PAT A 1032(甲级)
1032 Sharing(25 分)
作者: CHEN, Yue
单位: 浙江大学
时间限制: 200 ms
内存限制: 64 MB
代码长度限制: 16 KB
To store English words, one method is to use linked lists and store a word letter by letter. To save some space, we may let the words share the same sublist if they share the same suffix. For example, loading and beingare stored as showed in Figure 1.
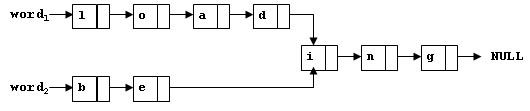
Figure 1
You are supposed to find the starting position of the common suffix (e.g. the position of i in Figure 1).
Input Specification:
Each input file contains one test case. For each case, the first line contains two addresses of nodes and a positive N (≤105), where the two addresses are the addresses of the first nodes of the two words, and N is the total number of nodes. The address of a node is a 5-digit positive integer, and NULL is represented by −1.
Then N lines follow, each describes a node in the format:
Address Data Next
whereAddress is the position of the node, Data is the letter contained by this node which is an English letter chosen from { a-z, A-Z }, and Next is the position of the next node.
Output Specification:
For each case, simply output the 5-digit starting position of the common suffix. If the two words have no common suffix, output -1 instead.
Sample Input 1:
11111 22222 9
67890 i 00002
00010 a 12345
00003 g -1
12345 D 67890
00002 n 00003
22222 B 23456
11111 L 00001
23456 e 67890
00001 o 00010
Sample Output 1:
67890
Sample Input 2:
00001 00002 4
00001 a 10001
10001 s -1
00002 a 10002
10002 t -1
Sample Output 2:
-1
这道题难度也不大,但却有鲜明的特点。
这道题最常规的做法就是,首先遍历两个链表,然后分别记录链表中节点地址的出现顺序,然后对b或a链表进行排序,然后遍历未排序的那个链表地址序列寻找排序链表地址序列中是否有此地址,如果有,这个地址就是第一个重合地址,如果没有就继续遍历序列,直至遍历完成如果还没有重合地址就输出-1。
这种做法还是有一定的工作量的,因为既要排序,还要去搜索。
但是我们还有另一种思路,就是像 PAT A 1074 中的解法思路类似,在节点结构体中加入一个变量,来标志这个节点是否已经被访问过,当然首先要把整个静态链表全部置为未访问,然后再访问a链表的同时,将标志位置true,再去访问b链表,当访问到标志位为true的第一个节点时,就是重合节点。如果没有访问到标志位为true的节点,则输出-1。
常规思路AC代码:
#include
#include
using namespace std;
struct Node {
char data;
int next;
}node[100010];
int ar[100010], br[100010];
void scanList(int, int [], int &);
bool binarySort(int [], int &, int &);
int main() {
int astart, bstart, n;
int anum = 0, bnum = 0;
scanf("%d%d%d", &astart, &bstart, &n);
for(int i = 0; i < n; ++i) {
int ad, ne;
char da;
scanf("%d %c %d", &ad, &da, &ne);
node[ad].data = da;
node[ad].next = ne;
}
scanList(astart, ar, anum);
scanList(bstart, br, bnum);
sort(br, br + bnum);
bool find = false;
for(int i = 0; i < anum; ++i) {
if(binarySort(br, bnum, ar[i])) {
printf("%05d", ar[i]);
find = true;
break;
}
}
if(!find) {
printf("-1");
}
return 0;
}
void scanList(int start, int record[], int &num) {
if(start != -1) {
do {
record[num++] = start;
start = node[start].next;
} while(start != -1);
}
}
bool binarySort(int li[], int &tail, int &tar) {
int h = 0, t = tail - 1;
if(t > -1) {
do {
int mid = (h + t) / 2;
if(li[mid] == tar) {
return true;
} else if(li[mid] > tar) {
t = mid - 1;
} else {
h = mid + 1;
}
} while(h <= t);
}
return false;
}
改进思路AC代码:
#include
const int maxn = 100010;
struct Node {
char data;
int next;
bool vis;
} node[maxn];
int main() {
for(int i = 0; i < maxn; ++i) {
node[i].vis = false;
}
int s1, s2, n;
scanf("%d%d%d", &s1, &s2, &n);
for(int i = 0; i < n; ++i) {
int address, next;
char data;
scanf("%d %c %d", &address, &data, &next);
node[address].data = data;
node[address].next = next;
}
int p;
for(p = s1; p != -1; p = node[p].next) {
node[p].vis = true;
}
for(p = s2; p != -1; p = node[p].next) {
if(node[p].vis) {
break;
}
}
if(p == -1) {
printf("-1\n");
} else {
printf("%05d\n", p);
}
return 0;
}
如有错误,欢迎指摘。