Storm集群搭建及测试
目录
概述
核心概念
架构
一、部署说明
二、Storm配置和部署
1. 下载
2. 配置
3. 服务启动
三、wordcount测试
1. 程序编写
2. 提交Storm集群运行
3. 常用命令
概述
在过去十几年里,数据处理发生了革命性的变化。Hadoop以及相关的框架技术使我们能够存储和处理以往不能想象规模的数据。但是很遗憾,Hadoop及相关框架并不能实时处理数据,Storm应运而生。Storm是Twitter开源的分布式实时大数据处理框架,在现在的今天被广泛使用,比如网站统计、推荐系统、预警系统、金融系统等
核心概念
- Nimbus:负责资源分配和任务调度
- Supervisor:负责接受Nimbus分配的任务,启动和停止自己管理的Worker进程
- Worker:运行具体处理组件逻辑的进程
- Executor:为Worker进程中具体的物理线程,同一个Spout/Bolt的Task可能共享一个物理线程,一个Executor中只能运行隶属于同一个Spout/Bolt的Task
- Task:一个Spout/Bolt要做的具体工作
- Topology:一个实时计算的应用程序逻辑上被封装在Topology对象中,类似于Hadoop中的Job,与Job不同的是,Topology会一直运行直到显式的杀死它。可以理解为是Spout和Bolt组成的拓扑结构
- Spout:在Topology中产生源数据的组件。通常Spout获取数据源的数据(如kafka、MQ),然后调用nextTuple函数,发送数据供Bolt处理
- Bolt:在Topology中接受Spout组件发送的数据然后执行处理的组件。Bolt可以执行过滤、函数操作、合并、写数据库等操作。Bolt接受数据后会调用execute函数
- Tuple:数据传递的基本单元
- Stream:源源不断的Tuple组成了Stream
- Stream Grouping:定义了一个流向Bolt任务间该如何被切分
-
随机分组(Shuffle grouping):随机分发tuple到Bolt的任务,保证每个任务获得相等数量的tuple
- 字段分组(Fields grouping):根据指定字段分割数据流,并分组。例如,根据“user-id”字段,相同“user-id”的元组总是分发到同一个任务,不同“user-id”的元组可能分发到不同的任务
- tuple被复制到bolt的所有任务。这种类型需要谨慎使用
- 全部流都分配到bolt的同一个任务。明确地说,是分配给ID最小的那个task
- 无分组(None grouping):你不需要关心流是如何分组。目前,无分组等效于随机分组。但最终,Storm将把无分组的Bolts放到Bolts或Spouts订阅它们的同一线程去执行(如果可能)
- 直接分组(Direct grouping):这是一个特别的分组类型,元组生产者决定tuple由哪个元组处理者任务接收
架构
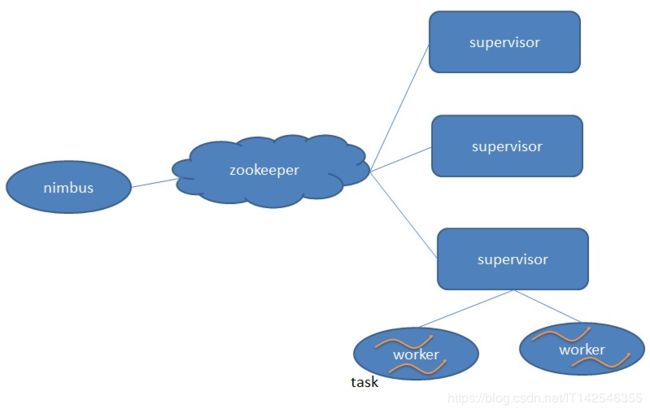 Storm架构图
Storm架构图
nimbus和supervisor不直接通信,而是通过zookeeper进行间接通信。nimbus和supervisor的状态信息全保存在zookeeper中,若nimbus进程或者supervisor进程意外终止,重启时能够借助zookeeper恢复之间的工作并且继续运行,这样的架构使得Storm及其稳定。故而,Storm集群需要依赖zookeeper集群。
一、部署说明
| bigdata.centos01 | bigdata.centos02 | bigdata.centos03 | |
| Zookeeper | Zookeeper | Zookeeper | Zookeeper |
| Storm | supervisor | nimbus UI supervisor |
supervisor |
如上表所示,bigdata.centos01、bigdata.centos02、bigdata.centos03是三台虚拟机的主机名,三台机器均部署zookeeper和启动supervisor进程,bigdata.centos02启动nimbus进程和UI监控服务。zookeeper版本是v3.4.7,storm版本为v1.2.3。这篇博客将不会介绍zookeeper集群的搭建,尚未搭建zookeeper集群的读者请参阅:zookeeper的配置和分布式部署
二、Storm配置和部署
1. 下载
- 下载
wget http://mirrors.tuna.tsinghua.edu.cn/apache/storm/apache-storm-1.2.3/apache-storm-1.2.3.tar.gz- 解压
# 解压
tar xzvf apache-storm-1.2.3.tar.gz
# 更名
mv apache-storm-1.2.3 storm-1.2.32. 配置
- 修改conf/storm.yaml
# 配置zookeeper集群
storm.zookeeper.servers:
- "bigdata.centos01"
- "bigdata.centos02"
- "bigdata.centos03"
# 配置zookeeper的端口,如果不是默认的2181,需要该配置项
storm.zookeeper.port: 2181
# 用于Storm存储数据
storm.local.dir: "/opt/modules/storm-1.2.3/data"
# 指定nimbus进程所在服务器
nimbus.seeds: ["bigdata.centos02"]
#指定supervisor节点上,启动worker时对应的端口号,每个端口对应槽,每个槽位对应一个worker
supervisor.slots.ports:
- 6700
- 6701
- 6702
- 6703
- 分发Storm
# 分发到centos01和centos03
scp -r storm-1.2.3 bigdata.centos01:/opt/modules
scp -r storm-1.2.3 bigdata.centos03:/opt/modules3. 服务启动
