Hadoop-3.0.0环境搭建
硬件:两台以上不同机器,可以用虚拟机
服务器上在vmware文件夹中有vmware的安装程序,也有虚拟机的镜像文件。
需要的包在ftp上也有:jdk-8u161-linux-x64.tar.gz
hadoop-3.0.0.tar.gz
系统:Ubuntu-17.0.4
搭建步骤
1. 修改hostname: ubuntu@ubuntu:~$ sudo vim /etc/hostname
将原来的主机名其中一台配master,其他的配slave1、slave2.... 无所谓生效不生效,可以继续下一步,如果想看到改过的主机名,则输入reboot重启。
2. 修改host: ubuntu@master:~$ sudo vim /etc/hosts
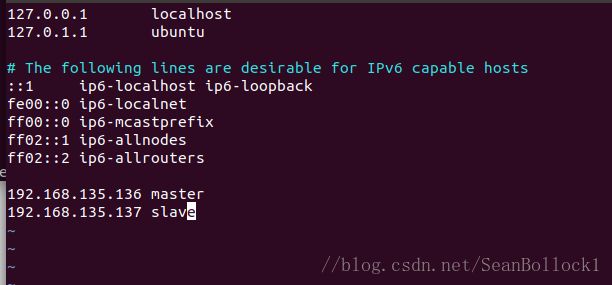
只需要添加类似最后两行的配置信息。将需要用到的slave的ip都加进去
如果是单机单节点伪分布式,只需要配置master,并且master前面的ip可以设置为127.0.0.1.
3. 安装jdk
将ftp中的jdk-8u161-linux-x64.tar.gz下载下来,使用以下指令解压并移动:
ubuntu@master:~$ sudo mkdir -p
ubuntu@master:~$ tar -zxvf ~/Desktop/jdk-8u161-linux-x64.tar.gz -C /usr/local/jvm
然后配置/etc/profile文件:ubuntu@master:~$ sudo vim /etc/profile

然后配置/.bashrc: ubuntu@master:~$ sudo vim ~/.bashrc
在最后加入 source /etc/profile,这个举动可以使每次打开命令行时都可以让profile生效
然后在命令行输入 java -version,没有报错则设置成功
4. 安装Hadoop
将ftp中的hadoop-3.0.0.tar.gz下载解压,并解压移动重命名:
ubuntu@master:~$ tar -zxvf ~/Desktop/hadoop-3.0.0.tar.gz -C /usr/local/
ubuntu@master:~$ sudo mv /usr/local/hadoop-3.0.0 /usr/local/hadoop
ubuntu@master:~$ sudo chown -R ubuntu:ubuntu /usr/local/hadoop
修改workers文件:ubuntu@master:$ sudo vim /usr/local/hadoop/etc/hadoop/workers

可能有些人会看之前的配置文档,配的是slaves文件,hadoop更新到3.0.0后,配置的是workers的文件!这个文件里指明了哪些主机可以用来作为DataNode来工作
5. 修改Hadoop配置文件
修改core-site.xml: ubuntu@master:~$vim /usr/local/hadoop/etc/hadoop/core-site.xml
fs.defaultFS
hdfs://master:9000
9000是连接master的端口,不可以修改
修改hdfs-site.xml:
dfs.replication
2
dfs.namenode.name.dir
/usr/local/hadoop/hdfs/name
dfs.datanode.data.dir
/usr/local/hadoop/hdfs/data
name.dir和data.dir用来存储datanode和namenode的hdfs文件位置,不需要提前mkdir,在后续初始化中会自动生产
修改mapred-site.xml:
mapreduce.framework.name
yarn
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.aux-services.mapreduce.shuffle.class
org.apache.hadoop.mapred.ShuffleHandler
修改yarn-site.xml
yarn.resourcemanager.hostname
master
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.nodemanager.env-whitelist
JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME
yarn.nodemanager.vmem-check-enabled
false
yarn.nodemanager.resource.memory-mb
1024
yarn.scheduler.maximum-allocation-mb
1024
需要注意,这里的yarn.nodemanager.resource.memory-mb和yarn.scheduler.maximum-allocation-mb将会直接影响节点的内存与存储空间大小,请谨慎设置。
设置hadoop-env.sh文件: ubuntu@master:~$ sudo vim /usr/local/hadoop/etc/hadoop/hadoop-env.sh

加入图中的三句话,保存。
配置一下环境变量:

