Ubuntu18.04虚拟机的Hadoop集群环境搭建
Ubuntu18.04虚拟机的Hadoop集群环境搭建
- 简介
- 1. 安装 master 虚拟机
- 2. 配置名为 hadoop 的用户
- 3. 安装 jdk
- 4. 安装 hadoop
- 5. 配置hadoop内置文件
- 6. 克隆 master 虚拟机
- 7. 两台虚拟机实现 ssh 免密登录
- 8. hadoop命令
简介
基础环境:window主机 + VMware Workstation Pro + Ubuntu18.04镜像
资源:
- jdk-8u231-linux-x64.tar.gz:链接: https://pan.baidu.com/s/1PDfZp7NExc6KdtQ1qhkPOQ 提取码: t4wt
- hadoop-2.8.5.tar.gz:链接: https://pan.baidu.com/s/10ex0snB0Eq4O5PpIWkEagw 提取码: vcn5
- ubuntu-18.04.2-desktop-amd64.iso:链接: https://pan.baidu.com/s/1-l1_brAur4ba8jln87CvyQ 提取码: 3tdr
虚拟机:master + slave1 ( + slave2) #内存不足可仅装两台
基本步骤:
- 安装 master 虚拟机,并命名为 master ;
- 为 master 配置名为 hadoop 的用户;
- 为 master 安装 jdk (.tar.gz);
- 为 master 安装 hadoop (.tar.gz);
- 配置 hadoop 内置文件
- 克隆 master 虚拟机,并命名为 slave1 ;
- 两台虚拟机实现 ssh 免密登录;
- 启动 hadoop ;
1. 安装 master 虚拟机
- 打开VMware——新建虚拟机——选择典型安装——稍后安装操作系统
- 虚拟机名称可设置为master
- 内存大小建议 1 ~ 2G
- 安装时选择最小安装
- 等待系统安装完成
2. 配置名为 hadoop 的用户
- 打开master虚拟机,按住Ctrl+Alt+T进入终端
- 创建hadoop用户
sudo useradd -m hadoop -s /bin/bash
- 为hadoop用户设置密码
sudo passwd hadoop
- 为hadoop用户添加管理员权限
sudo adduser hadoop sudo
- 切换用户
su - hadoop
- 创建hadoop级目录(在 这里“~” 等同于 ”/home/hadoop“,即代表当前用户的用户主目录)
mkdir -p ~/chadoop/java
mkdir -p ~/chadoop/hadoop
mkdir -p ~/chadoop/tmp
mkdir -p ~/chadoop/dfs/name ~/chadoop/dfs/data
3. 安装 jdk
- 开启VMware共享文件夹
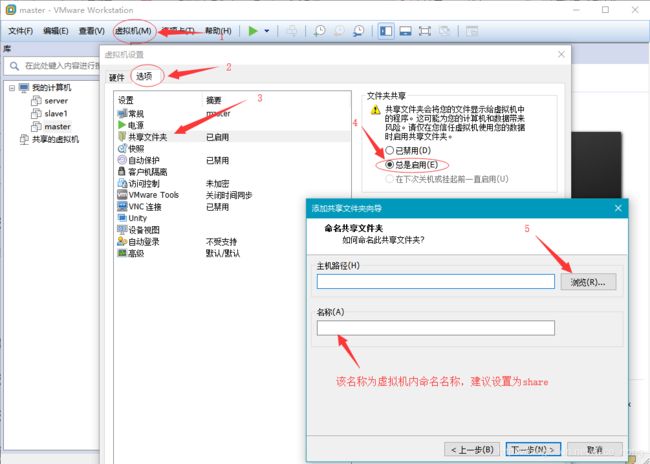
- 在宿主机下,将下载好的jdk、hadoop文件拷贝到主机文件夹中
- 回到master虚拟机中,进入共享文件夹目录(/mnt/hdfs/共享文件夹名)
cd /mnt/hdfs/share
- 使用tar命令解压到目标文件夹
tar -zxvf jdk-8u231-linux-x64.tar.gz -C ~/chadoop/java
- 配置 jdk 环境变量
sudo vim /etc/profile
在末尾添加
export JAVA_HOME=/home/hadoop/chadoop/java/jdk1.8.0_231 #(必须与解压路径一致)
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$JAVA_HOME/bin:$PATH
- 配置生效
source /etc/profile
- 测试
java -version

