数据分析系列之电力窃漏电用户自动识别
在线监测用户用电负荷数据,经过数据预处理,得到模型输入数据,利用构建好的识别模型计算用户窃漏电诊断结果,实现窃漏电用户的实时诊断,并与实际稽查结果对比
背景与挖掘目标
传统的防窃漏电方法主要是通过定期巡检,定期校验电表,用户举报窃电等方法来发现窃电或者计量装置故障,但这种方法对人依赖性太大,抓漏查漏的目标不明确.当前,供电局通过营销稽查人员,用电检查人员和计量工作人员利用计量异常报警功能和电量数据查询功能开展用户在线监控工作,通过采集电量异常,负荷异常,终端报警,主站报警,线损异常等数据建立数据分析模型,来实时监控窃漏电用户和发现计量设备故障.根据报警事件前后发生客户计量点有关的电流,电压,负荷数据等情况,构建基于指标加权的用电异常分析模型,实现检查客户是否存在窃电,违章用电及计量装置故障等.
以上防止窃漏电诊断方法,虽然能够获得用户异常的某些数据,但由于终端误报或者漏报过多,无法真正快速定位漏电用户,往往令稽查人员无所适从,而且采用这种方法建模时,模型输入指标权重需要专家的知识和经验来判断,具有很大的主观性,有明显缺陷.
现有的电力计量自动化系统能够采集到各相电流,电压等用电负荷数据以及用户异常数据,异常警告信息和用电负荷数据能够反映用户的用电情况,同时稽查工作人员也会通过在线稽查和现场稽查来找出窃漏电用户,并录入系统.若能根据这些关键信息提取出窃漏电用户的关键特征,构建窃漏电用户的识别模型,就能自动检查,判断用户是否存在窃漏电行为.
表给出某企业大用户的用电负荷数据,采集时间间隔为15分钟,即0.25小时,可进一步计算用户电量.
| 用户编号 | 时间 | 有功总 | B相 | C相 | 电流A相 | 电流B相 | 电流C相 | 电压A相 | 电压B相 | 电压C相 | 功率因素 | 功率因素A | 功率因素B |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1001 | 2019 | 202 | 0 | 349.2 | 33.6 | 0 | 33.4 | 10500 | 0 | 10500 | 0.784 | 0.573 | -10000 |
下表给出该企业大用户的终端报警数据,其中与窃漏电相关的警报能较好的识别用户的窃漏电行为.
| 用户名称 | 时间 | 计量点ID | 报警编号 | 报警名称 |
|---|---|---|---|---|
| 某企业大用户 | 2019/05/21 6:12 | 1001 | 152 | 电流不平衡 |
| 某企业大用户 | 2019/05/23 23:02 | 1001 | 143 | A相电流过负荷 |
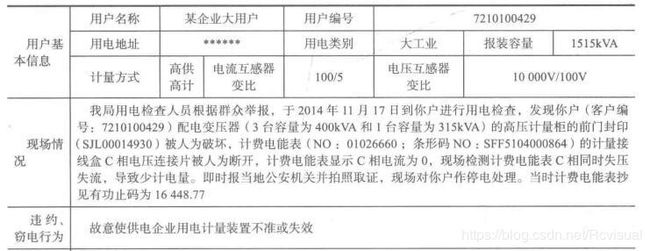
下表为某企业大用户违约,窃电处理通知书,表中记录了用户的用电类别和窃电时间
本次数据挖掘的目标如下:
1.归纳出窃漏电用户的关键特征,构建窃漏电用户的识别模型.
2.利用实时监测数据,调用窃漏电用户识别模型实现实时诊断.
