可重复性研究:如何保证你的研究结果可重现?
连玉君 (中山大学,[email protected] , 主页:lianxh.cn)
陈鑫梅 (暨南大学,[email protected] )
特别声明: 本文部分内容摘译自以下文章:
- Orozco, Valerie, Christophe Bontemps, Elise Maigne, Virginie Piguet, Annie Hofstetter, Anne Marie Lacroix, Fabrice Levert, and Jean-Marc Rousselle. 2018. “How To Make A Pie: Reproducible Research for Empirical Economics & Econometrics.” Post-Print. 2017. -PDF1-,-PDF2-
- Michael S. Hill. In Stata coding, Style is the Essential: A brief commentary on do-file style
连享会 - 效率分析专题,2020年5月29-31日
主讲嘉宾:连玉君 | 鲁晓东 | 张宁
详情,微信版,PDF版
不知大家是否有如下经历:
- 作为论文作者: 收到审稿意见,要求大幅修改 (e.g., 更新一年的数据)。然而,在电脑了找了一上午,也没有找到三个月前跑回归时的 dofile。
- 作为导师: 繁忙的 6 月过去了,学生们都去投行了。我们静下心来,把 1-2 篇优秀的硕士论文拿出来修改,准备投稿。却发现当时学生并没有把原始数据和代码留下来,而且,学生的邮件回复说:「老师,我换了新电脑,以前的文件都没了,……」。此时,你开始犹豫要不要投稿。你不知道论文中是否有「刻意追星」行为,你更担心外审意见回来后,你该如何对着学生的论文另起炉灶地跑一次回归?
- 作为合作者: 你的合作者想了解一下你的实证分析过程,以便确认一些关键环节的处理是否妥当。然后,你们视频通话,你用了一上午的时间给他演示如何一步一步「点菜单」,以便得到你想要的结果。期间,你不停地重试,回忆……,因为,你其实也很难记清楚当时你点了哪些奇怪的「按钮」,然后就得到了那些看起来还不错的结果。
如果你经历了上述囧境,但仍然像「寒号鸟」那样心存侥幸,那你的痛苦历程其实才刚刚开始。
本文便是综合了一些前辈们的经验,为大家分享一些基本的工作原则,以便日后能够做「可重复的研究」。好处在于:一方面,我们能避免上述窘境,另一方面,也是更重要的,你的团队会因此形成「知识积累」:团队新成员总能够在老成员的工作基础上快速跟进;作为信息枢纽的导师,也更容易组织大家分享彼此的新知,形成良好的团队协作氛围。 当然,从更为高大上的角度来讲,你若通过 - Harford Dataverse - https://dataverse.harvard.edu/dataverse 之类的网站公布原始数据和程序,对于推广研究成果,提高论文的引用率也会有很大的帮助,你也会因此而结识一批志同道合的同仁 (ps, 「连老师的链接」 页面提供了很多可以获取重现论文资料的网站的链接。微信用户可以点击底部 「阅读原文」 查看)。
在此前的直播课「我的特斯拉-实证研究设计」 (课程主页:https://gitee.com/arlionn/Live) 中,我就专门花了 10 几分钟的时间介绍可重复研究的重要性,以及如何重现论文,如何获取重现论文的数据和程序等问题。
1. 简介:何谓可重复性研究 ?