4. 安装 hadoop
- 进入共享文件夹目录(/mnt/hdfs/共享文件夹名)
cd /mnt/hdfs/share
- 使用tar命令解压到目标文件夹
tar -zxvf hadoop-2.8.5.tar.gz -C ~/chadoop/hadoop
- 配置hadoop环境变量
vim ~/.profile
在末尾添加
HADOOP_HOME=~/chadoop/hadoop/hadoop-2.8.5 #(文件路径必须一致)
HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
PATH=$PATH:$HADOOP_HOME/bin
PATH=$PATH:$HADOOP_HOME/sbin
export PATH HADOOP_HOME HADOOP_CONF_DIR
- 配置生效
source ~/.profile
- 测试
hadoop
5. 配置hadoop内置文件
cd ~/chadoop/hadoop/hadoop-2.8.5/etc/hadoop
涉及的文件:
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
hadoop-env.sh
mapred-env.sh
yarn-env.sh
slaves
- 【core-site.xml】
fs.defaultFS
hdfs://master:9000
hadoop.tmp.dir
file:/home/hadoop/chadoop/tmp
io.file.buffer.size
131072
- 【hdfs-site.xml】
dfs.namenode.name.dir
/home/hadoop/chadoop/dfs/name
namenode的目录位置
dfs.datanode.data.dir
/home/hadoop/chadoop/dfs/data
datanode的目录位置
dfs.replication
2
hdfs系统的副本数量
dfs.namenode.secondary.http-address
master:9001
备份namenode的http地址
dfs.webhdfs.enabled
true
hdfs文件系统的webhdfs使能标致
- 【mapred-site.xml】
mapred-site.xml需要先复制模板生成配置文件后修改内容
cp mapred-site.xml.template mapred-site.xml
mapreduce.framework.name
yarn
指明MapRreduce的调度框架为yarn
mapreduce.jobhistory.address
master:10020
知名MapReduce的作业历史地址
mapreduce.jobhistory.webapp.address
master:19888
指明MapReduce的作业历史web地址
- 【yarn-site.xml】
yarn.resourcemanager.address
master:18040
yarn.resourcemanager.scheduler.address
master:18030
yarn.resourcemanager.webapp.address
master:18088
yarn.resourcemanager.resource-tracker.address
master:18025
yarn.resourcemanager.admin.address
master:18141
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
- 【hadoop-env.sh】
加入JAVA_HOME位置
export JAVA_HOME=/home/hadoop/chadoop/java/jdk1.8.0_231
- 【mapred-env.sh】
加入JAVA_HOME位置
export JAVA_HOME=/home/hadoop/chadoop/java/jdk1.8.0_231
- 【yarn-env.sh】
加入JAVA_HOME位置
export JAVA_HOME=/home/hadoop/chadoop/java/jdk1.8.0_231
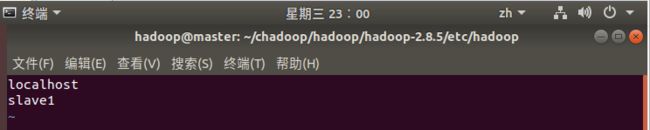
- 【slaves】
加入slave机器名称
6. 克隆 master 虚拟机
关闭master虚拟机,右键单击master机器名

克隆类型为 完整克隆
虚拟机名称为 slave1
slave1机器的内存分配可降低一些
7. 两台虚拟机实现 ssh 免密登录
启动 master
启动 slave1
Ctrl+Alt+T 打开终端
切换用户
su - hadoop
分别查看两台机器的IP,命令(18.04不再使用ifconfig):
ip address
(或ip a)
以 master 为例
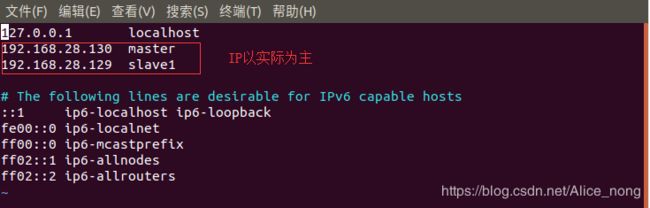
- 添加IP映射
sudo vim /etc/hosts
- 测试连接
ping master
(相当于ping 192.168.28.130)
ping slave1

- 安装ssh-server
sudo apt-get update
sudo apt-get install openssh-server
- 进入ssh用户目录
cd ~/.ssh
- 生成密钥公钥
ssh-keygen -t rsa
回车默认确定
- 加入授权
cat ./id_rsa.pub >> ./authorized_keys
- 修改文件"authorized_keys"权限
chmod 600 authorized_keys
- 修改配置文件
sudo vim /etc/ssh/sshd_config
启用以下参数
AddressFamily any #允许任何地方登录
PermitRootLogin yes # 允许root账号登录
PubkeyAuthentication yes # 启用公钥私钥配对认证方式
AuthorizedKeysFile /home/hadoop/.ssh/authorized_keys # 公钥文件路径(和上面生成的文件同)
- 重启SSH
/etc/init.d/sshd restart
-
转入操作slave1机器上,重复 1~9 步骤
-
在master机器上把slave1的公钥传到master的authorized_keys上
ssh slave1 cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
- 在master上的authorized_keys文件复制替换到各个节点上,使得每个节点上的authorized_keys文件一样
scp ~/.ssh/authorized_keys slave1:~/.ssh/authorized_keys
- 测试
master:~$ ssh slave1
slave1:~$ ssh master
8. hadoop命令
- 格式化
hadoop namenode -format
- 在master机器上启动hadoop
start-all.sh
- 关闭hadoop
stop-all.sh