Hive 高级查询 详解(实例操作演示)CET、JOIN、MAPJOIN、UNION、CLUSTER BY、ISTRIBUTE BY 、SORT BY
Hive高级查询
- Hive查询-select基础
- Hive查询-CTE和嵌套查询
- CTE
- 嵌套查询
- Hive查询-进阶
- 列匹配正则表达式
- 虚拟列(Virtual Columns)
- Hive join - 关联查询
- 实操:
- Hive JOIN – MAPJOIN
- Hive集合操作(UNION)
- UNION在FROM子句内
- Hive数据排序 - ORDER BY
- Hive数据排序 - CLUSTER BY
Hive查询-select基础
- SELECT用于映射符合指定查询条件的行
- Hive SELECT是数据库标准SQL的子集
使用方法类似于MySQL
SELECT 1;
SELECT [DISTINCT] column_nam_list FROM table_name;
SELECT * FROM table_name;
SELECT * FROM employee WHERE name!='Lucy' LIMIT 5;
Hive查询-CTE和嵌套查询
CTE
- CTE(with as)
WITH AS短语,也叫做子查询部分(subquery factoring),可以让你做很多事情,定义一个SQL片断,该SQL片断会
被整个SQL语句所用到。有的时候,是为了让SQL语句的可读性更高些,也有可能是在UNION ALL的不同部分,作为提供数
据的部分。
特别对于UNION ALL比较有用。因为UNION ALL的每个部分可能相同,但是如果每个部分都去执行一遍的话,则成本太高,
所以可以使用WITH AS短语,则只要执行一遍即可。如果WITH AS短语所定义的表名被调用两次以上,则优化器会自动将
WITH AS短语所获取的数据放入一个TEMP表里,如果只是被调用一次,则不会。而提示materialize则是强制将WITH AS
短语里的数据放入一个全局临时表里。很多查询通过这种方法都可以提高速度。
-- CTE语法
WITH t1 AS (SELECT …) SELECT * FROM t1
with
a1 as(select className,sum(score) countScore from score group by className),
a2 as(select u.*,s.className,s.score from userinfos u inner join score s on u.userid=s.userid)
select a2.username,a2.className,a2.score,(a2.score/a1.countScore*100) from a1 inner join a2 on a1.className=a2.className
嵌套查询
- 嵌套查询
(1) 指在一个外层查询中包含有另一个内层查询。其中外层查询称为主查询,内层查询称为子查询。
(2) SQL允许多层嵌套,由内而外地进行分析,子查询的结果作为主查询的查询条件
(3)子查询中一般不使用order by子句,只能对最终查询结果进行排序
-- 嵌套查询示例
SELECT * FROM (SELECT * FROM employee) a;
select r.username,r.className,r.score,(r.score/l.countScore*100) zb
from (select className,sum(score) countScore from score group by className) l
inner join (select u.*,s.className,s.score from userinfos u
inner join score s on u.userid=s.userid) r on l.className = r.className;
Hive查询-进阶
列匹配正则表达式
SET hive.support.quoted.identifiers = none;
SELECT `^o.*` FROM offers;
SELECT `a.*` FROM userinfos;--单查年龄这一属性
虚拟列(Virtual Columns)
两个连续下划线,用于数据验证
INPUT__FILE__NAME:Mapper Task的输入文件名称
BLOCK__OFFSET__INSIDE__FILE:当前全局文件位置
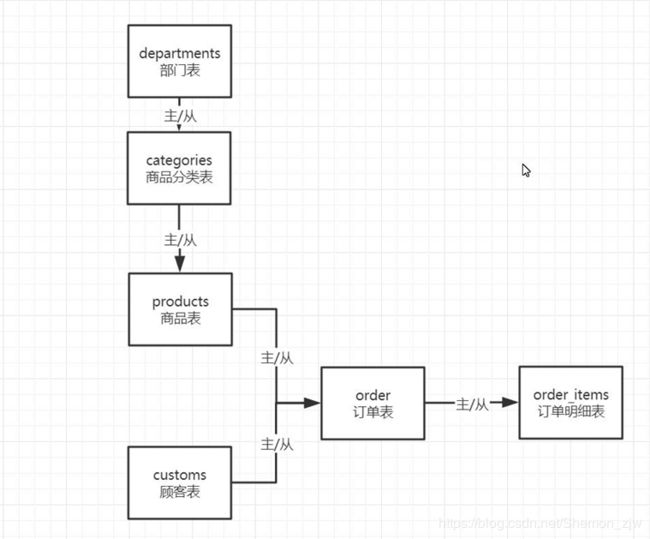
Hive join - 关联查询
Hive——join的使用
常见的join有:
- 内连接:INNER JOIN
- 外连接:OUTER JOIN
RIGHT JOIN, LEFT JOIN, FULL OUTER JOIN - 交叉连接:CROSS JOIN
- 隐式连接:Implicit JOIN
实操:
数据表格包以及建表文档:
链接:https://pan.baidu.com/s/14eiNjfvgAVX-ndUh6-CEkw 提取码:u62m
数据表格

建表语句
CREATE EXTERNAL TABLE IF NOT EXISTS customers (
customer_id int,
customer_fname varchar(45),
customer_lname varchar(45),
customer_email varchar(45),
customer_password varchar(45),
customer_street varchar(255),
customer_city varchar(45),
customer_state varchar(45),
customer_zipcode varchar(45)
)
ROW FORMAT serde 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