分析方法与过程
窃漏电用户在电力计量自动化系统的监控大用户中只占一小部分,同时某些大用户也不可能存在窃漏电行为,例如银行,学校,税务等非居民类别,故在数据预处理时有必要要将这部分用户剔除.系统中的用电负荷也不能直接体现用户的窃漏电行为,终端报警存在很多误报和漏报的情况,故需要进行数据探索和预处理,总结窃漏电用户的行为规律,再从数据中提炼出描述窃漏电用户的特征指标,最终结合历史窃漏电用户信息,整理识别模型的专家样本数据集,在进一步构建分类模型,实现窃漏电用户的自动识别.窃漏电用户识别流程如图所示,主要包括以下步骤:
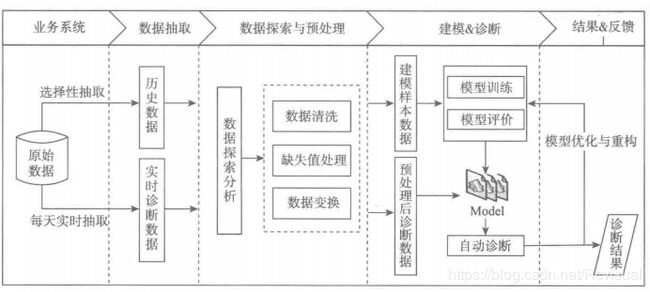
1.从电力计量系统自动化系统和营销系统有选择的抽取部分大用户数据用电负荷,终端报警以及违约窃电处罚信息等原始数据.
2.对样本数据探索分析,剔除不可能存在窃漏电行为行业的用户,即白名单用户,初步审视正常用户和窃漏电用户的用电特征.
3.对样本数据进行数据预处理,包括数据清洗,缺失值处理和数据变换.
4.构建专家样本数据集.
5.构建窃漏电用户识别模型.
6.在线监测用户用电负荷以及终端报警,调用模型实现实时诊断.
数据抽取
与窃漏电相关的包括用电负荷数据,终端报警数据,违约窃电处罚信息以及用户档案资料等,故进行窃漏电诊断模型时需从营销系统和计量自动化系统中抽取如下数据:
(1)从营销系统抽取的数据
1)用户基本信息:用户名称,用户编号,用电地址,用电类别,报装容量,计量方式,电流互感器变比,电压互感器变比.
2)违约,窃电处理记录.
3)计量方法及依据.
(2)从计量自动化系统采集的数据属性
1)实时负荷:时间点,计量点,总有功功率,A/B/C相有功功率,A/B/C相电流,A/B/C相电压,A/B/C相功率因素.
2)终端报警.
为了尽可能全面覆盖各种窃漏电方式,建模样本要包含不同用电类别的所有窃漏电用户及部分正常用户,窃漏电用户的开始时间和结束时间是表征窃漏电的关键时间节点,在这些时间节点上,用电负荷以及窃漏电数据也会有一定的特征变化,故样本数据抽取时必须包含关键时间节点前后一定范围的数据,并通过用户的负荷数据计算当天的用电量,计算公式为: f l = 0.25 ∑ m i ∈ l m i f_{l}=0.25\sum_{m_{i}\in l}m_{i} fl=0.25∑mi∈lmi,其中, f l f_{l} fl是第l天的用电量, m i m_{i} mi是第l天每隔15分钟的总有功率,对其累加求和得到当天的用电量.
基于此,本次数据挖掘抽取某市近5年来所有窃漏电用户有关数据和不同用电类别正常用电用户208个用户案例,时间为2009年1月1日至2014年12月31日,同时包含每天是否有窃漏电情况的标识.
数据探索分析
数据探索分析是对数据进行初步的研究,发现数据的内在规律特征,有助于选择合适的数据预处理和数据分析技术,本案例采用分布分析和周期性分析等方法对用电量数据进行数据探索分析.
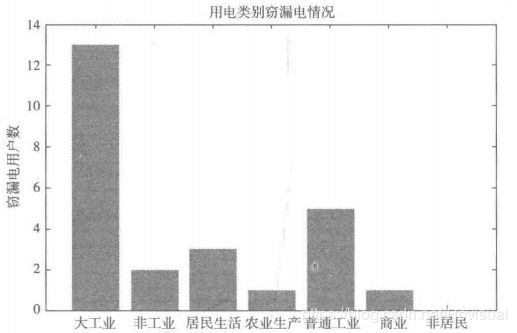
1.对比分析
对2009年1月1日至2014年12月31日共5年所有窃漏电用户进行分布分析,统计出各个用电类别的窃漏电用户分布情况,发现非居民类别不存在窃漏电情况,故接下来的分析不考虑非居民类别的用电数据.
