一千万个数高效求和
前言
今天看到了一道面试题
一千万个数,如何高效求和?
看到这个题中的“高效求和”,第一反应想到了JDK1.8提供的LongAdder类的设计思想,就是分段求和再汇总。也就是开启多个线程,每个线程负责计算一部分,所以线程都计算完成后再汇总。整个过程大致如下:
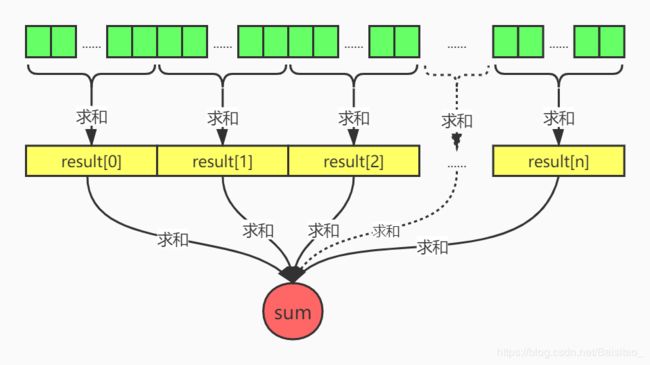
思路已经有了,接下来就开始愉快的编码吧
测试环境
- win10系统
- 4核4线程CPU
- JDK1.8
- com.google.guava.guava-25.1-jre.jar
- lombok
实例
由于题目对一千万个数没有明确定义是什么数,所以暂定为int类型的随机数。为了对比效率,博主实现了单线程版本和多线程版本,看看多线程到底有多高效。
单线程版本
单线程累加一千万个数,代码比较简单,直接给出
/**
* 单线程的方式累加
* @param arr 一千万个随机数
*/
public static int singleThreadSum(int[] arr) {
long start = System.currentTimeMillis();
int sum = 0;
int length = arr.length;
for (int i = 0; i < length; i++) {
sum += arr[i];
}
long end = System.currentTimeMillis();
log.info("单线程方式计算结果:{}, 耗时:{} 秒", sum, (end - start) / 1000.0);
return sum;
}
多线程版本
多线程的版本涉及到线程池、CountDownLatch等工具的使用,所以稍微复杂一些。
// 每个task求和的规模
private static final int SIZE_PER_TASK = 200000;
// 线程池
private static ThreadPoolExecutor executor = null;
static {
// 核心线程数 CPU数量 + 1
int corePoolSize = Runtime.getRuntime().availableProcessors() + 1;
executor = new ThreadPoolExecutor(corePoolSize, corePoolSize, 3, TimeUnit.SECONDS, new LinkedBlockingQueue());
}
/**
* 多线程的方式累加
*
* @param arr 一千万个随机数
* @throws InterruptedException
*/
public static int concurrencySum(int[] arr) throws InterruptedException {
long start = System.currentTimeMillis();
LongAdder sum = new LongAdder();
// 拆分任务
List> taskList = Lists.partition(Arrays.asList(arr), SIZE_PER_TASK);
// 任务总数
final int taskSize = taskList.size();
final CountDownLatch latch = new CountDownLatch(taskSize);
for (int i = 0; i < taskSize; i++) {
int[] task = taskList.get(i).get(0);
executor.submit(() -> {
try {
for (int num : task) {
// 把每个task中的数字累加
sum.add(num);
}
} finally {
// task执行完成后,计数器减一
latch.countDown();
}
});
}
// 主线程等待所有子线程执行完成
latch.await();
long end = System.currentTimeMillis();
log.info("多线程方式计算结果:{}, 耗时:{} 秒", sum, (end - start) / 1000.0);
// 关闭线程池
executor.shutdown();
return sum.intValue();
}
由于代码中有了详细的注释,所以不再赘述。
main方法
main方法也比较简单,主要产生一千万个随机数,再调用两个方法即可。
// 求和的个数
private static final int SUM_COUNT = 10000000;
public static void main(String[] args) throws InterruptedException {
Random random = new Random();
int[] arr = new int[SUM_COUNT];
for (int i = 0; i < SUM_COUNT; i++) {
arr[i] = random.nextInt(200);
}
// 多线程版本
concurrencySum(arr);
// 单线程版本
singleThreadSum(arr);
}
第8行代码random.nextInt(200)为什么是200?