地质学家约翰·克拉伯特 (John Claerbout) 将「可重复研究」定义为“其他科学家复制 (论文) ”的可能性。
Hamermesh (2007) 建议区分两个概念:「纯复制」 (“pure replication”) 和「科学复制」 (“scientific replication”):
- 「纯复制」 是指几乎完全复制手头研究的能力,主要用于验证。
- 「科学复制」是指在其他数据库上重复使用现有的研究材料,并将其视为稳健性测试或拓展原始研究工作。
对于许多研究项目来说,如果该项目的作者为所有其他研究人员提供了用以完全重现论文结果的所有资料 (数据和程序),则该项目被认为是可重复的。
当然,本文的目的不是为了辨析这些定义,我们更关注的是与这些概念相关的实际问题。我们的目标是通过提供建议,方法和工具来提高研究的可重复性。
先前的论文试图将可重复性研究的概念界定为一套适用于特定情况和软件的精确规则或原则 (Gentzkow & Shapiro, 2014; Sandve et al. , 2013; Hinsen, 2015) 。 我们仅提出三个主要和简单的原则,以从更广泛的意义上增强研究的可重复性。这些原则是:
- 合理安排研究工作
- 写代码的良好习惯
- 自动化输出
简言之,「良好的写代码习惯」可以保证你的代码具有可读性、易读性,这便于你的合作者与你协作修改和完善代码,也有助于你日后更新这些代码。「自动化输出」则可以保证从计量软件到文字排版软件之间的无缝连接,一方面节省了体力,另一方面则减少了编排过程中导致的错误。
连享会直播 - 生存分析 (Survival Analysis) 专题
主讲嘉宾:王存同教授 (中央财经大学)
2020年6月6日,详情
2. 合理安排研究工作
一个研究项目可能是一个复杂的过程,Long (2009) 将其设定为一个周期:计划、组织、计算、记录。项目之初,计划相当笼统,随着项目的进行而变得更加精确。某些阶段可以顺序执行,而其他阶段则可以重叠。因此,最好在项目开始时考虑并计划组织。
你可以列一个日程表,也可以画一个思维导图。总之,要做到心中有数,避免过度自信和过度拖延。
2.1 组织任务和文档
管理项目的一种好方法是预先了解项目的所有任务及其内容、成果、组织和目标。了解所涉及的不同人员及其在项目和任务期限中的作用。安排工作,记录已完成的任务,放弃的方向,新方向等,文件是关键要素,文件的缺失将导致研究无法重现。
需要说明的是,最好建立起「版本控制」的理念,也就是说,在修改文稿和代码的过程中,可以将关键版本保留下来,而不要始终都只在一个版本上进行。这样,日后回顾起来,就比较容易了解到自己走过哪些弯路,哪些工作受限于当时的条件无法推进,但可以留待日后进行;哪些工作是因为犯了低级错误而需要另起炉灶,……。这些经验的积累可以保证日后的研究工作尽量少犯同类错误,而有些在当前研究过程中被暂时抛弃的主题也可能成为后续研究的重要选题来源。
A. 从便签到任务管理系统
对社会科学研究者而言,倾向于将待办事项写在笔记本上。然而,从可重现的角度来看,电子文档优于纸质文档。然而,在团队协作中,协作者互动相当普遍的,简单工具无法用于记录互动和每个人的笔记。电子实验室笔记本 (ELNs) 是记录和管理笔记最为普遍的方式。目前 Evernote, OneNote 和 Etherpad 应用最为广泛,它们都能跨平台同步笔记。
对于国内用户而言,印象笔记、有道云笔记、为知笔记都是不错的选择,笔者常用的是「有道云笔记+ VScode + Typora 编辑器」。我们认为,选择一个云笔记的基本原则如下:
其一,要能跨平台实时同步,这样你就可以在手机上、电脑上、Ipad 上随时记录你的想法;
其二,要能很快捷地分享笔记给团队成员;
其三,最好是一款免费的、由大公司提供的软件,前者保证了我们的所有成员都可以公平地协作,后者的重要性不言而喻;
最后,最好能支持 Markdown 语法,这样就可以写出包含数学公式、图表和代码块的漂亮的笔记,也方便日后转换为 Word,PDF 和幻灯片文档。有关 Markdown 的介绍参见 https://gitee.com/arlionn/md。
任务管理系统 (TMS) 为更通用的协作式和集中式任务组织提供功能。 TMS 将每个任务用一张包含描述等信息的卡片呈现,可将任务分配给合作者,或将其移到,“进行中”和“完成”分类项,也可给任务添加截止日期。
