基于Scrapy框架爬取CSDN某位博主的全部博客
摘要
随着网络迅速发展,人们在网络上发表自己的观点和看法,记录自己的生活和学习经历在博客上,对于大量的博客,如何进行搬家和处理,那是一个很让人头大的事情,在这样的情形下,提出采用基于Scrapy的python爬虫对大量的博客内容进行快速搬家,来适应如今大规模、海量数据的发展。
1.引言
随着网络的迅速发展,万维网成为大量信息的载体,人们通过网络记录自己的博客,简易迅速便捷地发布自己的心得或学习笔记,当你在某平台写了大量博客后,想要将博客搬家,移到别的平台,或者自己的个人网站上,或者你想将博客下载下来,进行保存,你是否会担忧,如何将博客弄下来,自己手动一篇篇保存下来吗?如何有效地提取并利用这些信息成为一个巨大的挑战。针对这个问题,提出了网络爬虫的方式来实现博客的搬家和下载,利用流行的python,基于Scrapy框架来实现。
2.系统结构
基于Scrapy爬取CSDN某位博主的所有博客的系统结构图:
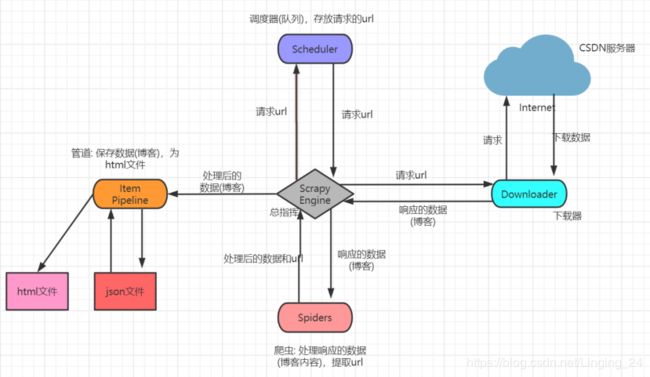
- crapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
- Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
- Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理。
- Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器)。
- Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方.
- Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。
- Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)。
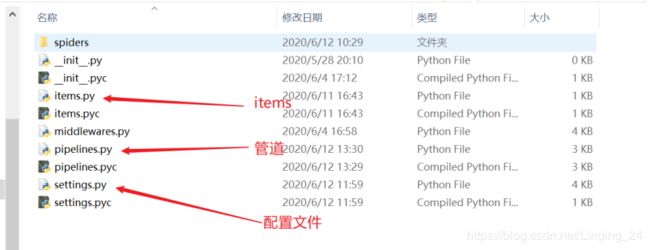
项目目录:

3.实现代码
首先编写爬虫:
在配置文件setting.py中定义:

3.1.导入模块和变量,并对中文的支持。
# -*- coding: utf-8 -*-
import scrapy
from csdnSpider.settings import prefix_url
from csdnSpider.items import CsdnspiderItem
from csdnSpider.settings import CsdnPage
3.2.定义爬虫名字和爬虫范围及url
name = 'csdn'
allowed_domains = ['csdn.net']
start_urls = [prefix_url] #博客的主页,即某个博主博客列表的第一页

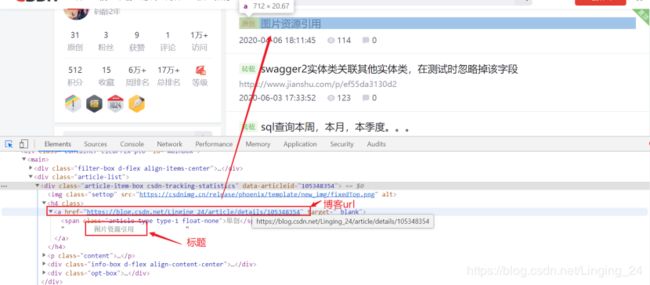
3.3.获取博客列表
boxs = response.xpath('//div[@class="article-item-box csdn-tracking-statistics"]')