因为 1kw * 200 = 20 亿 < Integer.MAX_VALUE,所以累加结果不会溢出
终于到了测试效率的时候了,是骡子是马,拉出来溜溜。
信心满满的我,点击了run,得到了如下结果
22:13:31.068 [main] INFO com.sicimike.concurrency.EfficientSum - 多线程方式计算结果:995523090, 耗时:0.133 秒
22:13:31.079 [main] INFO com.sicimike.concurrency.EfficientSum - 单线程方式计算结果:995523090, 耗时:0.006 秒
可能是我打开的方式不对…
但是
经过了多次运行,以及调整线程池参数之后的多次运行,总是得出不忍直视的运行结果。
多线程方式运行时间稳定在0.130秒左右,单线程运行方式稳定在0.006秒左右。
多线程改进
前文多线程的版本中使用了LongAdder类,由于LongAdder类在底层使用了大量的cas操作,线程竞争非常激烈时,效率会有不同程度的降低。所以在改进本例中多线程的版本时,不使用LongAdder类,而是更适合当前场景的方式。
/**
* 多线程的方式累加(改进版)
*
* @param arr 一千万个随机数
* @throws InterruptedException
*/
public static int concurrencySum(int[] arr) throws InterruptedException {
long start = System.currentTimeMillis();
int sum = 0;
// 拆分任务
List> taskList = Lists.partition(Arrays.asList(arr), SIZE_PER_TASK);
// 任务总数
final int taskSize = taskList.size();
final CountDownLatch latch = new CountDownLatch(taskSize);
// 相当于LongAdder中的Cell[]
int[] result = new int[taskSize];
for (int i = 0; i < taskSize; i++) {
int[] task = taskList.get(i).get(0);
final int index = i;
executor.submit(() -> {
try {
for (int num : task) {
// 各个子线程分别执行累加操作
// result每一个单元就是一个task的累加结果
result[index] += num;
}
} finally {
latch.countDown();
}
});
}
// 等待所有子线程执行完成
latch.await();
for (int i : result) {
// 把子线程执行的结果累加起来就是最终的结果
sum += i;
}
long end = System.currentTimeMillis();
log.info("多线程方式计算结果:{}, 耗时:{} 秒", sum, (end - start) / 1000.0);
// 关闭线程池
executor.shutdown();
return sum;
}
执行改进后的方法,得到如下结果:
22:46:05.085 [main] INFO com.sicimike.concurrency.EfficientSum - 多线程方式计算结果:994958790, 耗时:0.049 秒
22:46:05.094 [main] INFO com.sicimike.concurrency.EfficientSum - 单线程方式计算结果:994958790, 耗时:0.006 秒
多次运行,以及调整线程池参数之后的多次运行,结果也趋于稳定。
多线程方式运行时间稳定在0.049秒左右,单线程运行方式稳定在0.006秒左右
多线程版本改进前后,运行时间从0.133秒降到0.049秒,效率大概提升了170%
思考
改进后的代码不仅没有解决单线程为什么比多线程快的问题,反而还多了一个问题:
为什么随随便便引入一个数组,竟然比Doug Lea写的
LongAdder还快?