编者注: 对于经管类研究者而言,上面这个建议可以忽略。我们曾经是用了一段时间 「码云」- https://gitee.com/ ,用 看板 进行任务管理,但最终无疾而终。原因在于,多数成员很不习惯这种方式 (非工科的都不太习惯,=),加之国内的微信和微信群实在是太高效。
B. 从注释到任务文档
记录任务应当被看作第一要务。
项目进行期间,应计划并实施定期更新,以免丢失任何的信息。从概念上讲,任务文档由对要做的事情,所涉及的人员,计划的任务及其状态 (要做,进行中或已完成) 的简短描述组成。
- 任务中无法解释的信息 (例如代码) 也应在任务文档中记录:有关项目的一般选择 (假设、建模,研究人群等) 和可能会影响结果的技术规范。
- 程序也需要文档化,大多数程序可以嵌入代码中。然而,技术日新月异,如果计算机环境发生变化,则代码执行可能会发生变化。因此,对研究程序进行文档记录不仅限于程序文档,还必须确保详细解释整个工作流程,包括描述计算环境 (如计算机的操作系统、硬件配置、所用统计和软件的版本、外部命令或包的版本等)。
2.2 管理文件夹
大多数情况下,研究者会以不同的个人风格管理文件夹。我们主要关注文件管理的两个方面:目录结构和命名方法。
目录结构旨在帮助找到需要的元素 (代码、数据、输出) ,这在时间跨度长的项目中尤其重要。在构建项目目录结构时,可以使用两种指导思想:文件夹应该包含相同类型的同类元素 (数据、程序、文本、文档) ;明确区分项目的投入和项目的产出。我们在图 1 中提出了一个简单的目录结构,非常类似于 Gentzkow & Shapiro (2014) 的目录结构。
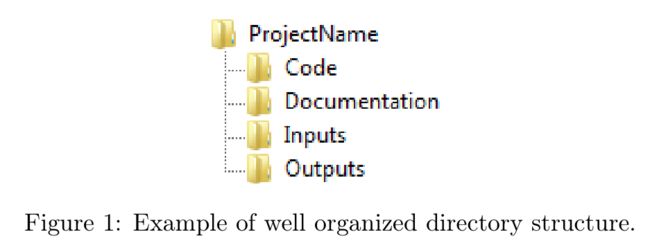
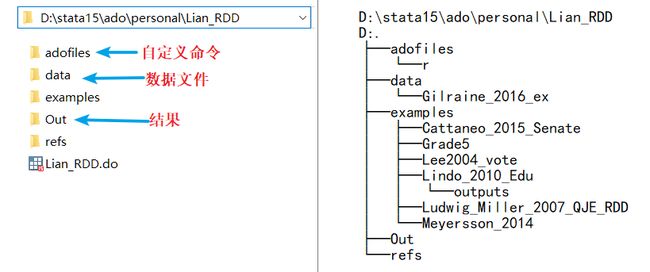
下图是连老师 RDD 课件的目录结构:
你可以可以到 连享会 - 经典论文重现主页 - Wikis,网址为:https://gitee.com/arlionn/paper101,查看这篇论文的重现资料 目录结构。
如下是连老师的几个直播课的相关课件和目录结构 (网址:https://gitee.com/arlionn/Live):
- 我的特斯拉-实证研究设计,文件目录树,课件
- 我的甲壳虫-经典论文重现,文件目录树,课程主页,幻灯片
- 动态面板数据模型
另外,输出可以根据生成它的程序的名称命名,并在后面加上后缀。这个简单的规则允许快速定位文件。例如,程序 stats_desc.do 输出的结果命名为 stats_desc_out.xlsx。文件命名要尽可能简短,根据 Long (2009) ,我们建议将文件或文件夹名称中使用的字符限制为 a-z、A-Z、0-9 和下划线,也可以视情况在文件名末尾加上版本信息 (v1, v2, v3)。
2.3 跟踪工作流程
目前,有许多方法来表示工作流程,就像有许多方法来进行研究一样,但是在实证研究中的任何项目都有一个通用的全局结构,遵循图 2 左边显示的文件的顺序创建。为了使整个研究项目具有可重复性,所有文件、所有链接和整个工作流程都应该尽可能清晰和明确。这个过程对于研究者和“陌生人”理解程序 (图 2 中的圆圈) 和数据 (矩形) 是如何关联的,程序之间是如何关联的,以及它们的运行顺序是非常关键的。

管理工作流程有多种方法。一个解决方案是记录整个工作流程并生成一个图表,如图 2 所示。存在不同的工具来创建、管理和图形化地可视化工作流。另一个想法是使用命名约定。例如,Chuang 等人 (2015) 建议在程序名称前放置一个数字,指示执行顺序,如图 3 (改成代码样子) 所示。这就是 Long (2009) 所说的“运行顺序规则”。

当然,很多情况下你也无需把问题搞的这么复杂,下面是连老师常用的文件命名方法:
- 每个计量专题对应一个 dofile 和一个同名的文件夹,如「B4_RDD.do」与【B4_RDD】对应,而后者有进一步包含五个子文件夹,以便分类存储数据、参考文献和输出结果等不同类型的文件。

2.4 Handling files 处理文件
毫无疑问,好的文件管理能提高研究项目的可重复性,然而,随着项目规模、合作者和时间的增加,要求改变文件处理策略以克服三个主要问题: 文件应该如何共享?应该如何比较文件和管理版本?在撰写联合论文时,研究人员应该如何合作?