with serdeproperties ("separatorChar"=",")
LOCATION '/data/retail_db/customers';
CREATE EXTERNAL TABLE IF NOT EXISTS categories (
category_id int,
category_department_id int,
category_name varchar(45)
)
ROW FORMAT serde 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
with serdeproperties ("separatorChar"=",")
LOCATION '/data/retail_db/categories';
CREATE EXTERNAL TABLE IF NOT EXISTS departments (
department_id int,
department_name varchar(45)
)
ROW FORMAT serde 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
with serdeproperties ("separatorChar"=",")
LOCATION '/data/retail_db/departments';
CREATE EXTERNAL TABLE IF NOT EXISTS order_items (
order_item_id int,
order_item_order_id int,
order_item_product_id int,
order_item_quantity int,
order_item_subtotal float,
order_item_product_price float)
ROW FORMAT serde 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
with serdeproperties ("separatorChar"=",")
LOCATION '/data/retail_db/order_items';
CREATE EXTERNAL TABLE IF NOT EXISTS orders (
order_id int,
order_date date,
order_customer_id int,
order_status varchar(45)
)
ROW FORMAT serde 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
with serdeproperties ("separatorChar"=",")
LOCATION '/data/retail_db/orders';
CREATE EXTERNAL TABLE IF NOT EXISTS products (
product_id int,
product_category_id int,
product_name varchar(45),
product_description varchar(255),
product_price float,
product_image varchar(255))
ROW FORMAT serde 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
with serdeproperties ("separatorChar"=",")
LOCATION '/data/retail_db/products';
将顾客表、部门表、商品表数据存入Hive
[root@zjw opt]# hdfs dfs -mkdir /data
[root@zjw opt]# hdfs dfs -mkdir -p /data/retail_db/customers
[root@zjw opt]# hdfs dfs -mkdir -p /data/retail_db/categories
[root@zjw opt]# hdfs dfs -mkdir -p /data/retail_db/departments
[root@zjw opt]# hdfs dfs -mkdir -p /data/retail_db/order_items
[root@zjw opt]# hdfs dfs -mkdir -p /data/retail_db/orders
[root@zjw opt]# hdfs dfs -mkdir -p /data/retail_db/products
[root@zjw opt]# hdfs dfs -put /opt/retail_db-csv/customers.csv /data/retail_db/customers
[root@zjw opt]# hdfs dfs -put /opt/retail_db-csv/categories.csv /data/retail_db/categories
[root@zjw opt]# hdfs dfs -put /opt/retail_db-csv/departments.csv /data/retail_db/departments
[root@zjw opt]# hdfs dfs -put /opt/retail_db-csv/order_items.csv /data/retail_db/order_items
[root@zjw opt]# hdfs dfs -put /opt/retail_db-csv/orders.csv /data/retail_db/orders
[root@zjw opt]# hdfs dfs -put /opt/retail_db-csv/products.csv /data/retail_db/products
然后建表塞数据:
hive> create database myexp;
