MySQL-分库分表
目录
一、shardingsphere
1、官方文档
2、入门环境搭建
2.1、引入依赖
2.2、创建数据库
2.3、sharding-jdbc分片策略配置
2.4、事务
2.5、mybatis-plus配置
3、分片策略
3.1、行表达式分片策略
3.2、标准分片策略
(1)精准分片算法
精准分库算法
精准分表算法
(2)范围分片算法
范围分库算法
范围分表算法
3.3、复合分片策略
复合分片算法
4、事务
4.1、背景
4.2、挑战
4.3、目标
4.4、原理
(1)LOCAL事务
(2)XA事务
(3)BASE事务
4.5、应用场景
(1)ShardingSphere XA
(2)ShardingSphere BASE
(3)ShardingSphere LOCAL
5、常见问题
5.1、范围分片
5.2、初始化shardingDataSource失败
5.3、取模运算失败
5.4、库定义错误
二、如何生成全局唯一ID
1、UUID
2、基于redis模式
3、雪花算法
4、基于数据库自增ID
5、数据库号段模式
一、shardingsphere
1、官方文档
概览 :: ShardingSphere
2、入门环境搭建
springboot + sharding-jdbc + druid + mybatis-plus
2.1、引入依赖
mysql
mysql-connector-java
8.0.30
com.alibaba
druid
1.2.20
org.apache.shardingsphere
sharding-jdbc-spring-boot-starter
4.1.1
org.apache.shardingsphere
sharding-transaction-xa-core
4.1.1
com.baomidou
mybatis-plus-boot-starter
3.5.4
com.baomidou
mybatis-plus-generator
3.5.4
org.freemarker
freemarker
2.3.32
注意:
如果druid使用了druid-spring-boot-starter那么在启动后会出现“Property ‘sqlSessionFactory‘ or ‘sqlSessionTemplate‘ are required”的错误,必须使用druid的依赖。
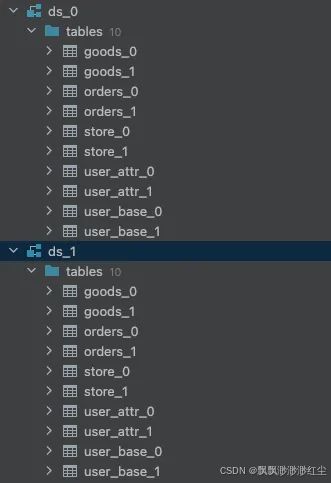
2.2、创建数据库
这里模拟分库分表的各种策略
2.3、sharding-jdbc分片策略配置
### 配置Sharding-JDBC的分片策略
# 打开sql输出日志
spring.shardingsphere.props.sql.show=true
# 配置数据源,给数据源起名 ds0,ds1... 此处可配置多数据源
spring.shardingsphere.datasource.names=ds-0,ds-1
# 数据源 配置内容
spring.shardingsphere.datasource.ds-0.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds-0.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds-0.url=${datasource.ds0.url}
spring.shardingsphere.datasource.ds-0.username=${datasource.username}
spring.shardingsphere.datasource.ds-0.password=${datasource.password}
spring.shardingsphere.datasource.ds-1.type=com.alibaba.druid.pool.DruidDataSource
spring.shardingsphere.datasource.ds-1.driver-class-name=com.mysql.cj.jdbc.Driver
spring.shardingsphere.datasource.ds-1.url=${datasource.ds1.url}
spring.shardingsphere.datasource.ds-1.username=${datasource.username}
spring.shardingsphere.datasource.ds-1.password=${datasource.password}
# 配置允许一个实体类映射多张表(mybatis ORM 映射时必须)
spring.main.allow-bean-definition-overriding=true
# 配置数据库user_base表,采用 范围分片算法
spring.shardingsphere.sharding.tables.user_base.actual-data-nodes=ds-${0..1}.user_base_${0..1}
# 分库分片键
spring.shardingsphere.sharding.tables.user_base.database-strategy.standard.sharding-column=id
# 分库分片算法(使用范围分片必须要对应一个精准分片策略)
spring.shardingsphere.sharding.tables.user_base.database-strategy.standard.precise-algorithm-class-name=com.wzw.sharding.algorithm.MyDBPreciseShardingAlgorithm
spring.shardingsphere.sharding.tables.user_base.database-strategy.standard.range-algorithm-class-name=com.wzw.sharding.algorithm.MyDBRangeShardingAlgorithm
# 分表分片键
spring.shardingsphere.sharding.tables.user_base.table-strategy.standard.sharding-column=id
# 分表分片算法(使用范围分片必须要对应一个精准分片策略)
spring.shardingsphere.sharding.tables.user_base.table-strategy.standard.precise-algorithm-class-name=com.wzw.sharding.algorithm.MyTablePreciseShardingAlgorithm
spring.shardingsphere.sharding.tables.user_base.table-strategy.standard.range-algorithm-class-name=com.wzw.sharding.algorithm.MyTableRangeShardingAlgorithm
# 配置数据库user_attr表,采用 精准分片算法
spring.shardingsphere.sharding.tables.user_attr.actual-data-nodes=ds-${0..1}.user_attr_${0..1}
# 分库分片键
spring.shardingsphere.sharding.tables.user_attr.database-strategy.standard.sharding-column=user_id
# 分库分片算法
spring.shardingsphere.sharding.tables.user_attr.database-strategy.standard.precise-algorithm-class-name=com.wzw.sharding.algorithm.MyDBPreciseShardingAlgorithm
# 分表分片键
spring.shardingsphere.sharding.tables.user_attr.table-strategy.standard.sharding-column=user_id
# 分表分片算法
spring.shardingsphere.sharding.tables.user_attr.table-strategy.standard.precise-algorithm-class-name=com.wzw.sharding.algorithm.MyTablePreciseShardingAlgorithm
