1. 安装CUDA安装包
==================
由于目前的CUDA安装包自带显卡驱动、CUAD工具、OpenCL的SDK;其中OpenCL的相关内容的默认目录有:
CL文件夹的目录:C:\Program Files\NVIDIA GPU Computing
Toolkit\CUDA\v7.0\includeOpenCL.lib文件目录:C:\Program Files\NVIDIA GPU Computing
Toolkit\CUDA\v7.0\libOpenCL.dll文件目录:C:\Program Files\NVIDIA Corporation\OpenCL
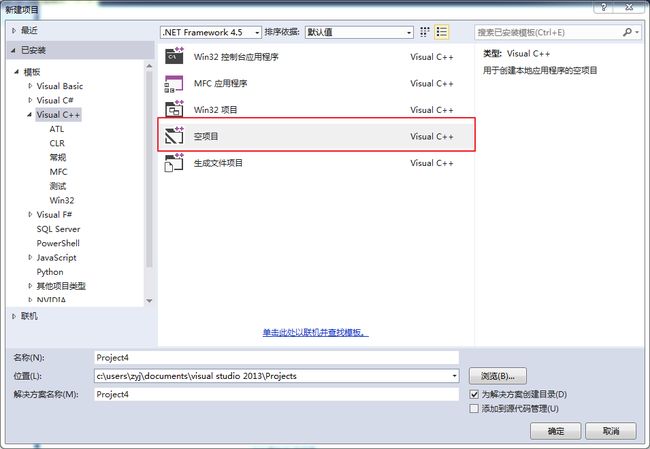
2. 新建空项目
==============
可以通过VS2013的VC++模板新建一个空项目;
3. 添加文件
============
为了验证配置的正确性,所以为项目添加两个文件:cl_kernel.cl和main.cpp。
- 添加cl_kernel.cl文件
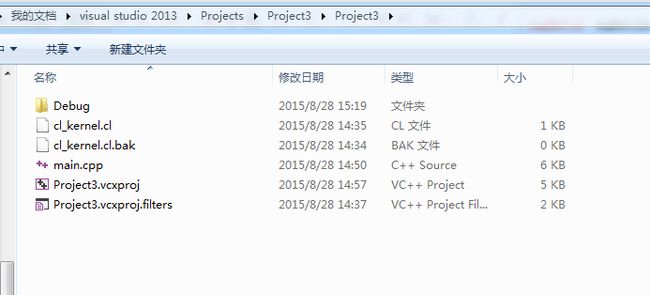
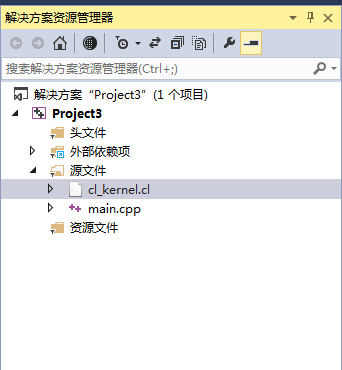
其中在项目所在的目录下新建一个cl_kernel.cl文件,其内容为附录1所示,目录结构如图1所示。同时在VS2013的项目中将cl_kernel.cl文件添加到项目的“源文件”筛选器中,如图2所示。
- 添加main.cpp文件
类似cl_kernel.cl文件操作,同样将main.cpp文件添加到项目中。
4. 配置CL目录
==============
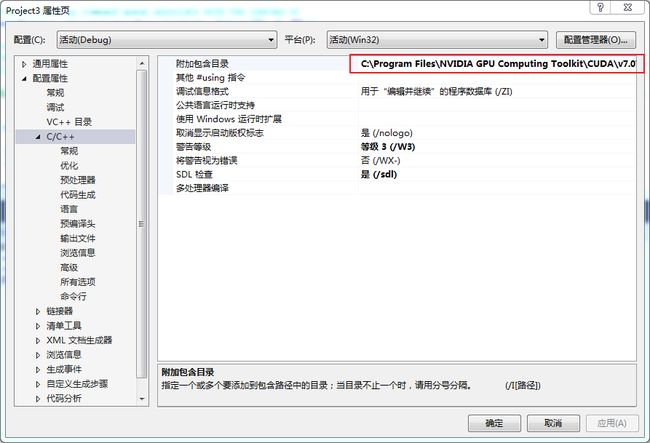
需要将OpenCL的SDK的头文件包含到项目中,具体操作方法为:
在项目->属性->配置属性->C/C++->常规->附加包含目录->配置,然后添加CL文件夹的目录:C:\Program
Files\NVIDIA GPU Computing Toolkit\CUDA\v7.0\include。如图 3所示。
5. 配置预处理器
================
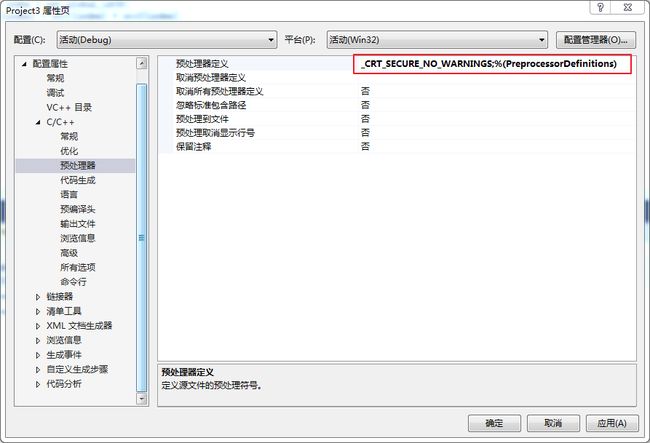
项目->属性->配置属性->c/c++->预处理器定义->编辑,然后添加“_CRT_SECURE_NO_WARNINGS”,否则会报错。
6. 配置外部依赖OpenCL.lib目录
