基于HDP使用Flume实时采集MySQL中数据传到Kafka+HDFS或Hive
环境版本: HDP-2.5.3
注意:HDP中Kafka broker的端口是6667,不是9092
如果只sink到kafka请看这篇:基于HDP使用Flume采集MySQL中数据传到Kafka
前言
有两种方式可以将数据通过flume导入hive中,一是直接sink到hive中,二是sink到hdfs中,然后在hive中建个外部表。直接sink到hive中相对麻烦一些,需要加入需要的jar包,而且hive表需要分桶、开启事务、保存为ORC格式。其实搞清楚了也不麻烦,但是本文中agent.sources.r1.type使用org.keedio.flume.source.SQLSource,传入的字段全变成了加上双引号的字符串,处理起来比较麻烦。所以我最终选用了sink到hdfs中,可以通过OpenCSVSerde去掉双引号。现给出了两种方案,各取所需吧。如有别的方式去掉双引号,欢迎下方留言。
文章目录
- 前言
- 1.将所需jar包放入Flume安装目录lib下
- 2.sink到hdfs
- 2.1 编写mysql_kafka_hdfs.conf
- 2.2 建外部表 OpenCSVSerde
- 3.sink到hive
- 3.1 编写mysql_kafka_hive.conf
- 3.2 建hive表
- 4.启动Flume agent
- 4.1 命令行启动
- 4.2 ambari中启动
- 4.3 ambari中停止
- 5.测试kafka消费topic里的消息
- 6.查看hdfs目录和hive表
- 6.1 hdfs
- 6.2 hive
- 备注:报错及解决办法
1.将所需jar包放入Flume安装目录lib下
下载地址:Flume采集MySQL数据所需jar包
libfb303-0.9.3.jar 不要用libfb303,不适用于hive1.x
除此之外,还有hive-hcatalog-streaming.jar、hive-metastore.jar、hive-exec.jar、hive-cli.jar、hive-hcatalog-core.jar,这些在/usr/hdp/2.5.3.0-37/hive/lib或/usr/hdp/2.5.3.0-37/hive-hcatalog/share/hcatalog下都可以找到,放入/usr/hdp/2.5.3.0-37/flume/lib/下即可。
[root@hqc-test-hdp3 kafka]# cd /usr/hdp/2.5.3.0-37/flume/lib/
2.sink到hdfs
2.1 编写mysql_kafka_hdfs.conf
一个source可以绑定多个channel,
一个sink只能绑定一个channel。
我开始只用了一个channel,发现两边都会少数据。
agent.sources = r1
agent.channels = c1 c2
agent.sinks = k1 k2
#### define source begin
## define sqlSource
agent.sources.r1.channels = c1 c2
agent.sources.r1.type = org.keedio.flume.source.SQLSource
agent.sources.r1.hibernate.connection.driver_class = com.mysql.jdbc.Driver
agent.sources.r1.hibernate.connection.url = jdbc:mysql://xxx:3306/hqc
agent.sources.r1.hibernate.connection.user = xxx
agent.sources.r1.hibernate.connection.password = xxx
agent.sources.r1.hibernate.connection.autocommit = true
agent.sources.r1.hibernate.dialect = org.hibernate.dialect.MySQL5Dialect
agent.sources.r1.run.query.delay = 5000
agent.sources.r1.table = K401_online
## source状态写入路径(必须存在且可写入)
agent.sources.r1.status.file.path = /data/flume-log/
agent.sources.r1.status.file.name = sqlsource.status
#### define sink begin
# define sink-k1-kafka
agent.sinks.k1.channel = c1
agent.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
agent.sinks.k1.topic = k401
agent.sinks.k1.brokerList = hqc-test-hdp1:6667,hqc-test-hdp2:6667,hqc-test-hdp3:6667
agent.sinks.k1.requiredAcks = 1
agent.sinks.k1.batchSize = 20
agent.sinks.k1.producer.type = async
# define sink-k2-hdfs
agent.sinks.k2.channel = c2
agent.sinks.k2.type = hdfs
agent.sinks.k2.hdfs.path = hdfs://hqc-test-hdp1:8020/apps/hive/warehouse/hqc.db/k401_online
agent.sinks.k2.hdfs.writeFormat=Text
# 积攒多少个Event才flush到HDFS一次
agent.sinks.k2.hdfs.batchSize = 100
# 设置文件类型,可支持压缩
agent.sinks.k2.hdfs.fileType = DataStream