# 通过雪花算法缺省主键ID
spring.shardingsphere.sharding.tables.user_attr.keyGenerator.column=id
spring.shardingsphere.sharding.tables.user_attr.keyGenerator.type=snowflake
# 配置数据库order表分布,采用 复合分片算法
spring.shardingsphere.sharding.tables.orders.actual-data-nodes=ds-${0..1}.orders_${0..1}
# 分库分片键
spring.shardingsphere.sharding.tables.orders.database-strategy.complex.sharding-columns=user_id,id
# 分库分片算法
spring.shardingsphere.sharding.tables.orders.database-strategy.complex.algorithm-class-name=com.wzw.sharding.algorithm.MyComplexKeysShardingAlgorithm
# 分表分片键
spring.shardingsphere.sharding.tables.orders.table-strategy.complex.sharding-columns=user_id,id
# 分表分片算法
spring.shardingsphere.sharding.tables.orders.table-strategy.complex.algorithm-class-name=com.wzw.sharding.algorithm.MyComplexKeysShardingAlgorithm
# 配置数据库goods表分布,采用 行表达式分片算法
spring.shardingsphere.sharding.tables.goods.actual-data-nodes=ds-$->{0..1}.goods_$->{0..1}
# 分库分片键
spring.shardingsphere.sharding.tables.goods.database-strategy.inline.sharding-column=id
# 分库分片算法
spring.shardingsphere.sharding.tables.goods.database-strategy.inline.algorithm-expression=ds-$->{id % 2}
# 通过雪花算法生成主键ID
spring.shardingsphere.sharding.tables.goods.keyGenerator.column=id
spring.shardingsphere.sharding.tables.goods.keyGenerator.type=snowflake
# 分表分片键
spring.shardingsphere.sharding.tables.goods.table-strategy.inline.sharding-column=id
# 分表分片算法 (分库和分表使用同一个分片键,分库时使用 分片值%库数量 分表时使用 分片值/库数量%库数量,可以使数据按照分片键均匀的分布在库表中)
spring.shardingsphere.sharding.tables.goods.table-strategy.inline.algorithm-expression=goods_$->{(id / 2).longValue() % 2}
# 配置数据库store表分布,采用 hint分片算法
spring.shardingsphere.sharding.tables.store.actual-data-nodes=ds-$->{0..1}.store_$->{0..1}
# 分库分片算法
spring.shardingsphere.sharding.tables.store.database-strategy.hint.algorithm-class-name=com.wzw.sharding.algorithm.HintShardingKeyAlgorithm
# 分表分片算法
spring.shardingsphere.sharding.tables.store.table-strategy.hint.algorithm-class-name=com.wzw.sharding.algorithm.HintShardingKeyAlgorithm2.4、事务
/**
* sharding事务
*/
@Configuration
@EnableTransactionManagement
public class TransactionConfiguration {
@Bean
public PlatformTransactionManager txManager(@Qualifier("shardingDataSource") DataSource dataSource) {
return new DataSourceTransactionManager(dataSource);
}
@Bean
public JdbcTemplate jdbcTemplate(@Qualifier("shardingDataSource") DataSource dataSource) {
return new JdbcTemplate(dataSource);
}
}2.5、mybatis-plus配置
启动时扫描mapper包
@Configuration
@MapperScan(basePackages = {"com.wzw.sharding.dto.mapper"})
public class MyBatisPlusConfig {
/**
* 添加分页插件
*/
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {
MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();
interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));//如果配置多个插件,切记分页最后添加
//interceptor.addInnerInterceptor(new PaginationInnerInterceptor()); 如果有多数据源可以不配具体类型 否则都建议配上具体的DbType
return interceptor;
}
}配置文件
# mybatis配置
mybatis-plus.mapper-locations=classpath:mapper/*.xml
mybatis-plus.type-aliases-package=com.wzw.sharding.dto.entity3、分片策略
3.1、行表达式分片策略
行表达式分片策略(InlineShardingStrategy),在配置中使用Groovy表达式,提供对SQL语句中的 = 和 in 的分片操作支持,它只支持单分片键。
行表达式分片策略适用于做简单的分片算法,无需自定义分片算法,省去了繁琐的代码开发,是几种分片策略中最为简单的。它的配置相当简洁,这种分片策略利用 inline.algorithm-expression 书写表达式。
语法:
数据节点:
${begin ... end},表示范围区间
${[unit1, unit2, unit_x]},表示枚举值
行表达式中如果出现连续多个 ${expression} 或 $->{expression} 表达式,整个表达式最终的结果会根据每个子表达式的结果进行笛卡尔组合,例如:
${['online', 'offline']}_table${1..3}
# 最终解析为
online_table1, online_table2, online_table3, offline_table1, offline_table2, offline_table3分片:
对于只有一个分片键的使用 = 和 in 进行分片的SQL,可以根据分片键计算的方式,返回相应的真实数据源或真实表名称。例如分为10个库,尾数为0的路由到后缀为0的数据源,尾数为1的路由到后缀为1的数据源,以此类推。其表达式为:ds${id % 10} 或者 ds$->{id % 10}