==============================
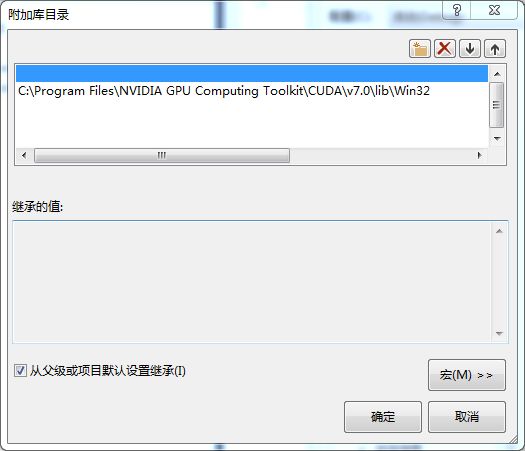
具体操作:项目->属性->配置属性->链接器->常规->附加库目录。然后将OpenCL.lib文件所在的目录添加进去,其中需要注意的是将程序Debug成32位和64位平台添加的Opencl.lib目录是不同的,如图
4所示,是Debug成Win32平台,所以只加“C:\Program Files\NVIDIA GPU Computing
Toolkit\CUDA\v7.0\lib\Win32”路径;若是Debug成X64,则添加的路径为“C:\Program
Files\NVIDIA GPU Computing
Toolkit\CUDA\v7.0\lib\x64”。同时需要在“启用增量链接”选项中选否。

7. 配置OpenCL.lib文件
==================
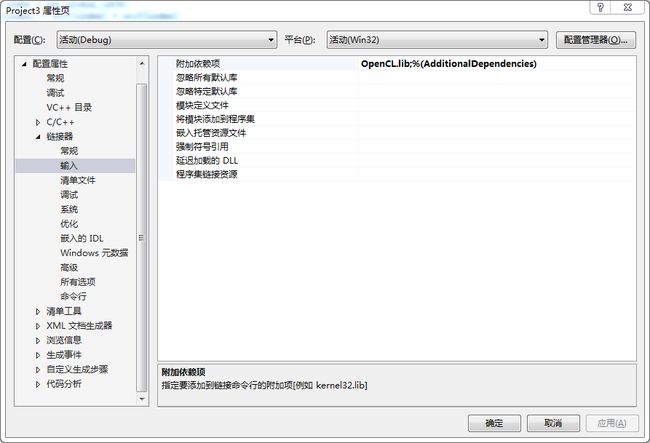
项目->属性->配置属性->连接器->输入->附件依赖库->编辑,接着添加OpenCL.lib
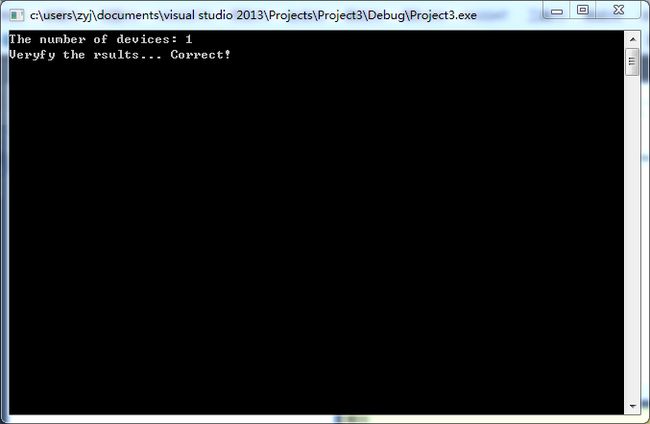
8. 运行结果图
==============
附录
附录1 cl_kernel.cl文件
__kernel void MyCLAdd(__global int *dst, __global int *src1, __global int *src2)
{
int index = get_global_id(0);
dst[index] = src1[index] + src2[index];
}
附录2:main.cpp文件
#include
#include
#include
using namespace std;
int main(void){
cl_uint numPlatforms = 0; //the NO. of platforms
cl_platform_id platform = nullptr; //the chosen platform
cl_context context = nullptr; // OpenCL context
cl_command_queue commandQueue = nullptr;
cl_program program = nullptr; // OpenCL kernel program object that'll be running on the compute device
cl_mem input1MemObj = nullptr; // input1 memory object for input argument 1
cl_mem input2MemObj = nullptr; // input2 memory object for input argument 2
cl_mem outputMemObj = nullptr; // output memory object for output
cl_kernel kernel = nullptr; // kernel object
cl_int status = clGetPlatformIDs(0, NULL, &numPlatforms);
if (status != CL_SUCCESS)
{
cout << "Error: Getting platforms!" << endl;
return 0;
}
/*For clarity, choose the first available platform. */
if (numPlatforms > 0)
{
cl_platform_id* platforms = (cl_platform_id*)malloc(numPlatforms* sizeof(cl_platform_id));
status = clGetPlatformIDs(numPlatforms, platforms, NULL);
platform = platforms[0];
free(platforms);
}
else
{
puts("Your system does not have any OpenCL platform!");
return 0;
}
/*Step 2:Query the platform and choose the first GPU device if has one.Otherwise use the CPU as device.*/
cl_uint numDevices = 0;
cl_device_id *devices;
status = clGetDeviceIDs(platform, CL_DEVICE_TYPE_GPU, 0, NULL, &numDevices);
if (numDevices == 0) //no GPU available.