OK
Time taken: 4.162 seconds
hive> use myexp;
OK
Time taken: 0.025 seconds
hive> CREATE EXTERNAL TABLE IF NOT EXISTS customers (
> customer_id int,
> customer_fname varchar(45),
> customer_lname varchar(45),
> customer_email varchar(45),
> customer_password varchar(45),
> customer_street varchar(255),
> customer_city varchar(45),
> customer_state varchar(45),
> customer_zipcode varchar(45)
> )
> ROW FORMAT serde 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
> with serdeproperties ("separatorChar"=",")
> LOCATION '/data/retail_db/customers';
OK
Time taken: 0.177 seconds
hive> CREATE EXTERNAL TABLE IF NOT EXISTS categories (
> category_id int,
> category_department_id int,
> category_name varchar(45)
> )
> ROW FORMAT serde 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
> with serdeproperties ("separatorChar"=",")
> LOCATION '/data/retail_db/categories';
OK
Time taken: 0.053 seconds
hive> CREATE EXTERNAL TABLE IF NOT EXISTS departments (
> department_id int,
> department_name varchar(45)
> )
> ROW FORMAT serde 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
> with serdeproperties ("separatorChar"=",")
> LOCATION '/data/retail_db/departments';
OK
Time taken: 0.059 seconds
hive>
> CREATE EXTERNAL TABLE IF NOT EXISTS order_items (
> order_item_id int,
> order_item_order_id int,
> order_item_product_id int,
> order_item_quantity int,
> order_item_subtotal float,
> order_item_product_price float)
> ROW FORMAT serde 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
> with serdeproperties ("separatorChar"=",")
> LOCATION '/data/retail_db/order_items';
OK
Time taken: 0.041 seconds
hive>
> CREATE EXTERNAL TABLE IF NOT EXISTS orders (
> order_id int,
> order_date date,
> order_customer_id int,
> order_status varchar(45)
> )
> ROW FORMAT serde 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
> with serdeproperties ("separatorChar"=",")
> LOCATION '/data/retail_db/orders';
OK
Time taken: 0.055 seconds
hive> CREATE EXTERNAL TABLE IF NOT EXISTS products (
> product_id int,
> product_category_id int,
> product_name varchar(45),
> product_description varchar(255),
> product_price float,
> product_image varchar(255))
> ROW FORMAT serde 'org.apache.hadoop.hive.serde2.OpenCSVSerde'
> with serdeproperties ("separatorChar"=",")
> LOCATION '/data/retail_db/products';
OK
Time taken: 0.082 seconds
1、查询顾客表中地区为“NY”所在城市为’New York’的用户
hive> select * from customers where customer_state='NY' and customer_city='New York';

2、查询订单表中共有多少不同顾客下过订单
多种写法
方法1:
select b.order_customer_id,concat(a.customer_fname,'-',a.customer_lname)
from ----字符拼接函数concat(str1,str2,...)
