利用Python Pandas进行数据预处理-Pandas基本的数据结构
概述
Pandas是Python的一个数据分析包,Pandas最初被作为金融数据分析工具而开发出来,因此,Pandas为时间序列提供了很好的支持。
Pandas是基于Numpy构建的含有更高级数据结构和工具的数据分析包。
Pandas的数据结构:
- Series:一维数组,与Numpy中的一位Array类似。二者与Python基本的数据结构List也很相近,区别是List可以放不同的数据类型,而Array和Series只能放相同的数据类型。
- Time-Series:以时间为索引的Series。
- DataFrame:二维表格型的数据结构。可以将DataFrame理解为Series的容器。
- Panel:三维数组,可以理解为DataFrame的容器。Panel很少使用,但确是很重要的三维数组。
- Panel4D:Panel4D是像Panel一样的4维容器,作为N维容器的一个测试。
- PanelND:PanelND是一个拥有factory集合,可以创建像Panel4D一样N维命名容器的模块。
Series
from pandas import Series,DataFrame
s=Series([1,2,3.0,'abc',"def"])
print(s)
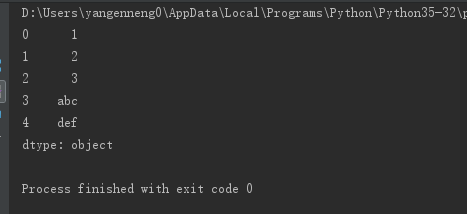
Series是一个类似一维的数组对象,包含一个数组的数据(任何Numpy类型)和一个与数组关联的数据标签,被叫做索引。
Series对象主要有两个属性:index和values,如果传给构造器的是一个列表,则index的值是从0递增的整数,如果传递的是一个类字典的键值对结构,就会生成index-value对应的Series。比如:
from pandas import Series,DataFrame
s=Series(data=[1,2,3.0,'abc',"def"],index=[100,200,300,400,500])
print(s.index)
print(s.values)

from pandas import Series,DataFrame
s=Series(data=[1,2,3.0,'abc',"def"],index=[100,200,300,400,500])
print(s.index)
print(s.values)
print("....................")
s.name='a_series'
s.index.name='the_index'
print(s)
DataFrame
一个DataFrame类似一个表格,类似电子表格的数据结构,包含一个经过排序的列表集,他们每一个都可以有不同的类型值(数字、字符串、布尔),DataFrame有行和列的索引;他可以看作一个Series的字典。
from pandas import Series,DataFrame
data={'state':['a','b','c','d','e'], 'year':[2000,2001,2002,2001,2002],'pop':[1.5,1.7,3.6,2.4,2.9]}
frame=DataFrame(data)
print(frame)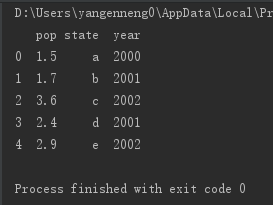
和Series一样,他的索引也是自动分配,并且对列进行了排序
也可以给列一个顺序,让它按照传递的顺序排列
如果传递了一个行,但不在data中,他的结果将为NA值
from pandas import Series,DataFrame
data={'state':['a','b','c','d','e'], 'year':[2000,2001,2002,2001,2002],'pop':[1.5,1.7,3.6,2.4,2.9]}
frame=DataFrame(data,columns=['state','year','pop','newCol'],index=['one','two','three','four','five'])
print(frame)
在DataFrame中的一列可以通过字典记法或属性来检索
from pandas import Series,DataFrame
data={'state':['a','b','c','d','e'], 'year':[2000,2001,2002,2001,2002],'pop':[1.5,1.7,3.6,2.4,2.9]}
frame=DataFrame(data,columns=['state','year','pop','newCol'],index=['one','two','three','four','five'])
print(frame['state'])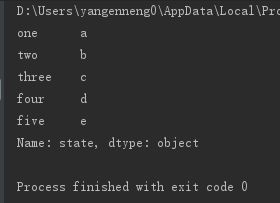
行业可以通过位置或名字来索引,列入按ix索引成员
from pandas import Series,DataFrame
data={'state':['a','b','c','d','e'], 'year':[2000,2001,2002,2001,2002],'pop':[1.5,1.7,3.6,2.4,2.9]}
frame=DataFrame(data,columns=['state','year','pop','newCol'],index=['one','two','three','four','five'])
print(frame.ix['three'])
列可通过赋值来修饰
from pandas import Series,DataFrame
data={'state':['a','b','c','d','e'], 'year':[2000,2001,2002,2001,2002],'pop':[1.5,1.7,3.6,2.4,2.9]}
frame=DataFrame(data,columns=['state','year','pop','newCol'],index=['one','two','three','four','five'])
frame['newCol']=100
print(frame)
