使用cdh的hbase-indexer工具的两个问题
在使用hbase实现点查询业务中,经常要用到二级索引的方式,而 hbase over solr 是一种比较灵活,性能较高的方案。
cdh平台提供了hbase-indexer工具可以实现将hbase的数据同步到solr中的方式,下面说一下实际使用的过程中遇到的两个问题。
问题一
之前在设置类型之后需要使用hbase-indexer的官方类型int将hbase中的byte转换成solr中的整数型时,遇到报错:
Exception in thread "main" java.lang.IllegalArgumentException: offset (0) + length (4) exceed the capacity of the array: 2
at org.apache.hadoop.hbase.util.Bytes.explainWrongLengthOrOffset(Bytes.java:629)
at org.apache.hadoop.hbase.util.Bytes.toInt(Bytes.java:799)
at org.apache.hadoop.hbase.util.Bytes.toInt(Bytes.java:775)
at transform.BytesTransform.main(BytesTransform.java:11)
发生这个错误的原因,我举个例子:
比如你要将 29 这个int型数字放入到hbase的一个cell value中,可能在处理时有两种方式:
byte[] intBytes = Bytes.toInt(29)
byte[] stringBytes = Bytes.toInt("29")
在java的基本类型中, 29 是4个字节,而 "29" 其实是两个 char 类型,也就是 2个字节。
由此可得知
intBytes的长度为4,stringBytes长度为2
hbase-indexer在将hbase中的byte[] 转换为具体类型时,其实用的都是 org.apache.hadoop.hbase.util.Bytes 这个hbase的工具类,展示部分源码:
package com.ngdata.hbaseindexer.parse;
import java.math.BigDecimal;
import java.util.Collection;
import com.google.common.collect.ImmutableList;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.hadoop.hbase.util.Bytes;
/**
* Contains factory methods for {@link ByteArrayValueMapper}s.
*/
public class ByteArrayValueMappers {
private static Log log = LogFactory.getLog(ByteArrayValueMappers.class);
private static final ByteArrayValueMapper INT_MAPPER = new AbstractByteValueMapper(int.class) {
@Override
protected Object mapInternal(byte[] input) {
return Bytes.toInt(input);
}
};
private static final ByteArrayValueMapper LONG_MAPPER = new AbstractByteValueMapper(long.class) {
@Override
protected Object mapInternal(byte[] input) {
return Bytes.toLong(input);
}
};
private static final ByteArrayValueMapper STRING_MAPPER = new AbstractByteValueMapper(String.class) {
@Override
protected Object mapInternal(byte[] input) {
return Bytes.toString(input);
}
};
。。。。。。。
public static ByteArrayValueMapper getMapper(String mapperType) {
if ("int".equals(mapperType)) {
return INT_MAPPER;
} else if ("long".equals(mapperType)) {
return LONG_MAPPER;
} else if ("string".equals(mapperType)) {
return STRING_MAPPER;
} else if ("boolean".equals(mapperType)) {
return BOOLEAN_MAPPER;
} else if ("float".equals(mapperType)) {
return FLOAT_MAPPER;
} else if ("double".equals(mapperType)) {
return DOUBLE_MAPPER;
} else if ("short".equals(mapperType)) {
return SHORT_MAPPER;
} else if ("bigdecimal".equals(mapperType)) {
return BIG_DECIMAL_MAPPER;
} else {
return instantiateCustomMapper(mapperType);
}
}
private static ByteArrayValueMapper instantiateCustomMapper(String className) {
Object obj;
try {
obj = Class.forName(className).newInstance();
} catch (Throwable e) {
throw new IllegalArgumentException("Can't instantiate custom mapper class '" + className + "'", e);
}
if (obj instanceof ByteArrayValueMapper) {
return (ByteArrayValueMapper)obj;
} else {
throw new IllegalArgumentException(obj.getClass() + " does not implement "
+ ByteArrayValueMapper.class.getName());
}
}
}
我们可以看一下 hbase的 Bytes.toInt(byte[] bytes) 这个方法做了啥,实际是调用了下面这个方法,offset为0,length为4.
public static int toInt(byte[] bytes, int offset, final int length) {
if (length != SIZEOF_INT || offset + length > bytes.length) {
throw explainWrongLengthOrOffset(bytes, offset, length, SIZEOF_INT);
}
if (UNSAFE_UNALIGNED) {
return toIntUnsafe(bytes, offset);
} else {
int n = 0;
for(int i = offset; i < (offset + length); i++) {
n <<= 8;
n ^= bytes[i] & 0xFF;
}
return n;
}
}看一下 explainWrongLengthOrOffset 这个方法抛出的错误。
private static IllegalArgumentException
explainWrongLengthOrOffset(final byte[] bytes,
final int offset,
final int length,
final int expectedLength) {
String reason;
if (length != expectedLength) {
reason = "Wrong length: " + length + ", expected " + expectedLength;
} else {
reason = "offset (" + offset + ") + length (" + length + ") exceed the"
+ " capacity of the array: " + bytes.length;
}
return new IllegalArgumentException(reason);
}也就是说假如你的byte[]是由一个int类型的数字转换成的,那么肯定是4个字节,就是正确的,否则就是错误的,就算没有抛出异常,转换成的int值也是错误的。
那么第一个问题发生的原因就知道了,为了解决这个问题,我们需要自定义类型转换类,这个类需要实现ByteArrayValueMapper接口。贴出一个转换Int类型的示例:
package customization.hyren.type;
import com.google.common.collect.ImmutableList;
import com.ngdata.hbaseindexer.parse.ByteArrayValueMapper;
import org.apache.commons.logging.Log;
import org.apache.commons.logging.LogFactory;
import org.apache.hadoop.hbase.util.Bytes;
import java.util.Collection;
public class Hint implements ByteArrayValueMapper {
private static Log log = LogFactory.getLog(Hint.class);
/**
* Map a byte array to a collection of values. The returned collection can be empty.