# 多久生成一个新的文件,单位秒(1小时存一次)
agent.sinks.k2.hdfs.rollInterval = 3600
# 设置每个文件的滚动大小,设置为128M,单位是kb
agent.sinks.k2.hdfs.rollSize = 134217728
# 文件的滚动与Event数量无关
agent.sinks.k2.hdfs.rollCount = 0
# 最小冗余数
# agent.sinks.k2.hdfs.minBlockReplicas = 1
#### define channel begin
## define channel-c1-memory
agent.channels.c1.type = memory
agent.channels.c1.capacity = 134217728
agent.channels.c1.transactionCapacity = 100
## define channel-c2-memory
agent.channels.c2.type = memory
agent.channels.c2.capacity = 134217728
agent.channels.c2.transactionCapacity = 100
2.2 建外部表 OpenCSVSerde
location要与上文中的agent.sinks.k2.hdfs.path对应
直接将双引号去掉 “43.72” => 43.72
分隔符:DEFAULT_SEPARATOR ,
引号符:DEFAULT_QUOTE_CHARACTER "
转义符:DEFAULT_ESCAPE_CHARACTER \
create external table k401_online(...)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
WITH SERDEPROPERTIES (
"separatorChar" = ",",
"quoteChar" = "\"",
"escapeChar" = "\\"
)
STORED AS TEXTFILE
location '/apps/hive/warehouse/hqc.db/k401_online';
3.sink到hive
3.1 编写mysql_kafka_hive.conf
agent.sources = r1
agent.channels = c1 c2
agent.sinks = k1 k2
#### define source begin
## define sqlSource
agent.sources.r1.channels = c1 c2
agent.sources.r1.type = org.keedio.flume.source.SQLSource
agent.sources.r1.hibernate.connection.driver_class = com.mysql.jdbc.Driver
agent.sources.r1.hibernate.connection.url = jdbc:mysql://xx:3306/hqc
agent.sources.r1.hibernate.connection.user = xx
agent.sources.r1.hibernate.connection.password = xx
agent.sources.r1.hibernate.connection.autocommit = true
agent.sources.r1.hibernate.dialect = org.hibernate.dialect.MySQL5Dialect
agent.sources.r1.run.query.delay = 5000
agent.sources.r1.table = K401_online
## source状态写入路径(必须存在且可写入)
agent.sources.r1.status.file.path = /data/flume-log/
agent.sources.r1.status.file.name = sqlsource.status
#### define sink begin
# define sink-k1-kafka
agent.sinks.k1.channel = c1
agent.sinks.k1.type = org.apache.flume.sink.kafka.KafkaSink
agent.sinks.k1.topic = k401
agent.sinks.k1.brokerList = hqc-test-hdp1:6667,hqc-test-hdp2:6667,hqc-test-hdp3:6667
agent.sinks.k1.requiredAcks = 1
agent.sinks.k1.batchSize = 20
agent.sinks.k1.producer.type = async
#define sink-k2-hive
agent.sinks.k2.channel = c2
agent.sinks.k2.type = hive
agent.sinks.k2.hive.metastore = thrift://hqc-test-hdp1:9083
agent.sinks.k2.hive.database = hqc
agent.sinks.k2.hive.table = k401_online
# hive表若没有设置分区,下面需注释
# agent.sinks.k2.hive.partition = %y-%m-%d
agent.sinks.k2.useLocalTimeStamp = false
agent.sinks.k2.serializer = DELIMITED
# 输入用双引号标注分隔符
agent.sinks.k2.serializer.delimiter = ","
# 输出用单引号标注分隔符
agent.sinks.k2.serializer.serdeSeparator = ','
# 字段名称与hive表字段对应,全为小写
agent.sinks.k2.serializer.fieldnames = ...