案例:使用id分片,采用取模运算
spring.shardingsphere.sharding.tables.goods.actual-data-nodes=ds-$->{0..1}.goods_$->{0..1}
# 分库分片键
spring.shardingsphere.sharding.tables.goods.database-strategy.inline.sharding-column=id
# 分库分片算法
spring.shardingsphere.sharding.tables.goods.database-strategy.inline.algorithm-expression=ds-$->{id % 2}
# 分表分片键
spring.shardingsphere.sharding.tables.goods.table-strategy.inline.sharding-column=id
# 分表分片算法 (分库和分表使用同一个分片键,分库时使用 分片值%库数量 分表时使用 分片值/库数量%库数量,可以使数据按照分片键均匀的分布在库表中)
spring.shardingsphere.sharding.tables.goods.table-strategy.inline.algorithm-expression=goods_$->{(id / 2).longValue() % 2}在使用ID取模的方式计算分片时,注意不要通过雪花算法来生成主键,雪花算法的特殊性会导致ID在{id % 2}或{(id / 2).longValue() % 2}算法后结果是一样。当然如果非要使用雪花算法那么可以采用分表的时候取倒数第二位取模的方式来处理{(id / 10).longValue() % 2},这样会比较均匀。
3.2、标准分片策略
使用场景:SQL语句中有 >, >=, <, <=, =, in, between and 操作符,都可以使用此分片策略。
标准分片策略(StandardShardingStrategy),它只支持对单个分片键(字段)为依据的分库分表,并提供了两种分片算法PreciseShardingAlgorithm(精准分片)和RangeShardingAlgorithm(范围分片)。
在使用标准分片策略时,精准分片算法是必须实现的算法,用于SQL含有 = 和 in 的分片处理;范围分片算法是非必选的,用于处理between and的分片处理。
(1)精准分片算法
精准分库算法
实现自定义精准分库,分表算法的方式大致相同,都要实现PreciseShardingAlgorithm接口,并重写doSharing()方法,只是配置稍有不同,而且它只是个空方法,得我们自行处理分库、分表逻辑。
select * from user where id=1 or id in (1,2,3);通过分片键取模的方式,计算SQL该路由到哪个库,计算出分片库信息。
/**
* 精准分库算法
*/
public class MyDBPreciseShardingAlgorithm implements PreciseShardingAlgorithm {
@Override
public String doSharding(Collection databaseNames, PreciseShardingValue preciseShardingValue) {
/**
* databaseNames 所有分片库的集合
* preciseShardingValue 为分片属性,其中 logicTableName 为逻辑表,columnName 分片健(字段),value 为从 SQL 中解析出的分片健的值
*/
for (String databaseName : databaseNames) {
String value = preciseShardingValue.getValue() % databaseNames.size() + "";
if (databaseName.endsWith(value)) {
System.out.println("精准分库算法,总库="+ JSONObject.toJSONString(databaseNames)+",分片键值="+ preciseShardingValue.getValue() +",分库结果:" + databaseName);
return databaseName;
}
}
throw new IllegalArgumentException();
}
} 精准分表算法
精准分表算法同样实现 PreciseShardingAlgorithm 接口,并重写 doSharding() 方法。
/**
* 精准分表算法
*/
public class MyTablePreciseShardingAlgorithm implements PreciseShardingAlgorithm {
@Override
public String doSharding(Collection tableNames, PreciseShardingValue preciseShardingValue) {
/**
* tableNames 对应分片库中所有分片表的集合
* shardingValue 为分片属性,其中 logicTableName 为逻辑表,columnName 分片健(字段),value 为从 SQL 中解析出的分片健的值
*/
for (String tableName : tableNames) {
// 取模算法,分片健 % 表数量
// String value = preciseShardingValue.getValue() % tableNames.size() + "";
/**
* 如果:数据库ds0,ds1,每个库内对数据表table0,table2,分片键id
* 如果分库分片算法和分表分片算法都采用取模运算,且分库和分表的数量相同,那么会导致分片键id为0的数据全部落到ds0.table0中,分片键id为1的数据全部落到ds1.table2中
* 所以这里针对分库和分表采用同一个分片键的情况,可以在分库时采用 分片值%库数量 ,在分表时采用 分片值/库数量%库数量 ,这样可以保证数据按照分片键均匀的分布在库表里
*/
String value = preciseShardingValue.getValue() / tableNames.size() % tableNames.size() + "";
if (tableName.endsWith(value)) {
System.out.println("精准分表算法,总表="+ JSONObject.toJSONString(tableNames)+",分片键值="+ preciseShardingValue.getValue() +",分表结果:" + tableName);
return tableName;
}
}
throw new IllegalArgumentException();
}
} (2)范围分片算法
使用场景:当我们SQL中的分片键字段用到 >, >=, <, <=, between and 等操作符时用到此算法,会根据SQL中给出的分片键值范围处理分库、分表逻辑。
范围分库算法
自定义范围分片算法需要实现 RangeShardingAlgorithm 接口,重写 doSharding() 方法。
/**
* 范围分库算法
*/
public class MyDBRangeShardingAlgorithm implements RangeShardingAlgorithm {
@Override
public Collection doSharding(Collection databaseNames, RangeShardingValue rangeShardingValue) {
Set result = new LinkedHashSet<>();
// between and 的起始值
long lower = rangeShardingValue.getValueRange().lowerEndpoint();
long upper = rangeShardingValue.getValueRange().upperEndpoint();
// 循环范围计算分库逻辑
for (long i = lower; i <= upper; i++) {
for (String databaseName : databaseNames) {