目前,文件共享有多种方式。比如,你可以注册一个「坚果云」账号,这样就可以与你的合作者共享一个文件夹,你们两个写的东西都会被自动传到云端,然后再同步到你们彼此的电脑上。对于完成初稿后的反复修改阶段而言,这种共享方式非常方便 (不用每天不停地通过微信或邮件传送文件了)。
不过,「坚果云」的免费版本只允许你与五个人协作,否则就需要付费。价格不高,但对于很多习惯了吃免费大餐的用户而言,付几十块钱购买一个优质的服务仍然像割肉般痛苦。
若是使用 Markdown 写初稿或研究设计,可以使用「有道云笔记」的 云协作 功能。反复几个来回,定稿后,可以使用「Typora 编辑器」将 Markdown 文档转换成 PDF 或 Word 文档。
备份文档很重要,应该不用多言。备份相对比较方便。我目前使用两种方式:
- 一是「坚果云」,只需右击需要备份的文档,依次选择「发送到(N)」→「坚果云」。
- 二是「百度云盘」,右击某个文件夹,选择「自动备份该文件夹」。
3. 良好的代码写作习惯
对于许多人来说,任何一段代码的特征都能被计算机理解并加以执行,计算出能反映作者意图的明确而正确的指令 (Gentzkow&Shapiro,2014) 。然而,在可重复性研究方面,代码不仅需要正确运行,它应该以清晰的方式编写,以使人们可以理解。
如下是一些 基本建议:
- 所有的操作 (包括: 数据处理、绘图、回归分析、结果输出等) 都要记录在 dofile 中,尽量不要手动处理
- 每个项目 (每篇论文) 一个文件夹;文件分类存放,文件尽可能按照特定规则命名
- 每天实时保存的是 dofiles,而不是 数据文件
- 多加注释,以便增强代码的可读性
- 注意排版,保证美观的同时,也便于查错
这里,先提供一个虚构的「dofile 范本」,以便让各位了解上述原则的基本精神。
- 首先,在 dofile 的开头,标明了文件的生成日期、作者、作用等;
- 其次,在「A. 基本设定」部分用全局暂元
global定义了文件的存储路径和子文件夹的名称简写,以便后续将不同类新的文件分门别类地存放起来; - 再次,D#.xxx,S#.xxx,R#.xxx 等部分依次为数据处理、统计分析和回归分析等内容。如此以来,即使 dofile 写的很长,仍然可以通过 Ctrl+F 快捷键快速搜索关键词定位。
- 最后,值得注意是,我们频繁地使用了
local和global,尤其是【R. 回归分析】部分。这种做法好处很多,比如,代码的结构看起来很清晰;很容易修改,只需在定义暂元的地方统一做一次修改即可,这可以大幅降低出错的概率;代码变得很简洁,可读性自然就提高了。
*------------------
*- 一个 dofile 范本 www.lianxh.cn
*------------------
* Version 1.1, 2020/5/10 15:04
* Author: 连家大公子
* 目的:分析家庭收入对子女学习成绩的影响
*-A. 基本设定
global path "D:\myPaper\Income_Mark" //定义项目目录
// 需要预先在生成子文件夹:data, refs, out, adofiles
global D "$path\data" //数据文件
global R "$path\refs" //参考文献
global Out "$path\out" //结果:图形和表格
adopath + "$path\adofiles" //自编程序+外部命令
cd "$D" //设定当前工作路径
set scheme s2color
*-核心参考资料 (参考文献和文档都存放于 $R 文件夹下)
shellout "$R\Safin_Federer_2005_Aust.pdf"
*-D1. 数据导入
import excel using "$D\Income_Mark.xlsx", first clear
save "_temp_" // $D\ 可以省略,应为当前工作路径就是 $D
// 如果原始数据文件不大,此步骤可以省略
*-D2. 数据处理
gen ……
winsor2 ……
……
save "data_dealed.dta", replace
*-S1. 基本描述性统计分析
// 如果数据处理部分未作更新,可直接这里进行后续分析
*-----表x:基本统计量-------
use "data_dealed.dta", clear
local v " " //填入变量名
local s "$Out\Table1_sum" //存储的文件名(或路径\文件名)
logout, save("`s'") excel replace: ///