#### define channel begin
## define channel-c1-memory
agent.channels.c1.type = memory
agent.channels.c1.capacity = 134217728
agent.channels.c1.transactionCapacity = 100
## define channel-c2-memory
agent.channels.c2.type = memory
agent.channels.c2.capacity = 134217728
agent.channels.c2.transactionCapacity = 100
3.2 建hive表
create table k401_online(datatime string, ... 必须全是string类型)
# partitioned by (dt string) 可以不分区,flume配置文件中要与之对应
clustered by (datatime) into 2 buckets
row format delimited fields terminated by ','
stored as orc tblproperties ('transactional'='true');
还要开启事务,不然报错
hive> select * from k401_online limit 10;
FAILED: SemanticException [Error 10265]: This command is not allowed on an ACID table hqc.k401_online with a non-ACID transaction manager. Failed command: null
hive> set hive.support.concurrency=true;
hive> set hive.txn.manager=org.apache.hadoop.hive.ql.lockmgr.DbTxnManager;
hive> select * from k401_online limit 10;
OK
Time taken: 0.411 seconds
4.启动Flume agent
4.1 命令行启动
使用hdfs用户命令行启动
[root@hqc-test-hdp3 ~]# su hdfs
[hdfs@hqc-test-hdp3 root]$ cd
[hdfs@hqc-test-hdp3 ~]$ ls
mysql_kafka_hive.conf
[hdfs@hqc-test-hdp3 ~]$ flume-ng agent --conf conf --conf-file ./mysql_kafka_hdfs.conf --name agent -Dflume.root.logger=INFO,console
4.2 ambari中启动
或修改agent.sinks.k2.hdfs.path配置目录的权限(只给flume用户赋予权限也可)
[hdfs@hqc-test-hdp3 flume-log]$ hdfs dfs -chmod 777 /apps/hive/warehouse/hqc.db/k401_online
然后登录ambari,在界面配置
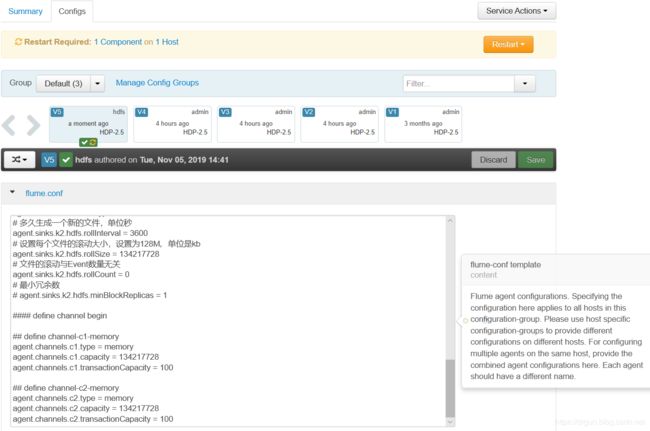
保存后重启flume即可启动
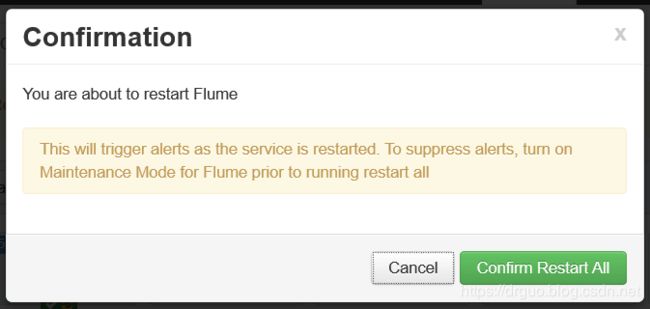
4.3 ambari中停止
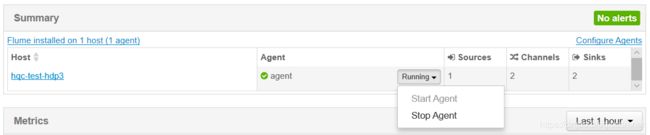
5.测试kafka消费topic里的消息
[root@hqc-test-hdp1 kafka]# bin/kafka-console-consumer.sh --zookeeper hqc-test-hdp1:2181,hqc-test-hdp2:2181,hqc-test-hdp3:2181 --topic k401
{metadata.broker.list=hqc-test-hdp2:6667,hqc-test-hdp1:6667,hqc-test-hdp3:6667, request.timeout.ms=30000, client.id=console-consumer-810, security.protocol=PLAINTEXT}
"59397","2019-11-05 14:28:34.0","43.13187026977539","82.41758728027344","75.96153259277344","68.13186645507812","69.0018310546875","67.71977996826172","9.779629707336426","36.624576568603516","48.009578704833984","9.934499740600586","19.273277282714844","31.403581619262695","14.164774894714355","13.624568939208984","33.859535217285156","13.033035278320312","30.72835922241211","68.95604705810547","31.4886417388916","12.381695747375488","21.886232376098633","53.754581451416016","70.0091552734375","79.71611785888672","62.17948913574219","45.100730895996094","78.15933990478516","52.884613037109375","65.33882904052734","50.732601165771484","30.14316177368164","0.06600084601562406","57.82966995239258","0.1385324753498427","10.330347061157227","11.46349048614502","69.23076629638672","0.23454403106687838","38.453250885009766","62.31684875488281","0.31968492282781524"
"59398","2019-11-05 14:28:40.0","43.13187026977539","82.41758728027344","76.00733184814453","68.26922607421875","69.18498229980469","67.67399597167969","10.515767097473145","35.46472930908203","47.79638671875","9.906632423400879","20.73094940185547","31.90235710144043","15.004719734191895","13.935589790344238","34.49615478515625","13.863764762878418","30.953277587890625","69.0018310546875","32.68650817871094","13.695724487304688","22.305086135864258","53.754581451416016","69.96337127685547","79.53296661376953","62.27106475830078","45.100730895996094","78.15933990478516","52.79304122924805","65.15567779541016","50.86996078491211","30.627979278564453","0.06930961997635299","58.333335876464844","0.14214391705876928","11.65231990814209","11.63076114654541","69.13919067382812","0.23414736284558613","38.44184875488281","62.408424377441406","0.32020119207452813"
