Spark精华问答 | spark的组件构成有哪些?
戳蓝字“CSDN云计算”关注我们哦!

Spark是一个针对超大数据集合的低延迟的集群分布式计算系统,比MapReducer快40倍左右,是hadoop的升级版本,Hadoop作为第一代产品使用HDFS,第二代加入了Cache来保存中间计算结果,并能适时主动推Map/Reduce任务,第三代就是Spark倡导的流Streaming。今天,就让我们一起来看看关于它的更加深度精华问答吧!

1
Q:Spark的组建构成有哪些?
A: 1:每一个application有自己的executor的进程,它们相互隔离,每个executor中可以有多个task线程。这样可以很好的隔离各个applications,各个spark applications 不能分享数据,除非把数据写到外部系统。
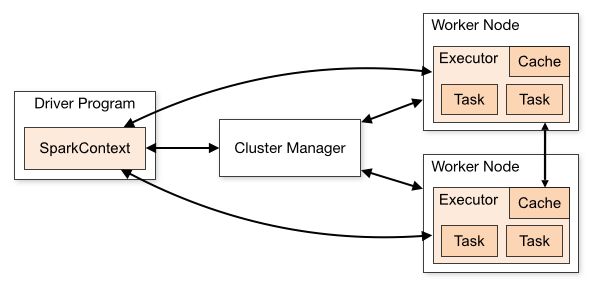
2:SparkContext对象可以视为Spark应用程序的入口,主程序被称为driver program,SparkContext可以与不同种类的集群资源管理器(Cluster Manager),例如Hadoop Yarn、Mesos等 进行通信,从而分配到程序运行所需的资源,获取到集群运行所需的资源后,SparkContext将得到集群中其它工作节点(Worker Node) 上对应的Executors (不同的Spark应用程序有不同的Executor,它们之间也是独立的进程,Executor为应用程序提供分布式计算及数据存储功能),之后SparkContext将应用程序代码分发到各Executors,最后将任务(Task)分配给executors执行。
2
Q:Spark算子内能不能引用SparkSession?
A:Spark的算子是在executor上执行的,数据也是放在executor上。executor和driver并不在同一个jvm(local[*]除外),所以算子是不能访问在driver上的SparkSession对象。
好好品味一下这个图:
如果一定要“在算子里访问SparkSession”,那只能把数据collect回Driver,然后用Scala 集合的算子去做。这种情况下只能适用于数据量不大(多大取决于分配给Driver的内存)。另外建议是通过join的方式获取关联数据并进行处理。
3
Q:一个使用Sparksql查询Hbase数据的功能,只取结果的1000条数据,用的limit算子,最后用foreachPartition算子将数据插入数据库中,但是Hbase那张表的数据量很大,有3000多个region,查看sparkui,发现竟然是要把所有的数据都要加载一遍取出对应的数据,所以Sparksql计算的时候是要把所有的数据都要加载一遍计算吗?
A:如果数据量巨大而集群计算资源吃不消的话,就建议不要用HBase存储数据,HBase并不留存任何结构化信息,同时也没有索引,因此并不适合多维查询。用Hive+Parquet+合理的分区分桶优化+SparkSQL查询性能会可观得多。另外更酷炫的是Spark+CarbonData,满足绝大多数OLAP需求,甚至详单查询的性能也很恐怖,并且支持update delete insert。
4
Q:在其他机器上部署了HDFS、HBase、Spark,请问怎么在本地调试Java Spark来操作远程的HBase,就像操作远程数据库一样?
A:1. HBase是一个数据库(分布式),有自己的JDBC,可以根据HBase的JDBC开发自己应用, 只要能连接上,本地远程都可以。
2. Spark集群部署好了,写好Spark作业提交给Spark集群,Spark cluster计算完成后,可以参看结果。
3. Spark相关的rest server是livy,然而并不是很好用有一定的版本和环境要求,很多开发者会选择避开这个坑,所以你会看到网上的大部分博客。
4. 推荐Linux环境下开发,少爬很多坑,Windows不适合大数据相关的开发。
5
Q:HDP2.4.0版本,Spark SQL运行在yarn-client模式,现在发现有些语句跑特别慢,20个节点,一千多个CPU核心,8TB内存,数据量不到一亿条,都是类似这样的语句:

group by十个字段,然后sum20多个值,竟然要十分钟以上,而把数据加载到一台oracle服务器,开启多核计算,同样语句只要30秒。
Spark SQL设置成动态分配,spark.dynamicallocation.enabled=true,设置成最大最小和初始化都是300。发现是卡在最后一个task里,例如有200个任务,卡在最后一个任务里,最后一个任务占95%以上时间。Java调用Spark的thrift server接口,直接运行SQL语句,没有采用调Spark rdd方法,请问是什么问题?
A:典型的数据倾斜问题。在一个stage里,每个task对应一个partition,当有一个partition的数据量大于其他的,就会出现这样的情况。这种情况只能用代码的方法,观察问题所在的stage对应的dataset,然后在执行SQL前,reparation(>200,有文档建议是2k)。如果问题仍存在,就要对group by的字段值加盐,group by一轮后,去盐再group by得到最终数据。

小伙伴们冲鸭,后台留言区等着你!
关于Spark,今天你学到了什么?还有哪些不懂的?除此还对哪些话题感兴趣?快来留言区打卡啦!留言方式:打开第XX天,答:……
同时欢迎大家搜集更多问题,投稿给我们!风里雨里留言区里等你~
福利
1、扫描添加小编微信,备注“姓名+公司职位”,加入【云计算学习交流群】,和志同道合的朋友们共同打卡学习!

推荐阅读:
做了中台就不会死吗?每年至少40%开发资源是被浪费的!
美女主播变大妈:在bug翻车现场说测试策略
漫画高手、小说家、滑板专家……解锁程序员的另一面!
手把手教你如何用Python模拟登录淘宝
鸿蒙霸榜 GitHub,从最初的 Plan B 到“取代 Android”?
每天超50亿推广流量、3亿商品展现,阿里妈妈的推荐技术有多牛?
真香,朕在看了!