tabstat `v', stat(mean sd p50 min max) f(%6.2f) c(s)
*-----表x:相关系数矩阵-------
local v " " //填入变量名
local s "$Out\Table2_corr" //存储的文件名(或路径\文件名)
logout, save("`s'") excel replace: ///
pwcorr_a `v', format(%6.2f) //star(0.05)
*-S2. 分组统计分析
use "data_dealed.dta", clear
*-----表x:组间均值差异检验-------
local v " " //填入变量名
local s "$Out\ttable2" //存储的文件名(或路径\文件名)
logout, save("`s'") excel replace: ///
ttable2 `v', by(variable) format(%6.2f)
*-R. 回归分析
use "data_dealed.dta", clear
global y "Mark" //被解释变量
global x "Income" //基本解释变量
global z "edu_Dad edu_Mum Age##Age ……" //基本控制变量
global w "i.year i.industry i.race" //虚拟变量
*global opt ", vce(robust)"
global opt ", vce(cluster industry)"
reg $y $x $opt
est store m1
reg $y $x $z $opt
est store m2
reg $y $x $z $w $opt
est store m3
*-----表x:回归结果-------
local s "using $Out\Table3_reg.csv" //执行时包括这一行会输出Excel表格
local m "m1 m2 m3"
esttab `m' `s', nogap compress replace ///
b(%6.3f) s(N r2_a) drop(`drop') ///
star(* 0.1 ** 0.05 *** 0.01) ///
addnotes("*** 1% ** 5% * 10%") ///
indicate("行业效应 =*.industry" "年度效应 =*.year")
事实上,你若能在开始时遵守上述基本原则,就会慢慢发现它的好处远远大于你花费在排版上的成本。久而久之,你也会形成自己的代码风格。我看到很多朋友和学生的 dofile 大致都长成下面这个「连氏 dofile」的样子,一点也不觉得奇怪,因为很多人都是从我这里获取了课件,开始学习 Stata,然后又将这些课件作为模板移植到自己的论文中去的。
前文提到的 B4_RDD.do 文档的基本设定如下

下面,着重解释一些最重要的原则。
3.1 实时保存 dofile 而不是数据文件
有些人在下班前喜欢把当天处理好的数据另存一份,这是个非常糟糕的习惯!
我的建议是:保存 dofile,而不是数据文件!
原因很简单,一个 dofile 只有几 k 或几十 k,但数据文件往往很大。更重要的是,如果保存了太多版本的数据文件,随后会导致严重的混乱,你的「可重复研究」基本上是无法保证的。
你若按我上述提供的模板来写 dofile,其实只需要保持 import xxx.xlsx 这条语句,就可以快速导入数据。后续对数据所进行的所有处理动作都完整地记录在 dofile 中,容易查错,也容易提供给他人,以便进一步跟进后续研究。
3.2 空格和注释语句
Stata没有空格和制表符的限制,为了让代码更加美观和易读,要合理使用空格和缩进。借用 J.Scott Long (2009) 的例子说明空格的重要性:
rename k12_unique_id sid
rename class_unique_id class_id
rename teacher_name teacher
*或者这样
rename k12_unique_id sid
rename class_unique_id class_id
rename teacher_name teacher
//可以看到后者更直观。
缩进对代码的跨行阅读也有帮助,在视觉上更容易接受:
keep sid class_id teacher grade1 ///
grade2 grade3 pass
而不是
keep sid class_id teacher grade1 ///
grade2 grade3 pass
注释在理解代码方面起着至关重要的作用,通常而言有三种方法键入注释。
*用于某行开头,表示整行注释!