2.周期性分析
随机抽取一个正常用户和一个窃漏电用户,采用周期性分析对用电量进行探索.
(1)正常用电电量分析
正常用电量分析见图和表demo/data/用户正常用电量数据.xlsx,总体表现该用户比较平稳,没有太大的波动,这就是正常用电的电量指标特征.
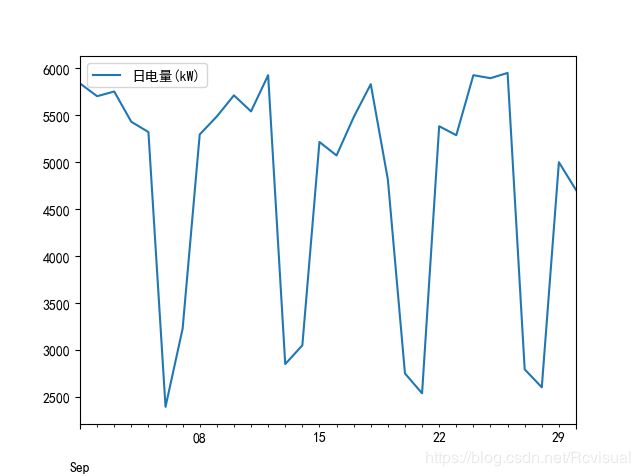
代码示例:
#-*- coding: utf-8 -*-
#时序图
import pandas as pd
#参数初始化
discfile = '../data/用户正常用电量数据.xlsx'
forecastnum = 5
#读取数据,指定日期列为指标,Pandas自动将“日期”列识别为Datetime格式
data = pd.read_excel(discfile, index_col = u'日期')
#时序图
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] #用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False #用来正常显示负号
data.plot()
plt.show()
同理读取窃电漏电用户电量数据demo/data/用户窃电用电量数据.xlsx,绘制窃漏电用户电量趋势图,这里可以看出该用户用电量出现明显下降趋势,这就是用户异常用电的电量指标特征.
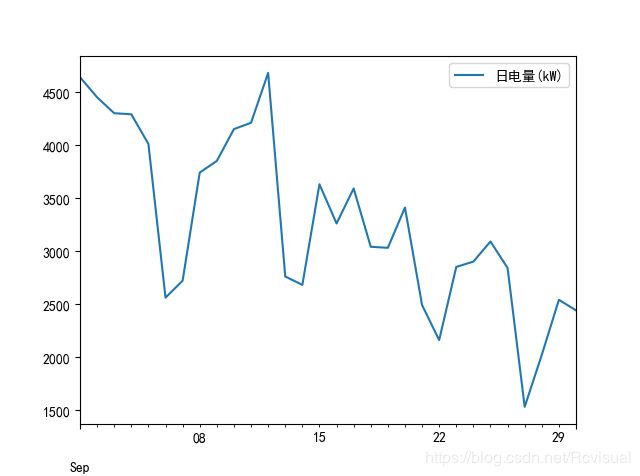
分析结论:从图中可以看出,正常用电到窃漏电过程是用电量持续下降的过程,该用户从2014/9/1开始用电量下降,这就是用户开始窃漏电时表现出来的重要特征.
数据预处理
本案例主要是从数据清洗,缺失值处理和数据变换等方面对数据进行预处理.
1.数据清洗
数据清洗的主要目的是从业务以及建模相关需要方面考虑,筛选出需要的数据.由于原始数据中并不是所有的数据都要进行分析,因此需要在进行数据处理时,将多余的数据过滤.本案例主要进行如下操作:
1)通过数据探索分析,发现在用电类别,发现用电类别,非居民用电类别不可能存在漏电窃电现象,需要将非居民用电类别的用电数据过滤掉.
2)结合本案例业务场景,节假日用电量与工作日相比,会明显偏低,为了尽可能达到较好的效果,过滤节假日数据.