*
* If a value cannot be mapped as requested, it should log the error and return an empty collection.
*
* @param input byte array to be mapped
* @return mapped values
*/
@Override
public Collection map(byte[] input) {
try {
return ImmutableList.of(mapInternal(Bytes.toString(input)));
} catch (IllegalArgumentException e) {
log.warn(
String.format("Error mapping byte value %s to %s", Bytes.toStringBinary(input),
int.class.getName()), e);
return ImmutableList.of();
}
}
private int mapInternal(String toString) {
return Integer.parseInt(toString);
}
}
byte[]数组先转换成String类型,再用Integer.parseInt方法转换成Int类型。这样问题就解决了。
问题二
在实际使用中,这种hbase的数据同步是将hbase的rowkey写入到solr的uniqueKey中的,默认是id。假如你solr的uniqueKey不是默认的id,那么hbase-indexer的配置文件中也可以用 unique-key-field 来配置。
但是这样肯定是有问题的,因为在solr中的uniqueKey如果一样就会覆盖,就是如果你的两张hbase表存在同样的rowkey,就会出现数据丢失的情况。为了解决这一情况,可以用${table_name}@${rowkey}来作为solr中的uniqueKey。
但是cdh只说了有个参数叫unique-key-formatter,并没有详述这个formatter该如何去实现上述功能。
但是存在这样一个接口 UniqueTableKeyFormatter
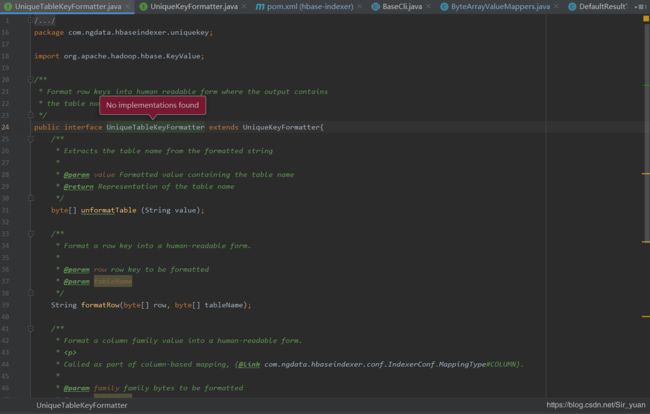
这个接口是没有任何实现的,但是很明显的,虽然没有实现,但是在编码时,可以去实现这个方法,因为调用该接口的方法去指定documentId时传入了 tablename
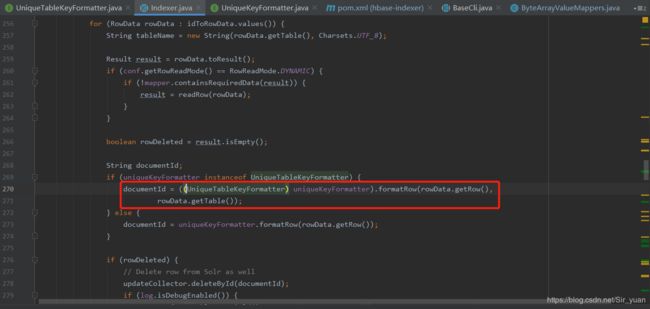
看到这儿就很简单了,只需要去实现这个接口,并且用unique-key-formatter去指定这个类,就可以达到我们想要的效果啦!
下面贴出示例:
package customization.hyren.formatter;
import com.google.common.base.Joiner;
import com.google.common.base.Preconditions;
import com.google.common.base.Splitter;
import com.google.common.collect.Lists;
import com.ngdata.hbaseindexer.conf.IndexerConf;
import com.ngdata.hbaseindexer.uniquekey.BaseUniqueKeyFormatter;
import com.ngdata.hbaseindexer.uniquekey.UniqueTableKeyFormatter;
import org.apache.hadoop.hbase.KeyValue;
import org.apache.hadoop.hbase.util.Bytes;
import java.util.List;
/**
* customize value in solr uniquekey like ${table name} + ${ rowkey }
*/
public class UniqueTableKeyFormatterImpl implements UniqueTableKeyFormatter {
private static final HyphenEscapingUniqueKeyFormatter hyphenEscapingFormatter = new HyphenEscapingUniqueKeyFormatter();
private static final Splitter SPLITTER = Splitter.onPattern("(?