注意:第3、4、5步需要在每台机器上配置一遍,保证不出错误
6. 机器之间免密ssh登陆:
如果虚拟机输入ssh报错,则需要先安装openssh-server,指令:ubuntu@master:~$ sudo apt-get install openssh-server
在每台机器上操作下列指令:
ubuntu@master:~$ cd ~/.ssh
ubuntu@master:~/.ssh$ rm ./id_rsa*
ubuntu@master:~/.ssh$ ssh-keygen -t rsa 这一步一路回车即可
为了让每个节点都有其他节点的公钥,要先把所有公钥放进一个文件之中:
a) 在master上,将master的公钥复制到authorized_keys的文件中:
ubuntu@master:~/.ssh$ cat ./id_rsa.pub >> ./authorized)keys
b) 在slave上,将自己的公钥文件发给master:
ubuntu@slave:~$ scp ~/.ssh/id_rsa.pub ubuntu@master:/home/ubuntu/
这一步需要输入master的密码
c) Master将收到的公钥提取追加到authorized_keys文件中
ubuntu@master:~$ cat ~/id_rsa.pub >> ~/.ssh/authorized_keys
重复前两步,知道所有的slave的公钥文件都发给master并被追加
最后,将master的authorized_keys发到所有slave的~/.ssh下
ubuntu@master:~$ scp ~/.ssh/authorized_keys ubuntu@slaveX:/home/ubuntu/.ssh
尝试免密登陆其他主机,如ssh slave1,ssh slave2,不需要密码则成功。如果报错sign_and_send_pubkey: signing failed: agent refused operation,则可以使用以下的指令
eval "$(ssh-agent -s)"
ssh-add
7. 启动及验证Hadoop:
a) 对hadoop进行format格式化:
ubuntu@master:~$ /usr/local/hadoop/bin/hdfs namenode -format
绝对不要多次格式化,要不然会造成DataNodes无法启动的情况,如果实在需要格式化,那么将name和data文件夹下的数据全都删除,tmp文件夹下的数据也全都删除,再进行重新格式化。
b) 启动hadoop
ubuntu@master:~$ /usr/local/hadoop/sbin/start-all.sh
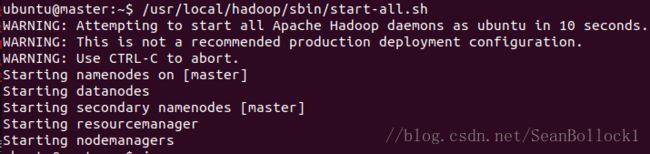
WARNING应该是没有什么需要在意的地方,直接掠过就好
在每个节点上输入jps,查看启动的服务:
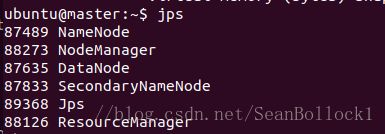
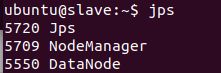
如果master有namenode和datanode,slave有datanode,那么恭喜,hadoop搭建完成。
在浏览器中打开:master://9870,可以打开hadoop管理系统
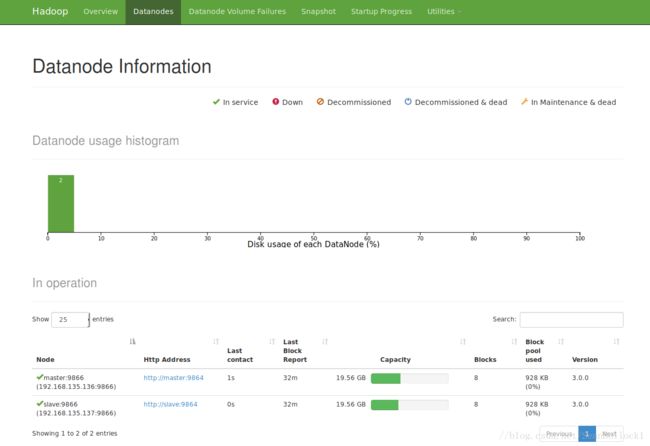
8. 使用一下hadoop
使用自带的wordcount的包,感受一下hadoop的魅力。
首先,在HDFS中创建input文件目录:
hadoop fs -mkdir /input
然后,把任意txt文件放到hdfs的input目录下面,这里用的在hadoop的目录下的LICENSE.txt
先cd到hadoop的目录下
hadoop fs -put LICENSE.txt /input
执行任务的提交:
hadoop jar /usr/local/hadoop/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.0.0.jar wordcount /input /output
这里的/output可以随便改名字,比如output1,output2,都无所谓
然后在浏览器管理系统点到Utilities -> Browse the file system 可以查看任务的输入与输出。上面的output1什么的都可以看到。