2.缺失值处理
在原始计量数据,特别是用户电量数据抽取中,发现缺失现象,若将这些值抛弃掉,会严重影响供出电量计算结果,最终导致日线损率数据误差很大,为了达到较好的建模效果,需要对缺失值进行处理,本案例采用拉格朗日插值法对缺失值进行插补.对demo/data/missing_data.xls表中数据进行插补,表中为三个用户一个月工作日的电量数据,对缺失值采用拉格朗日插值法进行插补.
拉格朗日插值插补方法具体为:首先从原始数据集中确定因变量和自变量,取出缺失值前后5个数据(前后数据中遇到数据不存在或者为空的,直接将数据舍去,将仅有数据组成一组),根据取出的十个数据组成一组,然后利用拉格朗日公式求出近似函数,再将缺失值代入,求出插补值.对全部缺失数据进行插补,直到不存在缺失值为止,数据插补代码如下:
#-*- coding: utf-8 -*-
#拉格朗日插值代码
import pandas as pd #导入数据分析库Pandas
from scipy.interpolate import lagrange #导入拉格朗日插值函数
inputfile = '../data/missing_data.xls' #输入数据路径,需要使用Excel格式;
outputfile = '../tmp/missing_data_processed.xls' #输出数据路径,需要使用Excel格式
data = pd.read_excel(inputfile, header=None) #读入数据
#自定义列向量插值函数
#s为列向量,n为被插值的位置,k为取前后的数据个数,默认为5
def ployinterp_column(s, n, k=5):
y = s[list(range(n-k, n)) + list(range(n+1, n+1+k))] #取数
y = y[y.notnull()] #剔除空值
return lagrange(y.index, list(y))(n) #插值并返回插值结果
#逐个元素判断是否需要插值
for i in data.columns:
for j in range(len(data)):
if (data[i].isnull())[j]: #如果为空即插值。
data[i][j] = ployinterp_column(data[i], j)
data.to_excel(outputfile, header=None, index=False) #输出结果
3.数据变换
通过计量系统采集的电量,负荷虽然在一定程度上反映用户的窃漏电行为的某些规律,当要作为构建模型的专家样本,特征不明显,需要重新构造.基于数据变换,得到新的评价指标来表征窃漏电行为具有的规律,其评价指标体系如图:
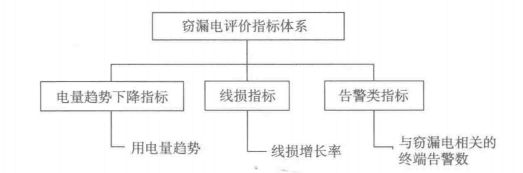
窃漏电评价指标:
(1)电量趋势下降指标
在周期性分析中,发现正常用户的用电量较为平稳,窃漏电用户呈现下降趋势,然后趋于平缓.因此可以考虑前后几天作为统计窗口期,考虑期间的下降趋势,利用电量做直线拟合得到斜率作为衡量,如果斜率随时间不断下降,那么用户窃漏电的可能性就比较大.如图所示,第一幅图显示每天的用电量,之后随着时间的推移,获得各自统计窗口期以用电量做直线拟合的斜率,可以看出斜率在不断变换,随时间逐步下降.
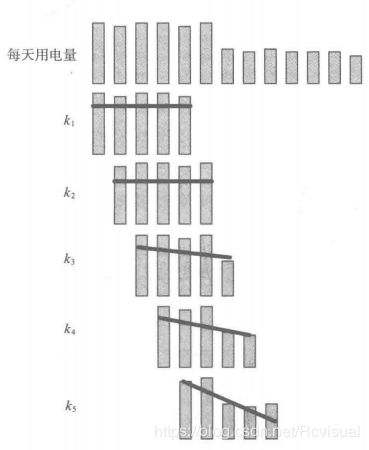
对统计当天设定前后5天作为统计窗口期,计算这11天内电量下降情况.首先计算这11天中每天的电量趋势,其中第i天的用电量趋势是考虑前后5天的用电斜率,即: k i = ∑ l = i − 5 i + 5 ( f l − f ‾ ) ( l − l ‾ ) ∑ l = i − 5 i + 5 ( l − l ‾ ) 2 k_{i}=\frac{\sum_{l=i-5}^{i+5}(f_{l}-\overline{f})(l-\overline{l})}{\sum_{l=i-5}^{i+5}(l-\overline{l})^{2}} ki=∑l=i−5i+5(l−l)2∑l=i−5i+5(fl−f)(l−l),其中 f ‾ = 1 11 ∑ l = i − 5 i + 5 f i \overline{f}=\frac{1}{11}\sum_{l=i-5}^{i+5}f_{i} f=111∑l=i−5i+5fi, l ‾ = 1 11 ∑ l = i − 5 i + 5 l i \overline{l}=\frac{1}{11}\sum_{l=i-5}^{i+5}l_{i} l=111∑l=i−5i+5li, k i k_{i} ki为第i天的电量趋势, f l f_{l} fl为第l天的用电量.