Storm服务启动前,务必启动zookeeper集群服务
- centos02启动nimbus、ui、supervisor
bin/storm nimbus &
bin/storm ui &
bin/storm supervisor &- centos01和centos03启动supervisor
bin/storm supervisor &三、wordcount测试
1. 程序编写
- 添加依赖
org.apache.storm
storm-core
1.2.3
- ReadFileSpout.java
package com.wangmh.storm.spout;
import org.apache.storm.spout.SpoutOutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichSpout;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Values;
import org.apache.storm.utils.Utils;
import java.util.Map;
import java.util.Random;
public class ReadFileSpout extends BaseRichSpout {
private SpoutOutputCollector collector;
private Random random;
/**
* @param map 应用程序能够读取的配置
* @param topologyContext 上下文
* @param spoutOutputCollector
*/
@Override
public void open(Map map, TopologyContext topologyContext, SpoutOutputCollector spoutOutputCollector) {
this.collector = spoutOutputCollector;
random = new Random();
}
/**
* storm框架有个while循环,一直调用nextTuple
*/
@Override
public void nextTuple() {
// 发送数据,使用collector.emit方法
String[] sentences = {
"the sentence is i love storm framework",
"storm hadoop spring",
"mapreduce yarn hdfs",
"hive hue pig zookeeper spark"
};
int randomInt = random.nextInt() % sentences.length;
if (randomInt < 0){
randomInt = -randomInt;
}
collector.emit(new Values(sentences[randomInt]));
Utils.sleep(300);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
outputFieldsDeclarer.declare(new Fields("sentence"));
}
}
- SentenceSplitBolt.java
package com.wangmh.storm.bolt;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Fields;
import org.apache.storm.tuple.Tuple;
import org.apache.storm.tuple.Values;
import java.util.Map;
public class SentenceSplitBolt extends BaseRichBolt {
private OutputCollector outputCollector;
/**
* @param map 配置文件
* @param topologyContext 上下文
* @param outputCollector 数据收集器
*/
@Override
public void prepare(Map map, TopologyContext topologyContext, OutputCollector outputCollector) {
// 可以做Kafka连接、redis连接、hdfs连接等
this.outputCollector = outputCollector;
}
@Override
public void execute(Tuple tuple) {
String sentence = tuple.getString(0);
System.out.println("Processing sentence:" + sentence);
String s = tuple.getStringByField("sentence");
String[] words = s.split(" ");
for (String word : words) {
outputCollector.emit(new Values(word,1));
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
outputFieldsDeclarer.declare(new Fields("word","num"));
}
}
- WordCountBolt.java
package com.wangmh.storm.bolt;
import org.apache.storm.task.OutputCollector;
import org.apache.storm.task.TopologyContext;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.base.BaseRichBolt;
import org.apache.storm.tuple.Tuple;