6.查看hdfs目录和hive表
6.1 hdfs
每小时(3600秒)生成一个文件,flume中设置的。
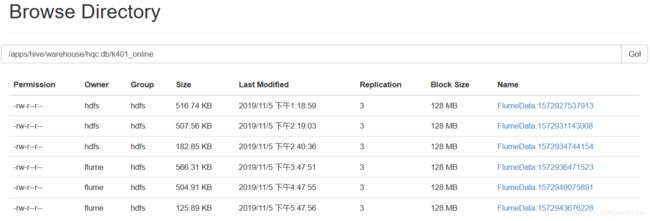
(前三个是命令行启动,所属用户和组都是hdfs,后三个是ambari中启动,所属用户是flume,与ambari登录用户无关)
因为MySQL中每6秒插入一条数据,hdfs也是每6秒插入一次,一小时600条。
可以看到,FlumeData.xxx.tmp每6秒插入一条数据,一小时后就将FlumeData.xxx.tmp的后缀.tmp去掉,生成完整的文件。
[hdfs@hqc-test-hdp3 flume-log]$ hdfs dfs -cat /apps/hive/warehouse/hqc.db/k401_online/FlumeData.1572931143008 | wc -l
600
[hdfs@hqc-test-hdp3 flume-log]$ hdfs dfs -cat /apps/hive/warehouse/hqc.db/k401_online/FlumeData.1572934744154.tmp | wc -l
141
[hdfs@hqc-test-hdp3 flume-log]$ hdfs dfs -cat /apps/hive/warehouse/hqc.db/k401_online/FlumeData.1572934744154.tmp | wc -l
142
6.2 hive
hive> use hqc;
OK
Time taken: 0.025 seconds
hive> show tables;
OK
k401_online
view_eventdiftime
view_thing
Time taken: 0.026 seconds, Fetched: 3 row(s)
hive> select * from k401_online limit 1;
OK
59499 2019-11-06 10:36:34.0 42.857 82.234 75.412 67.811 68.91 66.667 10.818 38.453 50.965 9.313 21.151 33.681 15.618 14.456 36.052 13.142 29.591 68.956 31.872 13.217 22.577 53.571 69.872 79.396 62.546 44.643 78.022 52.427 65.201 50.275 31.400.073 57.967 0.138 11.935 13.213 67.903 0.243 39.59 61.264 0.327
Time taken: 0.059 seconds, Fetched: 1 row(s)
hive> select count(*) from k401_online;
Query ID = hdfs_20191105143847_ee94a2fa-7a9b-4942-882c-aaab92c6ac2f
Total jobs = 1
Launching Job 1 out of 1
Tez session was closed. Reopening...
Session re-established.
Status: Running (Executing on YARN cluster with App id application_1564035532438_0032)
--------------------------------------------------------------------------------
VERTICES STATUS TOTAL COMPLETED RUNNING PENDING FAILED KILLED
--------------------------------------------------------------------------------
Map 1 .......... SUCCEEDED 1 1 0 0 0 0
Reducer 2 ...... SUCCEEDED 1 1 0 0 0 0
--------------------------------------------------------------------------------
VERTICES: 02/02 [==========================>>] 100% ELAPSED TIME: 7.75 s
--------------------------------------------------------------------------------
OK
1212
备注:报错及解决办法
1
19/11/04 15:55:03 ERROR hdfs.HDFSEventSink: process failed
org.apache.flume.ChannelException: Take list for MemoryTransaction, capacity 100 full, consider committing more frequently, increasing capacity, or increasing thread count
https://www.cnblogs.com/dongqingswt/p/5070776.html
调大 agent.channels.c1.capacity = 134217728
2
flume采集数据报错内存溢出 :java.lang.OutOfMemoryError: GC overhead limit exceeded
进入flume bin目录下,修改flume-ng文件,改成10G
[root@hqc-test-hdp3 ~]# cd /usr/hdp/2.5.3.0-37/flume/
[root@hqc-test-hdp3 flume]# ls
bin conf docs lib tools
[root@hqc-test-hdp3 flume]# cd bin/
[root@hqc-test-hdp3 bin]# ls
flume-ng flume-ng.distro
[root@hqc-test-hdp3 bin]# vim flume-ng
[root@hqc-test-hdp3 bin]# vim flume-ng.distro
JAVA_OPTS="-Xmx10240m"
3
19/11/04 09:45:54 ERROR node.PollingPropertiesFileConfigurationProvider: Failed to start agent because dependencies were not found in classpath. Error follows.