{
cout << "No GPU device available." << endl;
cout << "Choose CPU as default device." << endl;
status = clGetDeviceIDs(platform, CL_DEVICE_TYPE_CPU, 0, NULL, &numDevices);
devices = (cl_device_id*)malloc(numDevices * sizeof(cl_device_id));
status = clGetDeviceIDs(platform, CL_DEVICE_TYPE_CPU, numDevices, devices, NULL);
}
else
{
devices = (cl_device_id*)malloc(numDevices * sizeof(cl_device_id));
status = clGetDeviceIDs(platform, CL_DEVICE_TYPE_GPU, numDevices, devices, NULL);
cout << "The number of devices: " << numDevices << endl;
}
/*Step 3: Create context.*/
context = clCreateContext(NULL, 1, devices, NULL, NULL, NULL);
/*Step 4: Creating command queue associate with the context.*/
commandQueue = clCreateCommandQueue(context, devices[0], 0, NULL);
/*Step 5: Create program object */
// Read the kernel code to the buffer
FILE *fp = fopen("cl_kernel.cl", "rb");
//错误 1 error C4996 : 'fopen' : This function or variable may be unsafe.Consider using fopen_s instead.To disable deprecation, use _CRT_SECURE_NO_WARNINGS.See online help for details.c : \users\zyj\documents\visual studio 2013\projects\project3\project3\main.cpp 67 1 Project3
if (fp == nullptr)
{
puts("The kernel file not found!");
goto RELEASE_RESOURCES;
}
fseek(fp, 0, SEEK_END);
size_t kernelLength = ftell(fp);
fseek(fp, 0, SEEK_SET);
char *kernelCodeBuffer = (char*)malloc(kernelLength + 1);
fread(kernelCodeBuffer, 1, kernelLength, fp);
kernelCodeBuffer[kernelLength] = '\0';
fclose(fp);
const char *aSource = kernelCodeBuffer;
program = clCreateProgramWithSource(context, 1, &aSource, &kernelLength, NULL);
/*Step 6: Build program. */
status = clBuildProgram(program, 1, devices, NULL, NULL, NULL);
/*Step 7: Initial inputs and output for the host and create memory objects for the kernel*/
int __declspec(align(32)) input1Buffer[128]; // 32 bytes alignment to improve data copy
int __declspec(align(32)) input2Buffer[128];
int __declspec(align(32)) outputBuffer[128];
// Do initialization
int i;
for (i = 0; i < 128; i++)
input1Buffer[i] = input2Buffer[i] = i + 1;
memset(outputBuffer, 0, sizeof(outputBuffer));
// Create mmory object
input1MemObj = clCreateBuffer(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR, 128 * sizeof(int), input1Buffer, nullptr);
input2MemObj = clCreateBuffer(context, CL_MEM_READ_ONLY | CL_MEM_COPY_HOST_PTR, 128 * sizeof(int), input2Buffer, nullptr);
outputMemObj = clCreateBuffer(context, CL_MEM_WRITE_ONLY, 128 * sizeof(int), NULL, NULL);
/*Step 8: Create kernel object */
kernel = clCreateKernel(program, "MyCLAdd", NULL);
/*Step 9: Sets Kernel arguments.*/
status = clSetKernelArg(kernel, 0, sizeof(cl_mem), (void *)&outputMemObj);
status = clSetKernelArg(kernel, 1, sizeof(cl_mem), (void *)&input1MemObj);
status = clSetKernelArg(kernel, 2, sizeof(cl_mem), (void *)&input2MemObj);
/*Step 10: Running the kernel.*/
size_t global_work_size[1] = { 128 };
status = clEnqueueNDRangeKernel(commandQueue, kernel, 1, NULL, global_work_size, NULL, 0, NULL, NULL);
clFinish(commandQueue); // Force wait until the OpenCL kernel is completed
/*Step 11: Read the cout put back to host memory.*/
status = clEnqueueReadBuffer(commandQueue, outputMemObj, CL_TRUE, 0, global_work_size[0] * sizeof(int), outputBuffer, 0, NULL, NULL);
printf("Veryfy the rsults... ");
for (i = 0; i < 128; i++)
{
if (outputBuffer[i] != (i + 1) * 2)
{
puts("Results not correct!");
break;
}
}
if (i == 128)
puts("Correct!");
RELEASE_RESOURCES:
/*Step 12: Clean the resources.*/
status = clReleaseKernel(kernel);//*Release kernel.
status = clReleaseProgram(program); //Release the program object.
status = clReleaseMemObject(input1MemObj);//Release mem object.
status = clReleaseMemObject(input2MemObj);
status = clReleaseMemObject(outputMemObj);
status = clReleaseCommandQueue(commandQueue);//Release Command queue.
status = clReleaseContext(context);//Release context.
free(devices);
}