customers a
inner join
(select order_customer_id from orders group by order_customer_id) b
on
a.customer_id=b.order_customer_id;
方法2:(with as)
with
t1 as (select order_customer_id from orders group by order_customer_id)
select c.customer_id,concat(c.customer_fname,'.',c.customer_lname) as name
from t1 t inner join customers c on t.order_customer_id= c.customer_id;
方法3:
select c.customer_id,concat(c.customer_fname,'.',c.customer_lname) as name
from (select order_customer_id from orders group by order_customer_id) t
inner join customers c on t.order_customer_id= c.customer_id;
方法4:
select c.customer_id,concat(c.customer_fname,'.',c.customer_lname) as name
from customers c where c.customer_id in
(select order_customer_id from orders group by order_customer_id);
方法5:(exits)
select c.customer_id,concat(c.customer_fname,'.',c.customer_lname) as name
from customers c where exists
(select order_customer_id from orders s where s.order_customer_id=c.customer_id);
方法6:
with
t1 as (select distinct order_customer_id from orders)
select c.customer_id,concat(c.customer_fname,'.',c.customer_lname) as name
from t1 t inner join customers c on t.order_customer_id= c.customer_id;

3、查询商品表中前5个商品
select * from products limit 5;

4、使用关联查询获取没有订单的所有顾客
select c.customer_id,concat(c.customer_fname,'.',c.customer_lname) as name
from customers c where not exists
(select order_customer_id from orders s where s.order_customer_id=c.customer_id );

Hive JOIN – MAPJOIN
MapJoin是Hive的一种优化操作,其适用于小表JOIN大表的场景,由于表的JOIN操作是在Map端且在内存进行的,所以其并不需要启动Reduce任务也就不需要经过shuffle阶段,从而能在一定程度上节省资源提高JOIN效率
- MapJoin操作在Map端完成
(1).小表关联大表
(2).可进行不等值连接 - 开启join操作
(1).set hive.auto.convert.join = true(默认值)
(2).运行时自动将连接转换为MAPJOIN - MAPJOIN操作不支持:
(1). 在UNION ALL, LATERAL VIEW, GROUP BY/JOIN/SORT BY/CLUSTER BY/DISTRIBUTE BY等操作后面
(2). 在UNION, JOIN 以及其他 MAPJOIN之前

方法一:
在Hive0.11前,必须使用MAPJOIN来标记显示地启动该优化操作,由于其需要将小表加载进内存所以要注意小表的大小
SELECT /*+ MAPJOIN(smalltable)*/ .key,value
FROM smalltable JOIN bigtable ON smalltable.key = bigtable.key
方法二:
在Hive0.11后,Hive默认启动该优化,也就是不在需要显示的使用MAPJOIN标记,其会在必要的时候触发该优化操作将普通JOIN转换成MapJoin,可以通过以下两个属性来设置该优化的触发时机
hive.auto.convert.join
默认值为true,自动开户MAPJOIN优化
hive.mapjoin.smalltable.filesize
默认值为2500000(25M),通过配置该属性来确定使用该优化的表的大小,如果表的大小小于此值就会被加载进内存中
注意:使用默认启动该优化的方式如果出现默名奇妙的BUG(比如MAPJOIN并不起作用),就将以下两个属性置为fase手动使用MAPJOIN标记来启动该优化
select /*+MAPJOIN(smallTableTwo)*/ idOne, idTwo, value FROM
( select /*+MAPJOIN(smallTableOne)*/ idOne, idTwo, value FROM
bigTable JOIN smallTableOne on (bigTable.idOne = smallTableOne.idOne)
) firstjoin
JOIN