if (databaseName.endsWith(i % databaseNames.size() + "")) {
result.add(databaseName);
}
}
}
System.out.println("范围分库算法,总库="+ JSONObject.toJSONString(databaseNames)+",lower="+ lower +",upper="+ upper +",分库结果:" + JSONObject.toJSONString(result));
return result;
}
} 在配置上,同在标准分片策略下使用,只需要添加上 range-algorithm-class-name 自定义范围分片算法类路径即可。
范围分表算法
/**
* 范围分表算法
*/
public class MyTableRangeShardingAlgorithm implements RangeShardingAlgorithm {
@Override
public Collection doSharding(Collection tableNames, RangeShardingValue rangeShardingValue) {
Set result = new LinkedHashSet<>();
// between and 的起始值
long lower = rangeShardingValue.getValueRange().lowerEndpoint();
long upper = rangeShardingValue.getValueRange().upperEndpoint();
// 循环范围计算分库逻辑
for (long i = lower; i <= upper; i++) {
for (String tableName : tableNames) {
/**
* 分表分片算法,分片值 / 库数量 % 库数量
*/
String value = i / tableNames.size() % tableNames.size() + "";
if (tableName.endsWith(value)) {
result.add(tableName);
}
}
}
System.out.println("范围分表算法,总表="+ JSONObject.toJSONString(tableNames)+",lower="+ lower +",upper="+ upper +",分表结果:" + JSONObject.toJSONString(result));
return result;
}
} 在配置上,同在标准分片策略下使用,只需要添加上 range-algorithm-class-name 自定义范围分片算法类路径即可。
3.3、复合分片策略
使用场景:SQL语句中有 >, >=, <, <=, in, between and 等操作符,不同的是复合分片策略支持对多个分片键操作。
我们以 id、order_id 两个字段作为分片键,实现自定义复合分片策略。
select * from order_attr where id=1 and order_id=1配置里,complex.sharding-column 换成 complex.sharding-columns 复数,分片键上两个字段,分片策略名变更为 complex,complex.algorithm-class-name 替换成我们自定义的复合分片算法。
复合分片算法
复合分库算法要实现 ComplexKeysShardingAlgorithm 接口,重新 doSharding() 方法。
/**
* 复合分片算法
*/
public class MyComplexKeysShardingAlgorithm implements ComplexKeysShardingAlgorithm {
@Override
public Collection doSharding(Collection availableTargetNames, ComplexKeysShardingValue shardingValues) {
Collection userIdValues = getShardingValue(shardingValues, "user_id");
Collection orderIdValues = getShardingValue(shardingValues, "id");
Collection result = new ArrayList<>();
boolean isDbSharding = isDatabaseSharding(availableTargetNames);
for (Long userId : userIdValues) {
for (Long orderId : orderIdValues) {
String targetName = isDbSharding
? "ds-" + (userId % availableTargetNames.size())
: "orders_" + (orderId % availableTargetNames.size());
if (availableTargetNames.contains(targetName)) {
result.add(targetName);
}
}
}
System.out.println("混合分片算法,库分片="+isDbSharding+",总片="+ JSONObject.toJSONString(availableTargetNames)+",userIdValues="+JSONObject.toJSONString(userIdValues)+",orderIdValues="+JSONObject.toJSONString(orderIdValues)+",分片结果:" + JSONObject.toJSONString(result));
return result;
}
private boolean isDatabaseSharding(Collection availableTargetNames) {
// 基于可用目标名称判断是数据库分片还是表分片
// 假设数据库名称格式为 "ds-x",表名称格式为 "orders_x"
return availableTargetNames.iterator().next().startsWith("ds");
}
private Collection getShardingValue(ComplexKeysShardingValue shardingValues, String key) {
Collection valueSet = new ArrayList<>();
Map> columnNameAndShardingValuesMap = shardingValues.getColumnNameAndShardingValuesMap();
if (columnNameAndShardingValuesMap.containsKey(key)) {
valueSet.addAll(columnNameAndShardingValuesMap.get(key));
}
return valueSet;
}
} 4、事务
4.1、背景
数据库事务需要满足 ACID(原子性、一致性、隔离性、持久性)四个特性。
关系型数据库虽然对本地事务提供了完美的 ACID 原生支持。 但在分布式的场景下,它却成为系统性能的桎梏。 如何让数据库在分布式场景下满足 ACID 的特性或找寻相应的替代方案,是分布式事务的重点工作。
4.2、挑战
由于应用的场景不同,需要开发者能够合理的在性能与功能之间权衡各种分布式事务。
强一致的事务与柔性事务的 API 和功能并不完全相同,在它们之间并不能做到自由的透明切换。在开发决策阶段,就不得不在强一致的事务和柔性事务之间抉择,使得设计和开发成本被大幅增加。
基于 XA 的强一致事务使用相对简单,但是无法很好的应对互联网的高并发或复杂系统的长事务场景; 柔性事务则需要开发者对应用进行改造,接入成本非常高,并且需要开发者自行实现资源锁定和反向补偿。
4.3、目标
整合现有的成熟事务方案,为本地事务、两阶段事务和柔性事务提供统一的分布式事务接口,并弥补当前方案的不足,提供一站式的分布式事务解决方案是 Apache ShardingSphere 分布式事务模块的主要设计目标。
4.4、原理
ShardingSphere 对外提供 begin/commit/rollback 传统事务接口,通过 LOCAL,XA,BASE 三种模式提供了分布式事务的能力。