若用电量趋势是不断下降的,则具有一定的窃电嫌疑,故计算这11天内,当天比前一天用电量趋势为递减的天数,即设有 y = { 1 , k i < k i − 1 0 , k i ≥ k i − 1 y=\begin{cases}1,&k_{i}<k_{i-1}\\0,&k_{i}\geq k_{i-1}\end{cases} y={1,0,ki<ki−1ki≥ki−1.
则11天内的电量下降趋势指标为 T = ∑ n = i − 4 i + 5 D ( n ) T=\sum_{n=i-4}^{i+5}D(n) T=∑n=i−4i+5D(n)
(2)线损指标
线损率是衡量电路损失的比率,同时结合线户的拓扑关系计算出用户所属线路当天的线损率,一条线路上同时供给多个用户,若第l天的线路供电量为 s l s_{l} sl,线路上各个用户的总用电量为 ∑ m f l ( m ) \sum_{m}f_{l}^{(m)} ∑mfl(m),线路线损率计算公式为: t l = s l − ∑ m f l ( m ) s l × 100 % t_{l}=\frac{s_{l}-\sum_{m}f_{l}^{(m)}}{s_{l}}\times 100\% tl=slsl−∑mfl(m)×100%,如图为线户拓扑关系:
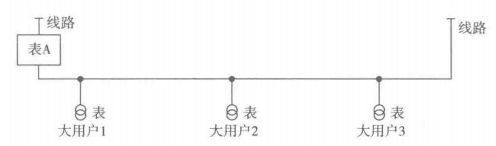
线路的线损率可以作为用户线损率的参考值,若用户发生窃漏电,则当天的线损率会上升,但是由于用户每天的用电量存在波动,单纯以当天的线损率上升作为窃漏电特征误差过大,所以考虑前后几天的线损率平均值,判断其增长率是否大于1%,若线损率增长率大于1%具有窃漏电可能性.
对统计当天设置前后5天为统计窗口期,首先分别统计当天与前5天之间的线损率平均值 V i 1 V_{i}^{1} Vi1和当天与后5天之间的线损率平均值 V i 2 V_{i}^{2} Vi2,若 V i 1 V_{i}^{1} Vi1比 V i 2 V_{i}^{2} Vi2的增长率大于1%,则认为具有一定的窃电嫌疑,故定义线损指标为: E ( i ) = { 1 , V i 1 − V i 2 V i 2 > 1 % 0 , V i 1 − V i 2 V i 2 ≤ 1 % E(i)=\begin{cases}1,&\frac{V_{i}^{1}-V_{i}^{2}}{V_{i}^{2}}>1\%\\0,&\frac{V_{i}^{1}-V_{i}^{2}}{V_{i}^{2}}\leq1\%\end{cases} E(i)=⎩⎨⎧1,0,Vi2Vi1−Vi2>1%Vi2Vi1−Vi2≤1%
(3)告警类指标
与窃漏电相关的终端报警主要有电压缺相,电压断相,电流反极性等告警,计算发生与窃漏电相关的终端报警次数总和,作为告警类指标.
构建专家样本
对2009年1月1日至2014年12月31日所有窃漏电用户及正常用户的电量,告警及线损数据和该用户在当天是否窃漏电的标识,按照窃漏电评价指标进行处理并选择其中291个样本数据,得到专家样本库,数据表详见demo/data/model.xls.