因为LongAdder是一个通用的工具类,很好的平衡了时间和空间的关系,所以在各种场景下都能有较好的效率。而本例中的result数组,一千万个数被分成了多少个task,数组的长度就是多少,每个task的结果都存在独立的数组项,不存在竞争,但是占用了更多的空间,所以时间效率更高,也就是拿空间换时间的思想。
至于为什么单线程比多线程快,这其实并不难理解。因为单线程没有上下文切换,加上累加场景比较简单,每个task执行时间很短,所以单线程更快很正常。
stream方式
stream是JDK1.8提供的语法糖,也是单线程的。关于stream的用法,大家自行了解即可。主要用来和后文的parallel stream进行对比。
public static int streamSum(List list) {
long start = System.currentTimeMillis();
int sum = list.stream().mapToInt(num -> num).sum();
long end = System.currentTimeMillis();
log.info("stream方式计算结果:{}, 耗时:{} 秒", sum, (end - start) / 1000.0);
return sum;
}
parallelStream方式
parallelStream见名知意,就是并行的stream。
public static int parallelStreamSum(List list) {
long start = System.currentTimeMillis();
int sum = list.parallelStream().mapToInt(num -> num).sum();
long end = System.currentTimeMillis();
log.info("parallel stream方式计算结果:{}, 耗时:{} 秒", sum, (end - start) / 1000.0);
return sum;
}
ForkJoin方式
ForkJoin框架是JDK1.7提出的,用于拆分任务计算再合并计算结果的框架。
当我们需要执行大量的小任务时,有经验的Java开发人员都会采用线程池来高效执行这些小任务。然而,有一种任务,例如,对超过1000万个元素的数组进行排序,这种任务本身可以并发执行,但如何拆解成小任务需要在任务执行的过程中动态拆分。这样,大任务可以拆成小任务,小任务还可以继续拆成更小的任务,最后把任务的结果汇总合并,得到最终结果,这种模型就是Fork/Join模型。
ForkJoin框架的使用大致分为两个部分:实现ForkJoin任务、执行任务
实现ForkJoin任务
自定义类继承RecursiveTask(有返回值)或者RecursiveAction(无返回值),实现compute方法
/**
* 静态内部类的方式实现
* forkjoin任务
*/
static class SicForkJoinTask extends RecursiveTask {
// 子任务计算区间开始
private Integer left;
// 子任务计算区间结束
private Integer right;
private int[] arr;
@Override
protected Integer compute() {
if (right - left < SIZE_PER_TASK) {
// 任务足够小时,直接计算
int sum = 0;
for (int i = left; i < right; i++) {
sum += arr[i];
}
return sum;
}
// 继续拆分任务
int middle = left + (right - left) / 2;
SicForkJoinTask leftTask = new SicForkJoinTask(arr, left, middle);
SicForkJoinTask rightTask = new SicForkJoinTask(arr, middle, right);
invokeAll(leftTask, rightTask);
Integer leftResult = leftTask.join();
Integer rightResult = rightTask.join();
return leftResult + rightResult;
}
public SicForkJoinTask(int[] arr, Integer left, Integer right) {
this.arr = arr;
this.left = left;
this.right = right;
}
}
执行任务
通过ForkJoinPool的invoke方法执行ForkJoin任务
// ForkJoin线程池
private static final ForkJoinPool forkJoinPool = new ForkJoinPool();
public static int forkJoinSum(int[] arr) {
long start = System.currentTimeMillis();
// 执行ForkJoin任务
Integer sum = forkJoinPool.invoke(new SicForkJoinTask(arr, 0, SUM_COUNT));
long end = System.currentTimeMillis();
log.info("forkjoin方式计算结果:{}, 耗时:{} 秒", sum, (end - start) / 1000.0);
return sum;
}
main方法
public static void main(String[] args) throws InterruptedException {
Random random = new Random();
int[] arr = new int[SUM_COUNT];
List list = new ArrayList<>(SUM_COUNT);
int currNum = 0;
for (int i = 0; i < SUM_COUNT; i++) {
currNum = random.nextInt(200);
arr[i] = currNum;
list.add(currNum);
}
// 单线程执行
singleThreadSum(arr);
// Executor线程池执行
concurrencySum(arr);
// stream执行
streamSum(list);
// 并行stream执行
parallelStreamSum(list);
// forkjoin线程池执行
forkJoinSum(arr);
}
执行结果
23:19:21.207 [main] INFO com.sicimike.concurrency.EfficientSum - 单线程方式计算结果:994917205, 耗时:0.006 秒
23:19:21.274 [main] INFO com.sicimike.concurrency.EfficientSum - 多线程方式计算结果:994917205, 耗时:0.062 秒
23:19:21.292 [main] INFO com.sicimike.concurrency.EfficientSum - stream方式计算结果:994917205, 耗时:0.018 秒
23:19:21.309 [main] INFO com.sicimike.concurrency.EfficientSum - parallel stream方式计算结果:994917205, 耗时:0.017 秒
23:19:21.321 [main] INFO com.sicimike.concurrency.EfficientSum - forkjoin方式计算结果:994917205, 耗时:0.012 秒
源代码
代码地址:EfficientSum.java
有兴趣的同学可以自己下载源代码后,调整各个参数运行,得到的结果不一定和博主一样。
总结
代码写了一大版,结果最初的问题还是没解决。有人可能会说:博主你这不是坑人吗
确实,我没有想到更好的办法,但是把文中的几个问题想清楚,应该会比一道面试题更有价值。
如果哪位同学有更好的优化方式,还请不吝赐教。
参考
- Java的Fork/Join任务,你写对了吗?