* Called as part of column-based mapping, {@link IndexerConf.MappingType#COLUMN}.
*
* @param family family bytes to be formatted
* @param tableName
*/
@Override
public String formatFamily(byte[] family, byte[] tableName) {
Preconditions.checkNotNull(family, "family");
return encodeAsString(family);
}
/**
* Format a {@code KeyValue} into a human-readable form. Only the row, column family, and qualifier
* of the {@code KeyValue} will be encoded.
*
* Called in case of column-based mapping, {@link IndexerConf.MappingType#COLUMN}.
*
* @param keyValue value to be formatted
* @param tableName
*/
@Override
public String formatKeyValue(KeyValue keyValue, byte[] tableName) {
return hyphenEscapingFormatter.formatKeyValue(keyValue);
}
/**
* Format a row key into a human-readable form.
*
* @param row row key to be formatted
*/
@Override
public String formatRow(byte[] row) {
Preconditions.checkNotNull(row, "row");
return encodeAsString(row);
}
/**
* Format a column family value into a human-readable form.
*
* Called as part of column-based mapping, {@link IndexerConf.MappingType#COLUMN}.
*
* @param family family bytes to be formatted
*/
@Override
public String formatFamily(byte[] family) {
Preconditions.checkNotNull(family, "family");
return encodeAsString(family);
}
/**
* Format a {@code KeyValue} into a human-readable form. Only the row, column family, and qualifier
* of the {@code KeyValue} will be encoded.
*
* Called in case of column-based mapping, {@link IndexerConf.MappingType#COLUMN}.
*
* @param keyValue value to be formatted
*/
@Override
public String formatKeyValue(KeyValue keyValue) {
return JOINER.join(encodeAsString(keyValue.getRow()), encodeAsString(keyValue.getFamily()),
encodeAsString(keyValue.getQualifier()));
}
/**
* Perform the reverse formatting of a row key.
*
* @param keyString the formatted row key
* @return the unformatted row key
*/
@Override
public byte[] unformatRow(String keyString) {
return decodeFromString(keyString);
}
/**
* Perform the reverse formatting of a column family value.
*
* @param familyString the formatted column family string
* @return the unformatted column family value
*/
@Override
public byte[] unformatFamily(String familyString) {
return decodeFromString(familyString);
}
/**
* Perform the reverse formatting of a {@code KeyValue}.
*
* The returned KeyValue will only have the row key, column family, and column qualifier filled in.
*
* @param keyValueString the formatted {@code KeyValue}
* @return the unformatted {@code KeyValue}
*/
@Override
public KeyValue unformatKeyValue(String keyValueString) {
List parts = Lists.newArrayList(SPLITTER.split(keyValueString));
if (parts.size() != 3) {
throw new IllegalArgumentException("Value cannot be split into row, column family, qualifier: "
+ keyValueString);
}
byte[] rowKey = decodeFromString(parts.get(0));
byte[] columnFamily = decodeFromString(parts.get(1));
byte[] columnQualifier = decodeFromString(parts.get(2));
return new KeyValue(rowKey, columnFamily, columnQualifier);
}
private static class HyphenEscapingUniqueKeyFormatter extends BaseUniqueKeyFormatter {
@Override
protected String encodeAsString(byte[] bytes) {
String encoded = Bytes.toString(bytes);
if (encoded.indexOf('-') > -1) {
encoded = encoded.replace("-", "\\-");
}
return encoded;
}
@Override
protected byte[] decodeFromString(String value) {
if (value.contains("\\-")) {
value = value.replace("\\-", "-");
}
return Bytes.toBytes(value);
}
}
private String encodeAsString(byte[] bytes) {
return Bytes.toString(bytes);
}
private byte[] decodeFromString(String value) {
return Bytes.toBytes(value);
}
}
这个实现是根据默认的 StringUniqueKeyFormatter 实现去改了一小部分东西。
把你实现的类去打成jar包,放到 hbase-indexer-mr-*-job.jar 里面,还有 ${hbase-solr}/lib/目录下,就可以做Batch Indexing了。
配置文件大概这么写:
注意:上面用到的 F- 开头,FI- 开头是solr的 dynamic field 的类型设置。不同类型的是不一样的。需要在solr的schema.xml中设置的,这里就不讲了。
然后执行命令大概这么写:
yarn \
//yarn-site.xml和mapred-site.xml配置文件所在位置
--config /etc/hive/conf \
jar /home/hyshf/mick/lib/hbase-indexer-mr-job.jar \
--conf /etc/hbase/conf/hbase-site.xml \
--zk-host hdp001:2181,hdp002:2181,hdp003:2181/solr \
-hbase-indexer-file /home/hyshf/mick/mick-solr-conf.xml \
--collection HbaseOverSolr \
--go-live \
--reducers 0上面的具体示例可查看 https://github.com/mickyuan/hbaseindexer.git