模型构建
构建窃漏电用户识别模型
在专家样本准备完成后需要划分测试样本和训练样本,随机选取20%作为测试样本,剩下的作为训练样本.窃漏电用户识别可以通过构建分类预测模型来实现,比较常用的分类预测模型有LM神经网络和CART决策树,各个模型有各个模型的优缺点,故采用这两种方法构建窃漏电用户识别,并从中选择最优的分类模型.构建LM神经网络模型和CART决策树时模型输入项包括电量下降指标,线损类指标和告警类指标,输出项为窃漏电标识.
(1)数据划分
对专家样本随机选取20%作为测试样本,剩下的80%作为训练样本,其代码清单:
import pandas as pd #导入数据分析库
from random import shuffle #导入随机函数shuffle,用来打算数据
datafile = '../data/model.xls' #数据名
data = pd.read_excel(datafile) #读取数据,数据的前三列是特征,第四列是标签
data = data.as_matrix() #将表格转换为矩阵
shuffle(data) #随机打乱数据
p = 0.8 #设置训练数据比例
train = data[:int(len(data)*p),:] #前80%为训练集
test = data[int(len(data)*p):,:] #后20%为测试集
(2)LM神经网络
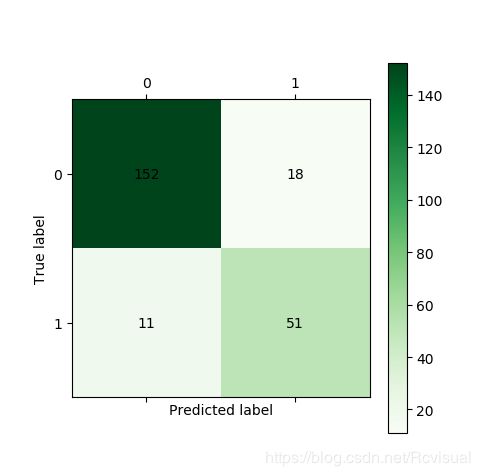
人工神经网络(Artificial Neural Networks,ANN)是模拟生物神经网络进行信息处理的一种数学模型.常用的分类与预测的人工神经网络算法有BP神经网络和LM神经网络.BP神经网络是一种按误差逆向传播算法训练的多层前馈网络,LM神经网络是基于梯度下降法和牛顿法结合的多层前馈网络,LM神经网络迭代次数少,收敛速度快和精确度高,故文案例选用LM神经网络进行用户分类.使用Kears库为我们建立神经网络模型,设定LM神经网络的输入节点数为3,输出节点数为1,隐藏节点数为10,使用Adam方法求解.对于激活函数使用Relu(x)=max(x,0),可以得到训练样本的混淆矩阵图,算得分类正确率(161+58)/(161+58+6+7)=94.4%,正常用户被误判为窃漏电概率是7/(161+7)=4.2%,窃漏电用户被误判正常用户概率是6/(6+58)=9.4%.构建LM神经网络模型代码:
#接分类代码
#构建LM神经网络模型
from keras.models import Sequential #导入神经网络初始化函数
from keras.layers.core import Dense, Activation #导入神经网络层函数、激活函数
netfile = '../tmp/net.model' #构建的神经网络模型存储路径
from matplotlib.pyplot import plot as plt
net = Sequential() #建立神经网络
net.add(Dense(input_dim = 3, output_dim = 10)) #添加输入层(3节点)到隐藏层(10节点)的连接
net.add(Activation('relu')) #隐藏层使用relu激活函数
net.add(Dense(input_dim = 10, output_dim = 1)) #添加隐藏层(10节点)到输出层(1节点)的连接
net.add(Activation('sigmoid')) #输出层使用sigmoid激活函数