import java.util.HashMap;
import java.util.Map;
public class WordCountBolt extends BaseRichBolt {
private OutputCollector collector;
private Map wordcountMap;
@Override
public void prepare(Map map, TopologyContext topologyContext, OutputCollector outputCollector) {
// 可以做Kafka连接、redis连接、hdfs连接等
this.collector = outputCollector;
wordcountMap = new HashMap<>();
}
@Override
public void execute(Tuple tuple) {
String word = tuple.getStringByField("word");
Integer num = tuple.getIntegerByField("num");
Integer wordNum = wordcountMap.get(word);
if (wordNum == null){
wordcountMap.put(word,1);
}else{
wordcountMap.put(word,wordNum + num);
}
System.out.println("---------------result are as follows----------------");
for (Map.Entry entry : wordcountMap.entrySet()) {
System.out.println("("+ entry.getKey() +","+ entry.getValue() +")");
}
}
@Override
public void declareOutputFields(OutputFieldsDeclarer outputFieldsDeclarer) {
}
}
- WordCountTopology.java
package com.wangmh.storm.topology;
import com.wangmh.storm.bolt.SentenceSplitBolt;
import com.wangmh.storm.bolt.WordCountBolt;
import com.wangmh.storm.spout.ReadFileSpout;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.generated.AlreadyAliveException;
import org.apache.storm.generated.AuthorizationException;
import org.apache.storm.generated.InvalidTopologyException;
import org.apache.storm.topology.TopologyBuilder;
public class WordCountTopology {
public static void main(String[] args) throws InvalidTopologyException, AuthorizationException, AlreadyAliveException {
TopologyBuilder builder = new TopologyBuilder();
builder.setSpout("readFileSpont",new ReadFileSpout(),1);
builder.setBolt("splitBolt",new SentenceSplitBolt(),1).shuffleGrouping("readFileSpont");
builder.setBolt("wordcountBolt",new WordCountBolt(),1).shuffleGrouping("splitBolt");
// 配置项
Config config = new Config();
config.setDebug(false);
// 提交
if (args != null && args.length > 0){
// 集群模式
config.setNumWorkers(3);
StormSubmitter.submitTopology(args[0],config,builder.createTopology());
}else {
LocalCluster localCluster = new LocalCluster();
localCluster.submitTopology("wordcount",config,builder.createTopology());
}
}
}
2. 提交Storm集群运行
提交Storm集群之前,需要将源代码打包成jar文件
- 提交运行
# 格式:
# bin/storm jar [jar路径] [拓扑包名.拓扑类名] [拓扑名称]
bin/storm jar /opt/datas/wordcount.jar com.wmh.storm.topology.WordCountTopology wordcount- 监控运行
# 访问UI监控界面
http://bigdata.centos02:8080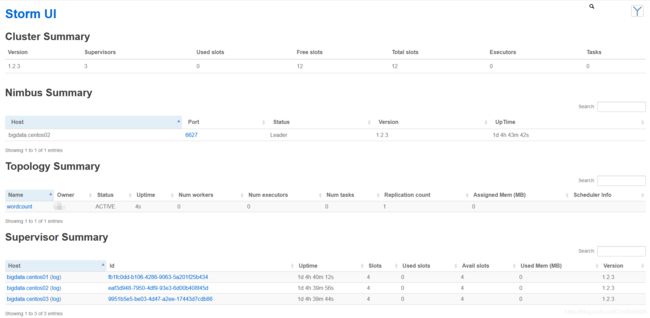
3. 常用命令
- 杀死任务
# 执行kill命令时可以通过-w [等待秒数]指定拓扑停用以后的等待时间,-w是可选项
storm kill [拓扑名称] -w [sec]- 停用任务
storm deactivte [拓扑名称]- 启用任务
storm activate [拓扑名称]- 重新部署任务
再平衡使你重分配集群任务。这是个很强大的命令。比如,你向一个运行中的集群增加了节点。再平衡命令将会停用拓扑,然后在相应超时时间之后重分配worker,并重启拓扑
storm rebalance [拓扑名称]