3.4.遍历列表获取博客标题和url
for box in boxs:
item = CsdnspiderItem() #初始容器
item['title'] = box.xpath('./h4/a/text()')[1].extract().strip()
item['url'] = box.xpath('./h4/a/@href')[0].extract()
3.5.拿到url之后,发送请求,请求博客的网页内容:
yield scrapy.Request(item['url'], meta={'item': item}, callback=self.parse_article)
在请求中调用回调函数parse_article,用于请求博客文章的网页内容,并返回可迭代的生成器。
这是回调函数获取博客内容:

# 解析content
def parse_article(self,response):
item = response.request.meta['item']
content = response.xpath('//div["@id = article_content"]/div[@id="content_views"]').extract()
item['content'] = content
yield item
3.6.上述只是请求一页的博客,那么就需要翻页:

# 实现翻页的功能
for page in range(2, CsdnPage+1):
url = prefix_url + "/article/list/%s" %(page)
yield scrapy.Request(url, callback=self.parse)
3.7.接下来在pipelines.py中进行数据处理:
保存博客标题、url、内容为json文件。
#初始化
def __init__(self):
self.f = open('csdn.json','wb')
self.exporter = JsonItemExporter(self.f, encoding='utf-8', ensure_ascii=False)
# 开始写入
self.exporter.start_exporting()
#保存
def process_item(self, item, spider):
self.exporter.export_item(item)
return item
def open_spider(self,spider):
pass
#关闭
def close_spider(self,spider):
self.exporter.finish_exporting()
self.f.close()
3.8.保存为json文件后,读取json文件,对博客内容进行处理,保存为html文件:
#对博客内容添加html的文件结构
def deal_content(self,content,title,url):
text = '\n'\
'\n'\
'\n'\
'\n'\
''</span><span class="token operator">+</span>title<span class="token operator">+</span><span class="token string">' \n'\
'\n'\
'\n'\
'\n'\
'\n'\
'\n'\
'\n'
return text
def close_spider(self,spider):
self.exporter.finish_exporting()
self.f.close()
print(u'---------------解析json数据------------------')
with open('csdn.json','r')as fp:
json_data = json.load(fp)
#print('这是文件中的json数据:',json_data[1]['content'][0])
print(u'博客总数:'+str(len(json_data)))
#遍历数据保存html文件
for data in json_data:
content = data['content'][0]
title = data['title']
url = data['url']
title = title.replace("\\","-").replace(':','=')[0:30]
content = self.deal_content(content,title,url)
#name = "blog\\" + title +".html"
name = ur'blog\{0}.html'.format(title)
with open (name,"wb") as f:
#写文件用bytes而不是str,所以要转码
by = bytes(content)
f.write(by)
由于博客的标题过长或者包含特殊字符会出错:所以将一些符号进行替换,下面是这些字符:
'''
路劲中包含这些报错。
< (less than)
> (greater than)
: (colon)
" (double quote)
/ (forward slash)
\ (backslash)
| (vertical bar or pipe)
? (question mark)
* (asterisk)
'''
下面是爬虫的全部代码:
主要爬虫:csdn.py
# -*- coding: utf-8 -*-
import scrapy
from csdnSpider.settings import prefix_url
from csdnSpider.items import CsdnspiderItem
from csdnSpider.settings import CsdnPage
class CsdnSpider(scrapy.Spider):
#prefix_url = 'https://blog.csdn.net/Linging_24' #博客的主页,即某个博主博客列表的第一页地址
name = 'csdn'
allowed_domains = ['csdn.net']
start_urls = [prefix_url] #博客的主页,即某个博主博客列表的第一页
def parse(self, response):
boxs = response.xpath('//div[@class="article-item-box csdn-tracking-statistics"]')
for box in boxs:
item = CsdnspiderItem()
# 类似于字典的对象
# ************将item对象实例化在for循环里面, 否则每次会覆盖之前item的信息;*******
item['title'] = box.xpath('./h4/a/text()')[1].extract().strip()