smallTableTwo ON (firstjoin.idTwo = smallTableTwo.idTwo)
但是,如果使用的是方法一即没有MAPJOIN标记则以上查询语句将会被作为两个MJ执行,进一步的,如果预先知道表大小是能够被加载进内存的,则可以通过以下属性来将两个MJ合并成一个MJ
hive.auto.convert.join.noconditionaltask:Hive在基于输入文件大小的前提下将普通JOIN转换成MapJoin,并是否将多个MJ合并成一个
hive.auto.convert.join.noconditionaltask.size:多个MJ合并成一个MJ时,其表的总的大小须小于该值,同时hive.auto.convert.join.noconditionaltask必须为true
关于map join的一点小坑
map join虽然很好,但是会有如下问题:
1)map join关联多个小表时,都放入内存,则考虑内存大小需要针对上述小表大小进行累加
2)大表B表map join关联分区小表A表(200M)时,即使限制了A的分区(取10M),但依旧放入内存的大小依旧是A表的原先大小(200M)
Hive集合操作(UNION)
- 所有子集数据必须具有相同的名称和类型
(1)UNION ALL:合并后保留重复项
(2)UNION:合并后删除重复项(v1.2之后) - 可以在顶层查询中使用(0.13.0之后)
- ORDER BY, SORT BY, CLUSTER BY, DISTRIBUTE BY 和LIMIT适用于合并后的整个结果
- 集合其他操作可以使用JOIN/OUTER JOIN来实现
差集、交集
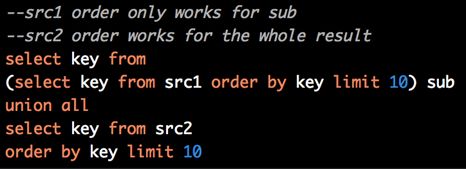
例如
//MINUS
SELECT a.name
FROM employee a
LEFT JOIN employee_hr b
ON a.name = b.name
WHERE b.name IS NULL;
//INTERCEPT
SELECT a.name
FROM employee a
JOIN employee_hr b
ON a.name = b.name;
UNION在FROM子句内
如果还需要对UNION的结果集进行一些其他的处理,整个语句表达式可以嵌入到FROM子句中,如下所示:
SELECT *
FROM (
select_statement
UNION ALL
select_statement
) unionResultAlias
例如,假设我们有两个不同的表分别表示哪个用户发布了一个视频,以及哪个用户发布了一个评论,那么下面的查询将UNION ALL的结果与用户表join在一起,为所有视频发布和评论发布创建一个注释流:
SELECT u.id, actions.date
FROM (
SELECT av.uid AS uid
FROM action_video av
WHERE av.date = '2008-06-03'
UNION ALL
SELECT ac.uid AS uid
FROM action_comment ac
WHERE ac.date = '2008-06-03'
) actions JOIN users u ON (u.id = actions.uid)
Hive数据排序 - ORDER BY
- ORDER BY (ASC|DESC)类似于标准SQL
- 只使用一个Reducer执行全局数据排序
- 速度慢,应提前做好数据过滤
- 支持使用CASE WHEN或表达式
- 支持按位置编号排序
set hive.groupby.orderby.position.alias=true;
select * from offers order by case when offerid = 1 then 1 else 0 end;
select * from offers order by 1;
举例使用:
创表:
create table myniltab(mntid int, nmtname string);
insert into myniltab(mntid,nmtname) values(1,'hehe'),(2,'xixi');
insert into myniltab(mntid) values(3),(4);
insert into myniltab(mntid,nmtname) values(5,'chacha');
select * from myniltab order by nmtname desc;

select * from myniltab order by case when nmtname is null then 1 else 0 end;
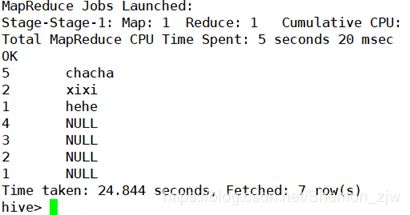
开启两个reduce
set mapred.reduce.tasks=2;
![]()
如图已经开启了两个reduce task

distribute by:
select * from myniltab distribute by mntid sort by nmtname;
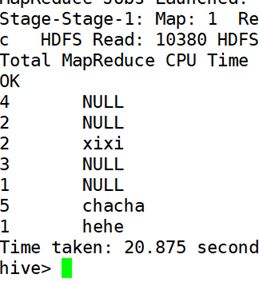
保证局部排序有序 但是不保证全局有序
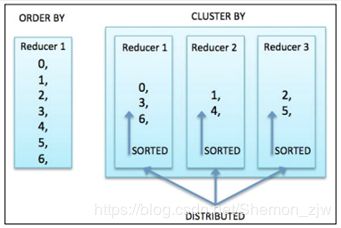
Hive数据排序 - CLUSTER BY
- CLUSTER BY = DISTRIBUTE BY + SORT BY
- 不支持ASC|DESC
- 排序列必须出现在SELECT column列表中
- 为了充分利用所有的Reducer来执行全局排序,可以先使用CLUSTER BY,然后使用ORDER BY
用法:
SELECT name, employee_id FROM employee_hr CLUSTER BY name;