java.lang.NoClassDefFoundError: org/apache/hive/hcatalog/streaming/RecordWriter
将hive-hcatalog-streaming.jar 拷贝到 FLUME_HOME/lib/ 下
[root@hqc-test-hdp3 hcatalog]# ls
hive-hcatalog-core-1.2.1000.2.5.3.0-37.jar hive-hcatalog-pig-adapter-1.2.1000.2.5.3.0-37.jar hive-hcatalog-server-extensions-1.2.1000.2.5.3.0-37.jar hive-hcatalog-streaming-1.2.1000.2.5.3.0-37.jar
hive-hcatalog-core.jar hive-hcatalog-pig-adapter.jar hive-hcatalog-server-extensions.jar hive-hcatalog-streaming.jar
[root@hqc-test-hdp3 hcatalog]# pwd
/usr/hdp/2.5.3.0-37/hive-hcatalog/share/hcatalog
[root@hqc-test-hdp3 hcatalog]# cp hive-hcatalog-streaming.jar /usr/hdp/2.5.3.0-37/flume/lib/
4
Caused by: java.lang.RuntimeException: java.util.concurrent.ExecutionException: java.lang.NoClassDefFoundError: org/apache/hadoop/hive/metastore/api/MetaException
[root@hqc-test-hdp3 lib]# cp hive-metastore.jar /usr/hdp/2.5.3.0-37/flume/lib/
[root@hqc-test-hdp3 lib]# pwd
/usr/hdp/2.5.3.0-37/hive/lib
5
Caused by: java.lang.NoClassDefFoundError: org/apache/hadoop/hive/ql/session/SessionState
[root@hqc-test-hdp3 lib]# cp hive-exec.jar /usr/hdp/2.5.3.0-37/flume/lib/
6
Caused by: java.lang.NoClassDefFoundError: org/apache/hadoop/hive/cli/CliSessionState
[root@hqc-test-hdp3 lib]# cp hive-cli.jar /usr/hdp/2.5.3.0-37/flume/lib/
7
Caused by: java.lang.ClassNotFoundException: org.apache.hive.hcatalog.common.HCatUtil
[root@hqc-test-hdp3 hcatalog]# cp hive-hcatalog-core.jar /usr/hdp/2.5.3.0-37/flume/lib/
[root@hqc-test-hdp3 hcatalog]# pwd
/usr/hdp/2.5.3.0-37/hive-hcatalog/share/hcatalog
8
Caused by: java.lang.ClassNotFoundException: com.facebook.fb303.FacebookServiceIface
下载libfb303-0.9.3.jar放在 FLUME_HOME/lib/ 下,不要用libfb303,下载地址:lib303-0.9.3.jar
9
Caused by: org.apache.flume.sink.hive.HiveWriter$ConnectFailure: Failed connecting to EndPoint {metaStoreUri=‘thrift://xxx:9083’, database=‘hqc’, table=‘k401_online’, partitionVals=[19-11-04] }
at org.apache.flume.sink.hive.HiveWriter.newConnection(HiveWriter.java:384)
at org.apache.flume.sink.hive.HiveWriter.(HiveWriter.java:92)
… 6 more
hive建表需分桶,存为orc,如果The hive table is partioned , bucketed and stored as ORC format.
那你应该往下看日志,真正的错误在后面
10
Caused by: java.lang.NoSuchMethodError: org.apache.hadoop.hive.metastore.api.ThriftHiveMetastoreClient.sendBase(Ljava/lang/String;Lorg/apache/thrift/TBase;)V
下载libfb303-0.9.3.jar放在 $FLUME_HOME/lib/ 下,替换libfb303
下载地址:lib303-0.9.3.jar
https://stackoverflow.com/questions/17739020/hive-jdbc-thrifthiveclient-sendbase