# 当前div标签里的h4标签下的a标签里的文本信息,有两个文本信息取索引为1的,
# 不加extract()将生成一个对象,因为标题中打印左右两侧右空格 所以用strip去掉
#
#
#
# 原
# nginx设置文件介绍
#
item['url'] = box.xpath('./h4/a/@href')[0].extract()
# 这个url进去就是博客内容
# print("1. *****************", item['title'])
yield scrapy.Request(item['url'], meta={'item': item}, callback=self.parse_article)
# 返回一个请求给parse_article,将item中获得的url地址返回,meta 传递的内容
# 实现翻页的功能
for page in range(2, CsdnPage+1):
url = prefix_url + "/article/list/%s" %(page)
yield scrapy.Request(url, callback=self.parse)
# 解析content
def parse_article(self,response):
item = response.request.meta['item']
#content = response.xpath('//div["article_content"]').extract()[0]
content = response.xpath('//div["@id = article_content"]/div[@id="content_views"]').extract()
item['content'] = content
yield item
Pipelines.py
# -*- coding: utf-8 -*-
from scrapy.exporters import JsonItemExporter
import sys
reload(sys)
sys.setdefaultencoding( "utf-8" )
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: https://docs.scrapy.org/en/latest/topics/item-pipeline.html
import json
class CsdnspiderPipeline(object):
def __init__(self):
self.f = open('csdn.json','wb')
self.exporter = JsonItemExporter(self.f, encoding='utf-8', ensure_ascii=False)
# 开始写入
self.exporter.start_exporting()
def deal_content(self,content,title,url):
text = '\n'\
'\n'\
'\n'\
'\n'\
''</span><span class="token operator">+</span>title<span class="token operator">+</span><span class="token string">' \n'\
'\n'\
'\n'\
'\n'\
'\n'\
'\n'\
'\n'
return text
def process_item(self, item, spider):
self.exporter.export_item(item)
return item
def open_spider(self,spider):
pass
def close_spider(self,spider):
self.exporter.finish_exporting()
self.f.close()
print(u'---------------解析json数据------------------')
with open('csdn.json','r')as fp:
json_data = json.load(fp)
#print('这是文件中的json数据:',json_data[1]['content'][0])
print(u'博客总数:'+str(len(json_data)))
#遍历数据保存html文件
for data in json_data:
content = data['content'][0]
title = data['title']
url = data['url']
title = title.replace("\\","-").replace(':','=')[0:30]
content = self.deal_content(content,title,url)
#name = "blog\\" + title +".html"
name = ur'blog\{0}.html'.format(title)
with open (name,"wb") as f:
#写文件用bytes而不是str,所以要转码
by = bytes(content)
f.write(by)
'''
路劲中包含这些报错。
< (less than)
> (greater than)
: (colon)
" (double quote)
/ (forward slash)
\ (backslash)
| (vertical bar or pipe)
? (question mark)
* (asterisk)
'''
Items.py
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# https://docs.scrapy.org/en/latest/topics/items.html
import scrapy
class CsdnspiderItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
title = scrapy.Field()
url = scrapy.Field()
content = scrapy.Field()
Setting.py
#某个博客博主的博客首页地址,即博客列表的第一页
prefix_url = 'https://blog.csdn.net/Linging_24'
#博客列表的页数
CsdnPage = 2
4.实验
cmd进入项目目录,运行scrapy crawl csdn

运行结果:

爬取的博客:
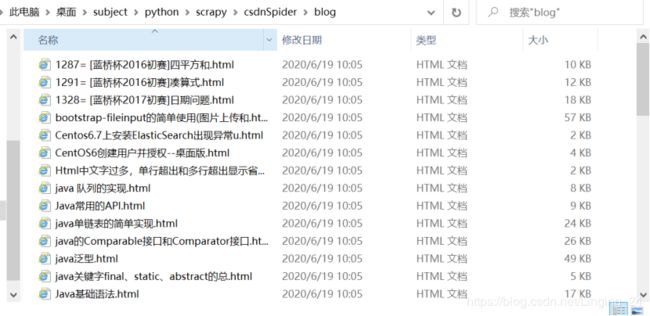
查看爬取的博客:


5.总结和展望
以上就是基于Scrapy的爬虫对csdn某位博主的博客进行下载,实现搬家,你也可以进行保存数据库操作,然后在自己的个人博客上展示出来,在爬取别人博客的同时,需要遵重博主成果,不做违规的事情。
对于小量博客的爬取,一般速度没什么问题,但对于大量博客的爬取,速度可能有问题,这是就得进行拓展,分布式爬取,提高爬取效率。