(1)LOCAL事务
LOCAL 模式基于 ShardingSphere 代理的数据库 begin/commit/rolllback 的接口实现, 对于一条逻辑 SQL,ShardingSphere 通过 begin 指令在每个被代理的数据库开启事务,并执行实际 SQL,并执行 commit/rollback。 由于每个数据节点各自管理自己的事务,它们之间没有协调以及通信的能力,也并不互相知晓其他数据节点事务的成功与否。 在性能方面无任何损耗,但在强一致性以及最终一致性方面不能够保证。
(2)XA事务
XA 事务采用的是 X/OPEN 组织所定义的 DTP 模型 所抽象的 AP(应用程序), TM(事务管理器)和 RM(资源管理器) 概念来保证分布式事务的强一致性。 其中 TM 与 RM 间采用 XA 的协议进行双向通信,通过两阶段提交实现。 与传统的本地事务相比,XA 事务增加了准备阶段,数据库除了被动接受提交指令外,还可以反向通知调用方事务是否可以被提交。 TM 可以收集所有分支事务的准备结果,并于最后进行原子提交,以保证事务的强一致性。
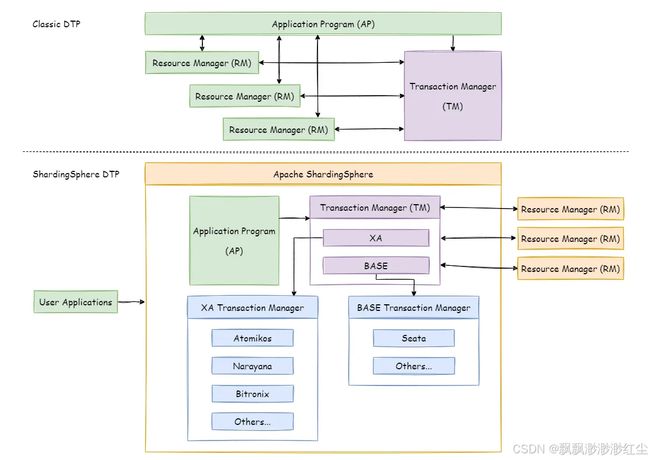
XA 事务建立在 ShardingSphere 代理的数据库 xa start/end/prepare/commit/rollback/recover 的接口上。
对于一条逻辑 SQL,ShardingSphere 通过 xa begin 指令在每个被代理的数据库开启事务,内部集成 TM,用于协调各分支事务,并执行 xa commit/rollback。
基于 XA 协议实现的分布式事务,由于在执行的过程中需要对所需资源进行锁定,它更加适用于执行时间确定的短事务。 对于长事务来说,整个事务进行期间对数据的独占,将会对并发场景下的性能产生一定的影响。
(3)BASE事务
如果将实现了 ACID 的事务要素的事务称为刚性事务的话,那么基于 BASE 事务要素的事务则称为柔性事务。 BASE 是基本可用、柔性状态和最终一致性这三个要素的缩写。
- 基本可用(Basically Available)保证分布式事务参与方不一定同时在线;
- 柔性状态(Soft state)则允许系统状态更新有一定的延时,这个延时对客户来说不一定能够察觉;
- 最终一致性(Eventually consistent)通常是通过消息传递的方式保证系统的最终一致性。
在 ACID 事务中对隔离性的要求很高,在事务执行过程中,必须将所有的资源锁定。 柔性事务的理念则是通过业务逻辑将互斥锁操作从资源层面上移至业务层面。 通过放宽对强一致性要求,来换取系统吞吐量的提升。
基于 ACID 的强一致性事务和基于 BASE 的最终一致性事务都不是银弹,只有在最适合的场景中才能发挥它们的最大长处。 Apache ShardingSphere 集成了 SEATA 作为柔性事务的使用方案。 可通过下表详细对比它们之间的区别,以帮助开发者进行技术选型。
| LOCAL |
XA |
BASE |
|
| 业务改造 |
无 |
无 |
需要 seata server |
| 一致性 |
不支持 |
支持 |
最终一致 |
| 隔离性 |
不支持 |
支持 |
业务方保证 |
| 并发性能 |
无影响 |
严重衰退 |
略微衰退 |
| 适合场景 |
业务方处理不一致 |
短事务 & 低并发 |
长事务 & 高并发 |
4.5、应用场景
在单机应用场景中,依赖数据库提供的事务即可满足业务上对事务 ACID 的需求。但是在分布式场景下,传统数据库解决方案缺乏对全局事务的管控能力,用户在使用过程中可能遇到多个数据库节点上出现数据不一致的问题。
ShardingSphere 分布式事务,为用户屏蔽了分布式事务处理的复杂性,提供了灵活多样的分布式事务解决方案,用户可以根据自己的业务场景在 LOCAL,XA,BASE 三种模式中,选择适合自己的分布式事务解决方案。
(1)ShardingSphere XA
对于 XA 事务,提供了分布式环境下,对数据强一致性的保证。但是由于存在同步阻塞问题,对性能会有一定影响。适用于对数据一致性要求非常高且对并发性能要求不是很高的业务场景。
(2)ShardingSphere BASE
对于 BASE 事务,提供了分布式环境下,对数据最终一致性的保证。由于在整个事务过程中,不会像 XA 事务那样全程锁定资源,所以性能较好。适用于对并发性能要求很高并且允许出现短暂数据不一致的业务场景。
(3)ShardingSphere LOCAL
对于 LOCAL 事务,在分布式环境下,不保证各个数据库节点之间数据的一致性和隔离性,需要业务方自行处理可能出现的不一致问题。适用于用户希望自行处理分布式环境下数据一致性问题的业务场景。
5、常见问题
5.1、范围分片
查询
public void selectPage() {
Page page = new Page(2, 5);
QueryWrapper wrapper = new QueryWrapper<>();
wrapper.gt("id", 20L);
IPage iPage = orderBaseMapper.selectPage(page, wrapper);
System.out.println("selectPage: " + JSONObject.toJSONString(iPage));
}
Run Exception:
org.mybatis.spring.MyBatisSystemException: nested exception is org.apache.ibatis.exceptions.PersistenceException:
### Error querying database. Cause: java.lang.IllegalStateException: Inline strategy cannot support this type sharding:RangeRouteValue(columnName=id, tableName=order_base, valueRange=(20..+∞))
### The error may exist in com/wzw/sharding/mapper/OrderBaseMapper.java (best guess)
### The error may involve defaultParameterMap
### The error occurred while setting parameters
### SQL: SELECT id,order_number,order_status,order_time,finish_time,ctime,utime FROM order_base WHERE id > ?
### Cause: java.lang.IllegalStateException: Inline strategy cannot support this type sharding:RangeRouteValue(columnName=id, tableName=order_base, valueRange=(20..+∞)) 删除
public void deleteByWrapper() {
QueryWrapper queryWrapper = new QueryWrapper();
queryWrapper.gt("id", 1L).eq("order_number", "AD1700483327995");
int delete = orderBaseMapper.delete(queryWrapper);
System.out.println("deleteByWrapper: " + delete);
}
Run Exception:
org.mybatis.spring.MyBatisSystemException: nested exception is org.apache.ibatis.exceptions.PersistenceException:
### Error updating database. Cause: java.lang.IllegalStateException: Inline strategy cannot support this type sharding:RangeRouteValue(columnName=id, tableName=order_base, valueRange=(1..+∞))