net.compile(loss = 'binary_crossentropy', optimizer = 'adam') #编译模型,使用adam方法求解##, class_mode = "binary"
net.fit(train[:,:3], train[:,3], epochs=1000, batch_size=1) #训练模型,循环1000次
net.save_weights(netfile) #保存模型
predict_result = net.predict_classes(train[:,:3]).reshape(len(train)) #预测结果变形
'''这里要提醒的是,keras用predict给出预测概率,predict_classes才是给出预测类别,而且两者的预测结果都是n x 1维数组,而不是通常的 1 x n'''
from cm_plot import * #导入自行编写的混淆矩阵可视化函数
cm_plot(train[:,3], predict_result).show() #显示混淆矩阵可视化结果
import matplotlib.pyplot as plt
from sklearn.metrics import roc_curve #导入ROC曲线函数
from dt_model import *
predict_result = net.predict(test[:,:3]).reshape(len(test))
fpr, tpr, thresholds = roc_curve(test[:,3], predict_result, pos_label=1)
plt.plot(fpr, tpr, linewidth=2, label = 'ROC of CART_tree', color = 'green') #作出ROC曲线
plt.plot(fpr1, tpr1, linewidth=2, label = 'ROC of LM') #作出ROC曲线
plt.xlabel('False Positive Rate') #坐标轴标签
plt.ylabel('True Positive Rate') #坐标轴标签
plt.ylim(0,1.05) #边界范围
plt.xlim(0,1.05) #边界范围
plt.legend(loc=4) #图例
plt.savefig('../tmp/ROC of CART_tree and LM.png')
plt.show() #显示作图结果
利用训练样本构建LM神经网络的混淆矩阵图:
(3)CART决策树
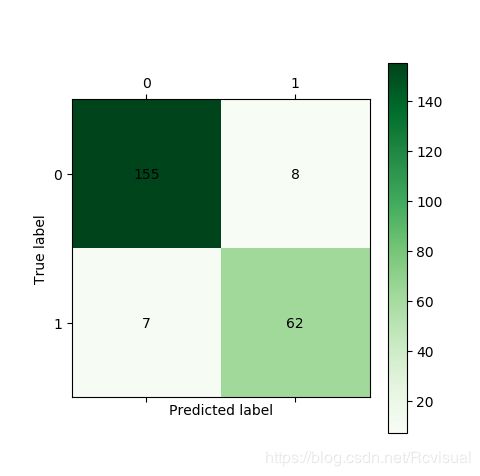
通过Scikit-Learn利用样本集构建CART决策树,得到混淆矩阵如图所示,构建决策树代码:
#-*- coding: utf-8 -*-
#-*- coding: utf-8 -*-
#构建并测试CART决策树模型
import pandas as pd #导入数据分析库
from random import shuffle #导入随机函数shuffle,用来打算数据
datafile = '../data/model.xls' #数据名
data = pd.read_excel(datafile) #读取数据,数据的前三列是特征,第四列是标签
data = data.as_matrix() #将表格转换为矩阵
shuffle(data) #随机打乱数据
p = 0.8 #设置训练数据比例
train = data[:int(len(data)*p),:] #前80%为训练集