//用在某行中的任意位置,该位置后的所有内容都是注释。
/*可用于跨行注释 */
至于暂元 (local 或 global) 的使用,以及其他议题,可以参阅 连享会 (lianxh.cn) 上的推文,亦可扫描二维码进入 连享会主页,知乎推文,或者如下分类链接,查看公众号历史推文:

NEW!连享会·推文专辑:
Stata资源 | 数据处理 | Stata绘图 | Stata程序
结果输出 | 回归分析 | 时间序列 | 面板数据 | 离散数据
交乘调节 | DID | RDD | 因果推断 | SFA-TFP-DEA
文本分析+爬虫 | 空间计量 | 学术论文 | 软件工具
4. 自动化输出
可重复性研究将极大地帮助任何终端用户 (“陌生人”或“未来的自己”) 使用和复制研究成果,所需的条件很简单:每个阶段都必须存在代码,并且所有阶段的所有代码都应该提供对所有结果的访问。在实证论文中,为了生成结果表,通常做法是逐个报告结果,或者手动复制粘贴汇总结果。在 Stata 中,我们经常使用 esttab, outreg2 等命令来实现结果的自动化输出。
由于连享会此前已经分享过多篇有关「结果输出」的文章,这里不再赘述,仅列出相关链接,并做一些必要的补充。
- 连享会主页 - 结果输出专题, https://www.lianxh.cn/blogs/22.html
- 连享会知乎 - 结果输出
- 连享会公众号 - 结果输出专辑
5. 研究过程中的报告文档 —— 幻灯片
其实,多数文档是作为研究过程中的「阶段性汇报或交流」目的而产生的。例如,我的博士生每周会做一次工作进展汇报,要用幻灯片来呈现研究思路、实证分析结果等内容。
显然,若每周做一份 PPT,必然会占用大量时间和精力。所以,我们用「幻灯片」,而不是「PPT」来展示 (PPT 已经成为基于 PowerPoint 制作的幻灯片的专有称呼了)。有两种方式可以快速生成这类漂亮、简洁、几乎不用额外花时间制作的幻灯片。
其一,可以把平时用 Markdown 记录的文档贴入 web.marp.app 网站,进而添加一些 --- 用于分页即可。这样,普通的 Markdown 文档就被快速转换成幻灯片了,可以输出为 HTML 或 PDF 格式。有关 Marp 的用法可以参见 「连玉君 - 五分钟 Markdown」 (内含视频、幻灯片样本和原始 Markdown 文档等),可以查阅 -Marp-进阶1-;-Marp-进阶2- 了解高阶使用方法。
其二,若平时的讨论笔记都记录于「有道云笔记」,则可以使用 分享 功能产生分享链接,进而将该链接贴入 Google 浏览器 (注意;请务必删除多余的文字,仅保留 https://note.youdao.com/ 开头的网址部分即可),点击右上角的【演示按钮】即可全屏呈现文稿内容。虽然效果不如幻灯片那么好,但作为平时的交流展示已经绰绰有余了。
参考文献
- Hamermesh, Daniel S. 2007. “Viewpoint: Replication in Economics.” Canadian Journal of Economics 40 (3): 715–33. [PDF]
- Michael S. Hill. In Stata coding, Style is the Essential: A brief commentary on do-file style
- Long, J. The workflow of data analysis using stata[M]. Stata Press, 2009.
- Orozco, Valerie, Christophe Bontemps, Elise Maigne, Virginie Piguet, Annie Hofstetter, Anne Marie Lacroix, Fabrice Levert, and Jean-Marc Rousselle. 2018. “How To Make A Pie: Reproducible Research for Empirical Economics & Econometrics.” Post-Print. 2017. -PDF1-,-PDF2-
关于我们
- Stata连享会 由中山大学连玉君老师团队创办,定期分享实证分析经验。直播间 有很多视频课程,可以随时观看。
- 你的颈椎还好吗? 您将 ::连享会-主页:: 和 ::连享会-知乎专栏:: 收藏起来,以便随时在电脑上查看往期推文。
- 公众号推文分类: 计量专题 | 分类推文 | 资源工具。推文分成 内生性 | 空间计量 | 时序面板 | 结果输出 | 交乘调节 五类,主流方法介绍一目了然:DID, RDD, IV, GMM, FE, Probit 等。
- 公众号关键词搜索/回复 功能已经上线。大家可以在公众号左下角点击键盘图标,输入简要关键词,以便快速呈现历史推文,获取工具软件和数据下载。常见关键词:
课程, 直播, 视频, 客服, 模型设定, 研究设计,stata, plus,Profile, 手册, SJ, 外部命令, profile, mata, 绘图, 编程, 数据, 可视化DID,RDD, PSM,IV,DID, DDD, 合成控制法,内生性, 事件研究交乘, 平方项, 缺失值, 离群值, 缩尾, R2, 乱码, 结果Probit, Logit, tobit, MLE, GMM, DEA, Bootstrap, bs, MC, TFP面板, 直击面板数据, 动态面板, VAR, 生存分析, 分位数空间, 空间计量, 连老师, 直播, 爬虫, 文本, 正则, pythonMarkdown, Markdown幻灯片, marp, 工具, 软件, Sai2, gInk, Annotator, 手写批注盈余管理, 特斯拉, 甲壳虫, 论文重现易懂教程, 码云, 教程, 知乎
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-o2wOxg8Z-1589359284825)(https://fig-lianxh.oss-cn-shenzhen.aliyuncs.com/连享会跑起来就有风400.png “连享会主页:lianxh.cn”)]
扫码加入连享会微信群,提问交流更方便