### The error may involve defaultParameterMap
### The error occurred while setting parameters
### SQL: DELETE FROM order_base WHERE id > ? AND order_number = ?
### Cause: java.lang.IllegalStateException: Inline strategy cannot support this type sharding:RangeRouteValue(columnName=id, tableName=order_base, valueRange=(1..+∞)) 分片策略PreciseShardingAlgorithm以及行表达式分片策略,用于处理 = 和 in 的分片,不支持对分片件的范围查询 >, <, >=, <=, between 等等。
5.2、初始化shardingDataSource失败
Caused by: org.springframework.beans.factory.BeanCreationException: Error creating bean with name 'shardingDataSource' defined in class path resource [org/apache/shardingsphere/shardingjdbc/spring/boot/SpringBootConfiguration.class]: Bean instantiation via factory method failed; nested exception is org.springframework.beans.BeanInstantiationException: Failed to instantiate [javax.sql.DataSource]: Factory method 'shardingDataSource' threw exception; nested exception is java.lang.NullPointerException
at org.springframework.beans.factory.support.ConstructorResolver.instantiate(ConstructorResolver.java:653) ~[spring-beans-5.3.30.jar:5.3.30]
at org.springframework.beans.factory.support.ConstructorResolver.instantiateUsingFactoryMethod(ConstructorResolver.java:481) ~[spring-beans-5.3.30.jar:5.3.30]
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.instantiateUsingFactoryMethod(AbstractAutowireCapableBeanFactory.java:1352) ~[spring-beans-5.3.30.jar:5.3.30]
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.createBeanInstance(AbstractAutowireCapableBeanFactory.java:1195) ~[spring-beans-5.3.30.jar:5.3.30]
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.doCreateBean(AbstractAutowireCapableBeanFactory.java:582) ~[spring-beans-5.3.30.jar:5.3.30]
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.createBean(AbstractAutowireCapableBeanFactory.java:542) ~[spring-beans-5.3.30.jar:5.3.30]
at org.springframework.beans.factory.support.AbstractBeanFactory.lambda$doGetBean$0(AbstractBeanFactory.java:335) ~[spring-beans-5.3.30.jar:5.3.30]
at org.springframework.beans.factory.support.DefaultSingletonBeanRegistry.getSingleton(DefaultSingletonBeanRegistry.java:234) ~[spring-beans-5.3.30.jar:5.3.30]
at org.springframework.beans.factory.support.AbstractBeanFactory.doGetBean(AbstractBeanFactory.java:333) ~[spring-beans-5.3.30.jar:5.3.30]
at org.springframework.beans.factory.support.AbstractBeanFactory.getBean(AbstractBeanFactory.java:208) ~[spring-beans-5.3.30.jar:5.3.30]
at org.springframework.beans.factory.config.DependencyDescriptor.resolveCandidate(DependencyDescriptor.java:276) ~[spring-beans-5.3.30.jar:5.3.30]
at org.springframework.beans.factory.support.DefaultListableBeanFactory.doResolveDependency(DefaultListableBeanFactory.java:1391) ~[spring-beans-5.3.30.jar:5.3.30]
at org.springframework.beans.factory.support.DefaultListableBeanFactory.resolveDependency(DefaultListableBeanFactory.java:1311) ~[spring-beans-5.3.30.jar:5.3.30]
at org.springframework.beans.factory.support.ConstructorResolver.resolveAutowiredArgument(ConstructorResolver.java:911) ~[spring-beans-5.3.30.jar:5.3.30]
at org.springframework.beans.factory.support.ConstructorResolver.createArgumentArray(ConstructorResolver.java:788) ~[spring-beans-5.3.30.jar:5.3.30]
... 44 common frames omitted
Caused by: org.springframework.beans.BeanInstantiationException: Failed to instantiate [javax.sql.DataSource]: Factory method 'shardingDataSource' threw exception; nested exception is java.lang.NullPointerException
at org.springframework.beans.factory.support.SimpleInstantiationStrategy.instantiate(SimpleInstantiationStrategy.java:185) ~[spring-beans-5.3.30.jar:5.3.30]
at org.springframework.beans.factory.support.ConstructorResolver.instantiate(ConstructorResolver.java:648) ~[spring-beans-5.3.30.jar:5.3.30]
... 58 common frames omitted
Caused by: java.lang.NullPointerException: null
at java.base/java.lang.Class.forName0(Native Method) ~[na:na]
at java.base/java.lang.Class.forName(Class.java:315) ~[na:na]
at org.apache.shardingsphere.core.strategy.route.ShardingAlgorithmFactory.newInstance(ShardingAlgorithmFactory.java:43) ~[sharding-core-common-4.1.1.jar:4.1.1]
