERE THREAD_NAME = lower(S.JOB_NAME)
AND STATUS = '-1') 运行失败数
FROM USER_SCHEDULER_JOBS S
ORDERBY S.JOB_NAME;
-
描述:运行结果监视试图sc03
CREATE OR REPLACE VIEW SC03 AS
SELECT S.OWNER 用户名,
S.JOB_NAME 线程名称,
S.STATUS 线程状态,
S.LOG_DATE 日志时间,
S.ACTUAL_START_DATE 线程实际运行时间,
S.RUN_DURATION 线程持续运行时间,
S.SESSION_ID 会话ID,
S.SLAVE_PID 进程ID,
S.ADDITIONAL_INFO 线程备注信息,
(SELECT COUNT(*) FROM Sc01 WHERE thread_name = lower(S.JOB_NAME) ANDstatus = '0') 未处理数,
(SELECT COUNT(*) FROM Sc01 WHERE thread_name = lower(S.JOB_NAME) ANDstatus = '1') 运行成功数,
(SELECT COUNT(*) FROM Sc01 WHERE thread_name = lower(S.JOB_NAME) ANDstatus = '-1')运行失败数
FROM USER_SCHEDULER_JOB_RUN_DETAILS S
ORDER BY S.JOB_NAME;
3 数据安全性
所需要系统的权限如下:
grant manage scheduler to AHSIMIS;
grant create any job to AHSIMIS;
尚需解决的问题
如果是RAC环境,程序尚不能跨实例运行。
原文发布时间为:2017-01-03
本文来自云栖社区合作伙伴DBAplus
架构 Oracle SQL 线程 数据库 多线程 编程 存储过程
作者

稀奇古怪
TA的文章
- Oracle Compute Cloud Service介绍
- 一个执行计划异常变更引发的Oracle性能诊断优化
- MySQL索引设计背后的数据结构及算法详解
相关文章
- PLSQL Developer软件使用大全
- PLSQL Developer软件使用大全
- PLSQL_Oracle Exception异常分类、异常抛出、异常处理、异常传播(概念)
- Oracle之PL/SQL编程_流程控制语句
- think in java interview-高级开发人员面试宝典(九)
https://m.aliyun.com/yunqi/articles/80140
存储过程中是否有多线程的概念[复制链接] |
| IT渔夫
论坛徽章: 23
|
电梯直达
|
|
|
||
| 使用道具 举报 回复 |
||





 发表于 2016-3-2 10:07
发表于 2016-3-2 10:07 
| IT渔夫
论坛徽章: 23
|
2#
|
|
| 使用道具 举报 回复 |
||
| 隐剑埋名
认证徽章
论坛徽章: 10
|
3#
|
|
| 使用道具 举报 回复 |
||




| test_100
认证徽章
论坛徽章: 16
|
4#
|
|
| 使用道具 举报 回复 |
||






| IT渔夫
论坛徽章: 23
|
5#
|
|
| 使用道具 举报 回复 |
||

| newkid
论坛徽章: 531
|
6#
|
|
| 使用道具 举报 回复 |
||

| IT渔夫
论坛徽章: 23
|
7#
|
|
| 使用道具 举报 回复 |
||
| newkid
论坛徽章: 531
|
8#
|
|
http://www.itpub.net/thread-2053863-1-1.html
[PL/SQL] 如何实现存储过程多线程执行[复制链接] |

| ciwei5525 论坛徽章: 0 |
电梯直达
|
|
|
||
| 使用道具 举报 回复 |
||
| test_100
认证徽章
论坛徽章: 16
|
2#
|
|
| 使用道具 举报 回复 |
||
| newkid
论坛徽章: 531
|
3#
|
|
| 使用道具 举报 回复 |
||
| test_100
认证徽章
论坛徽章: 16
|
4#
|
|
| 使用道具 举报 回复 |
||
| newkid
论坛徽章: 531
|
5#
|
|
| 使用道具 举报 回复 |
||
| test_100
认证徽章
论坛徽章: 16
|
6#
|
|
http://www.itpub.net/thread-2094704-1-1.html