test = data[int(len(data)*p):,:] #后20%为测试集
#构建CART决策树模型
from sklearn.tree import DecisionTreeClassifier #导入决策树模型
treefile = '../tmp/tree.pkl' #模型输出名字
tree = DecisionTreeClassifier() #建立决策树模型
tree.fit(train[:,:3], train[:,3]) #训练
#保存模型
from sklearn.externals import joblib
from matplotlib.pyplot import plot as plt
joblib.dump(tree, treefile)
from cm_plot import * #导入自行编写的混淆矩阵可视化函数
cm_plot(train[:,3], tree.predict(train[:,:3])).show() #显示混淆矩阵可视化结果
#注意到Scikit-Learn使用predict方法直接给出预测结果。
print(tree.predict(train[:,:3]))
print(tree.predict_proba(test[:,:3])[:,1])
from sklearn.metrics import roc_curve #导入ROC曲线函数
fpr1, tpr1, thresholds = roc_curve(test[:,3], tree.predict_proba(test[:,:3])[:,1], pos_label=1)
plt.plot(fpr1, tpr1, linewidth=2, label = 'ROC of CART', color = 'green') #作出ROC曲线
plt.xlabel('False Positive Rate') #坐标轴标签
plt.ylabel('True Positive Rate') #坐标轴标签
plt.ylim(0,1.05) #边界范围
plt.xlim(0,1.05) #边界范围
plt.legend(loc=4) #图例
plt.show() #显示作图结果
利用训练样本构建决策树的混淆矩阵图:
2.模型评价
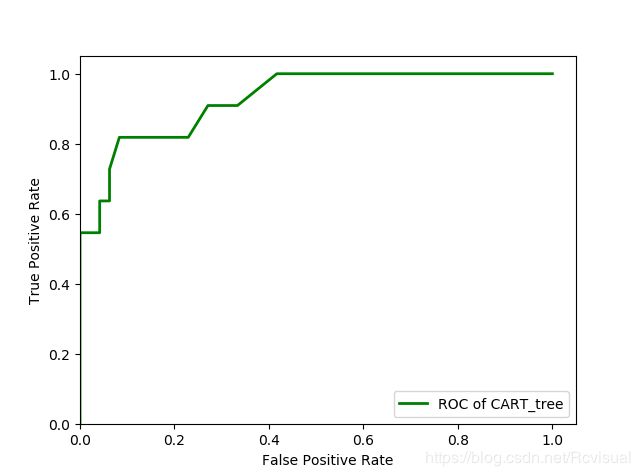
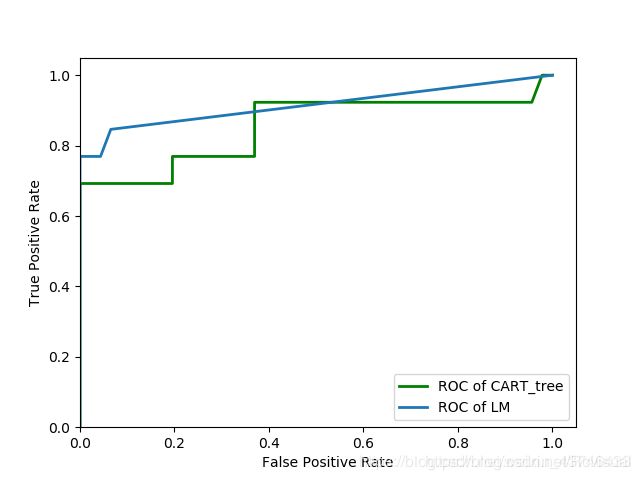
对于训练样本,LM神经网络和CART决策树的分类准确率相差不大,分别为94%和93%,为了进一步评估模型分类的性能,故利用测试样本对两个模型进行评价,利用ROC曲线评价方法进行评估,一个优秀的分类器对应的ROC曲线应该是尽量靠近左上角,分别画出LM神经网络和CART决策树在测试样本下的ROC曲线,对比发现LM神经网络的ROC曲线比CART决策树的ROC曲线更加靠近单位方形的左上角,LM神经网络的ROC曲线下面积更大,说明LM神经网络模型的分类性能更好.
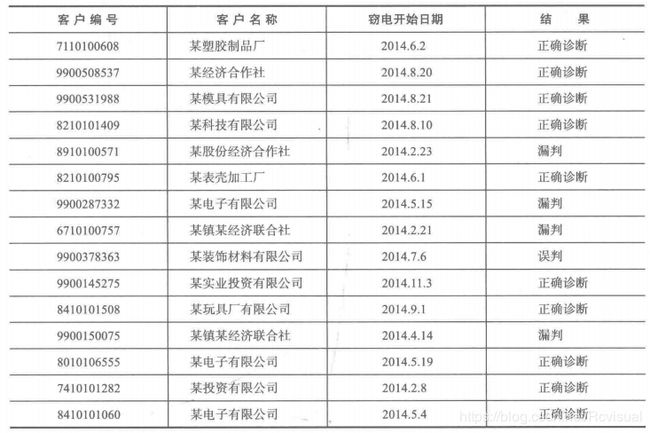
3.进行窃漏电诊断
在线监测用户用电负荷数据,经过数据预处理,得到模型输入数据,利用构建好的识别模型计算用户窃漏电诊断结果,实现窃漏电用户的实时诊断,并与实际稽查结果对比,见表可以发现正确识别出窃漏电10个,错误的判断为窃漏电用户1个,诊断结果没有发现窃漏电用户4个,整体看准确率比较高,下一步针对漏判的用户,研究其窃漏电期间的用电行为,优化模型特征,提高识别准确率.