at org.apache.shardingsphere.core.yaml.swapper.ShardingStrategyConfigurationYamlSwapper.swap(ShardingStrategyConfigurationYamlSwapper.java:77) ~[sharding-core-common-4.1.1.jar:4.1.1]
at org.apache.shardingsphere.core.yaml.swapper.TableRuleConfigurationYamlSwapper.swap(TableRuleConfigurationYamlSwapper.java:56) ~[sharding-core-common-4.1.1.jar:4.1.1]
at org.apache.shardingsphere.core.yaml.swapper.ShardingRuleConfigurationYamlSwapper.swap(ShardingRuleConfigurationYamlSwapper.java:81) ~[sharding-core-common-4.1.1.jar:4.1.1]
at org.apache.shardingsphere.shardingjdbc.spring.boot.SpringBootConfiguration.shardingDataSource(SpringBootConfiguration.java:103) ~[sharding-jdbc-spring-boot-starter-4.1.1.jar:4.1.1]
at org.apache.shardingsphere.shardingjdbc.spring.boot.SpringBootConfiguration$$EnhancerBySpringCGLIB$$44919138.CGLIB$shardingDataSource$1() ~[sharding-jdbc-spring-boot-starter-4.1.1.jar:4.1.1]
at org.apache.shardingsphere.shardingjdbc.spring.boot.SpringBootConfiguration$$EnhancerBySpringCGLIB$$44919138$$FastClassBySpringCGLIB$$dbd34a5a.invoke() ~[sharding-jdbc-spring-boot-starter-4.1.1.jar:4.1.1]
at org.springframework.cglib.proxy.MethodProxy.invokeSuper(MethodProxy.java:244) ~[spring-core-5.3.30.jar:5.3.30]
at org.springframework.context.annotation.ConfigurationClassEnhancer$BeanMethodInterceptor.intercept(ConfigurationClassEnhancer.java:331) ~[spring-context-5.3.30.jar:5.3.30]
at org.apache.shardingsphere.shardingjdbc.spring.boot.SpringBootConfiguration$$EnhancerBySpringCGLIB$$44919138.shardingDataSource() ~[sharding-jdbc-spring-boot-starter-4.1.1.jar:4.1.1]
at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke0(Native Method) ~[na:na]
at java.base/jdk.internal.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) ~[na:na]
at java.base/jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) ~[na:na]
at java.base/java.lang.reflect.Method.invoke(Method.java:566) ~[na:na]
at org.springframework.beans.factory.support.SimpleInstantiationStrategy.instantiate(SimpleInstantiationStrategy.java:154) ~[spring-beans-5.3.30.jar:5.3.30]
... 59 common frames omitted 配置加载的问题,根本上还是配置哪里出了问题,导致数据源初始化失败。
举例:
# 配置数据库user_base表,采用 范围分片算法
spring.shardingsphere.sharding.tables.user_base.actual-data-nodes=ds-${0..1}.user_base_${0..1}
# 分库分片键
spring.shardingsphere.sharding.tables.user_base.database-strategy.standard.sharding-column=id
# 分库分片算法
spring.shardingsphere.sharding.tables.user_base.database-strategy.standard.range-algorithm-class-name=com.wzw.sharding.algorithm.MyDBRangeShardingAlgorithm
# 分表分片键
spring.shardingsphere.sharding.tables.user_base.table-strategy.standard.sharding-column=id
# 分表分片算法
spring.shardingsphere.sharding.tables.user_base.table-strategy.standard.range-algorithm-class-name=com.wzw.sharding.algorithm.MyTableRangeShardingAlgorithm注意:在使用标准分片策略的范围分片算法时,必须有一个精准分片算法这个是必须的。
5.3、取模运算失败
org.mybatis.spring.MyBatisSystemException: nested exception is org.apache.ibatis.exceptions.PersistenceException:
### Error updating database. Cause: java.lang.UnsupportedOperationException: Cannot use mod() on this number type: java.math.BigDecimal with value: 0.5
### The error may exist in com/wzw/sharding/dto/mapper/OrderBaseMapper.java (best guess)
### The error may involve com.wzw.sharding.dto.mapper.OrderBaseMapper.insert-Inline
### The error occurred while setting parameters
### SQL: INSERT INTO order_base ( id, order_number, order_status, order_time, finish_time, ctime, utime ) VALUES ( ?, ?, ?, ?, ?, ?, ? )
### Cause: java.lang.UnsupportedOperationException: Cannot use mod() on this number type: java.math.BigDecimal with value: 0.5举例:
# 配置数据库goods表分布,采用 行表达式分片算法
spring.shardingsphere.sharding.tables.goods.actual-data-nodes=ds-$->{0..1}.goods_$->{0..1}
# 分库分片键
spring.shardingsphere.sharding.tables.goods.database-strategy.inline.sharding-column=id
# 分库分片算法
spring.shardingsphere.sharding.tables.goods.database-strategy.inline.algorithm-expression=ds-$->{id % 2}
# 通过雪花算法生成主键ID
spring.shardingsphere.sharding.tables.goods.keyGenerator.column=id
spring.shardingsphere.sharding.tables.goods.keyGenerator.type=snowflake
# 分表分片键
spring.shardingsphere.sharding.tables.goods.table-strategy.inline.sharding-column=id
# 分表分片算法 (分库和分表使用同一个分片键,分库时使用 分片值%库数量 分表时使用 分片值/库数量%库数量,可以使数据按照分片键均匀的分布在库表中)
spring.shardingsphere.sharding.tables.goods.table-strategy.inline.algorithm-expression=goods_$->{id / 2 % 2}错就错在goods_$->{id / 2 % 2},id / 2取整时行表达式算法内部会得到一个BigDecimal类型的结果,BigDecimal无法取模所以在后 %2 时报错。正确的写法应该使用函数:goods_$->{(id / 2).longValue() % 2}。
5.4、库定义错误
Caused by: org.springframework.boot.context.properties.source.InvalidConfigurationPropertyNameException: Configuration property name 'spring.shardingsphere.datasource.ds_0' is not valid
at org.springframework.boot.context.properties.source.ConfigurationPropertyName.elementsOf(ConfigurationPropertyName.java:633)
at org.springframework.boot.context.properties.source.ConfigurationPropertyName.elementsOf(ConfigurationPropertyName.java:610)
at org.springframework.boot.context.properties.source.ConfigurationPropertyName.of(ConfigurationPropertyName.java:601)
at org.springframework.boot.context.properties.source.ConfigurationPropertyName.of(ConfigurationPropertyName.java:578)
at org.springframework.boot.context.properties.bind.Binder.bind(Binder.java:223)
at org.springframework.boot.context.properties.bind.Binder.bind(Binder.java:210)
... 62 more
举例:
# 配置数据源,给数据源起名 ds0,ds1... 此处可配置多数据源
spring.shardingsphere.datasource.names=ds_0,ds_1sharding在一些高版本中不支持数据源定义中包含“_”,不使用或者改为“-”即可。
spring.shardingsphere.datasource.names=ds-0,ds-1
二、如何生成全局唯一ID
- 全局唯一:必须保证ID是全局性唯一的,基本要求
- 高性能:高可用低延时,ID生成响应要块,否则反倒会成为业务瓶颈
- 高可用:100%的可用性是骗人的,但是也要无限接近于100%的可用性
- 好接入:要秉着拿来即用的设计原则,在系统设计和实现上要尽可能的简单
- 趋势递增:最好趋势递增,这个要求就得看具体业务场景了,一般不严格要求
1、UUID
- 优点:性能非常高:本地生成,没有网络消耗。
- 缺点:
- 不易于存储:UUID太长,16字节128位,通常以36长度的字符串表示,很多场景不适用。
- 信息不安全:基于MAC地址生成UUID的算法可能会造成MAC地址泄露,这个漏洞曾被用于寻找梅丽莎病毒的制作者位置。
- ID作为主键时在特定的环境会存在一些问题,比如做DB主键的场景下,UUID就非常不适用:
- MySQL官方有明确的建议主键要尽量越短越好[4],36个字符长度的UUID不符合要求。
- 对MySQL索引不利:如果作为数据库主键,在InnoDB引擎下,UUID的无序性可能会引起数据位置频繁变动,严重影响性能。
2、基于redis模式
Redis也同样可以实现,原理就是利用redis的 incr命令实现ID的原子性自增。
127.0.0.1:6379> set seq_id 1 // 初始化自增ID为1
OK
127.0.0.1:6379> incr seq_id // 增加1,并返回递增后的数值
(integer) 2关键在于如何防止 Redis 出现问题:
- 持久化:使用 Redis 的持久化机制(如 RDB 或 AOF)来保存当前的 ID 生成状态,以便在故障恢复后恢复数据。
- 哨兵:使用 Redis Sentinel 来监控 Redis 主节点的状态,如果主节点宕机,Sentinel 可以自动故障转移至从节点,保证服务的可用性。
3、雪花算法
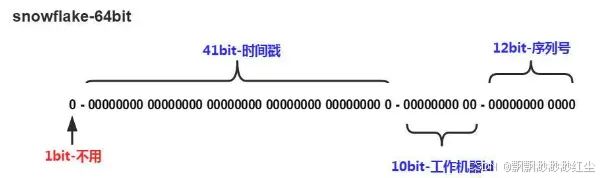
41-bit的时间可以表示(1L<<41)/(1000L*3600*24*365)=69年的时间,10-bit机器可以分别表示1024台机器。如果我们对IDC划分有需求,还可以将10-bit分5-bit给IDC,分5-bit给工作机器。这样就可以表示32个IDC,每个IDC下可以有32台机器,可以根据自身需求定义。12个自增序列号可以表示2^12个ID,理论上snowflake方案的QPS约为409.6w/s,这种分配方式可以保证在任何一个IDC的任何一台机器在任意毫秒内生成的ID都是不同的。
- 优点:
- 毫秒数在高位,自增序列在低位,整个ID都是趋势递增的。
- 不依赖数据库等第三方系统,以服务的方式部署,稳定性更高,生成ID的性能也是非常高的。
- 可以根据自身业务特性分配bit位,非常灵活。
- 缺点:
- 强依赖机器时钟,如果机器上时钟回拨,会导致发号重复或者服务会处于不可用状态。
4、基于数据库自增ID
基于数据库的auto_increment自增ID完全可以充当分布式ID,具体实现:需要一个单独的MySQL实例用来生成ID,建表结构如下:
CREATE DATABASE `SEQ_ID`;
CREATE TABLE SEQID.SEQUENCE_ID (
id bigint(20) unsigned NOT NULL auto_increment,
value char(10) NOT NULL default '',
PRIMARY KEY (id),
) ENGINE=MyISAM;insert into SEQUENCE_ID(value) VALUES ('values');当我们需要一个ID的时候,向表中插入一条记录返回主键ID,但这种方式有一个比较致命的缺点,访问量激增时MySQL本身就是系统的瓶颈,用它来实现分布式服务风险比较大,不推荐!
优点:实现简单,ID单调自增,数值类型查询速度快
缺点:DB单点存在宕机风险,无法扛住高并发场景
5、数据库号段模式
+-------------+--------------+------+-----+-------------------+-----------------------------+
| Field | Type | Null | Key | Default | Extra |
+-------------+--------------+------+-----+-------------------+-----------------------------+
| biz_tag | varchar(128) | NO | PRI | | |
| max_id | bigint(20) | NO | | 1 | |
| step | int(11) | NO | | NULL | |
| desc | varchar(256) | YES | | NULL | |
| update_time | timestamp | NO | | CURRENT_TIMESTAMP | on update CURRENT_TIMESTAMP |
+-------------+--------------+------+-----+-------------------+-----------------------------+方案4每次获取ID都得读写一次数据库,造成数据库压力大。改为利用proxy server批量获取,每次获取一个segment(step决定大小)号段的值。用完之后再去数据库获取新的号段,可以大大的减轻数据库的压力。 - 各个业务不同的发号需求用biz_tag字段来区分,每个biz-tag的ID获取相互隔离,互不影响。如果以后有性能需求需要对数据库扩容,不需要上述描述的复杂的扩容操作,只需要对biz_tag分库分表就行。
- 优点:
- 可以很方便的线性扩展,性能完全能够支撑大多数业务场景。
- ID号码是趋势递增的8byte的64位数字,满足上述数据库存储的主键要求。
- 容灾性高:内部有号段缓存,即使DB宕机,短时间仍能正常对外提供服务。
- 可以自定义max_id的大小,非常方便业务从原有的ID方式上迁移过来。
- 缺点:
- ID号码不够随机,能够泄露发号数量的信息,不太安全。
- TP999数据波动大,当号段使用完之后还是会hang在更新数据库的I/O上,tg999数据会出现偶尔的尖刺。
- DB宕机会造成整个系统不可用。