Hive学习知识汇总
文章目录
- 1. Hive
- 1.1 Hive简介
- 1.2 Hive架构
- 2. Hive的搭建
- 2.1 单用户模式的搭建
- 2.2 Mysql的安装
- 2.3 多用户模式的安装(Remote分开)
- 3. Hive-SQL的学习
- 3.1 建表(create table)
- 3.2 Hive内部表与外部表
- 3.3 Hive的分区
- 3.4 Hive表复制与数据的加载
- 3.5 Serde(Serializer&Deserializer )
- 3.6 Hive的Beeline启动方式
- 4. Hive函数
- 4.1 Hive小练习
- 4.1.1 基站掉线率topN
- 4.1.2 Hive的wordcount实现
- 5. Hive的参数设置与动态分区
- 5.1 Hive的参数设置
- 5.3 Hive的动态分区
- 6. Hive的分桶
- 7. Hive视图&索引
- 7.1 Hive Lateral View
- 7.2 Hive的视图
- 7.3 Hive的索引
- 8. Hive的运行方式
- 8.1 命令行方式
- 8.2 脚本运行方式
- 8.3 JDBC运行方式
- 8.4 Web GUI接口hwi
- 9. Hive权限管理
- 9.1 SQL Standards Based Authorization in HiveServer2
- 10. Hive的优化
- 10.1 Hive优化的简介&EXPLAIN
- 10.2 Hive运行方式的优化
- 10.3 并行计算
- 10.4 严格模式
- 10.5 Hive排序
- 10.6 Hive Join
- 10.7 Map-Side聚合
- 10.8 控制Hive中的Map和Reduce数量
- 10.9 JVM重用
- 11. 小结
1. Hive
1.1 Hive简介
Hive:
- 数据仓库
- 解释器、编译器、优化器等
- Hive运行时,元数据存储在关系型数据库中
1.2 Hive架构

- 用户接口主要有三个:CLI,Client和WUI。其中最常用的是CLI,CLI启动的时候,会同时启动一个Hive副本。Client是Hive的客户端,用户连接至Hive Server,在启动Client模式的时候,需要指出Hive Server所在的节点,并且在该节点启动Hive Server,WUI是通过浏览器访问Hive
- Hive将元数据存储在数据库中,如mysql、derby。Hive中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
- 解释器、编译器、优化器完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在HDFS中,并在随后有MapReduce调用执行
- Hive的数据存储在HDFS中,大部分的查询、计算由MapReduce完成(包含*的查询,比如select * from tbl不会生成MapRedcue任务)
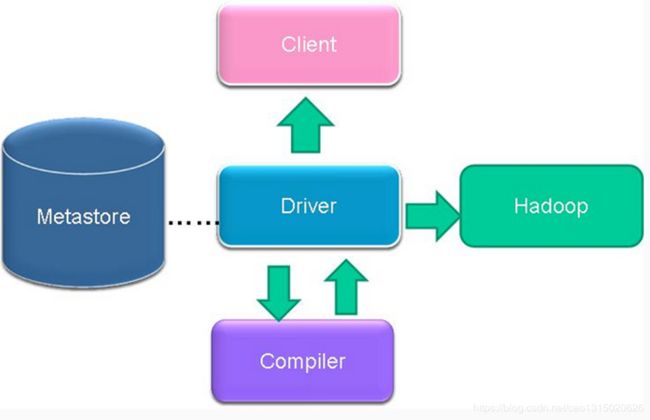
- 编译器将一个Hive SQL转换为操作符
- 操作符是Hive的最小的处理单元
- 每个操作符代表HDFS的一个操作或者一个MapReduce作业
- Operator都是hive定义的一个处理过程
2. Hive的搭建
无论是单用户还是多用户都需要先安装Hive,Hive的安装这里建议使用压缩包安装,可以下载Hive的压缩包,国内比较好用的镜像地址:Hive下载,下载之后正常的解压缩即可。如果hive -version显示正常版本号,表示安装成功。
注意所有的过程都是在hadoop集群环境开启的情况下构建的,如果还没有搭建hadoop集群,可以看:
Hadoop学习01之HDFS&Hadoop集群的搭建
2.1 单用户模式的搭建
通过网络连接到一个数据库中,是最经常用到的模式。

具体的配置在hive中就是更改压缩包conf 目录下的hive-default.xml文件mv hive-default hive-site.xml,然后对于hive-site.xml文件中的配置实现更改:
<configuration>
<property>
<name>datanucleus.schema.autoCreateAllname>
<value>truevalue>
property>
<property>
<name>hive.metastore.warehouse.dirname>
<value>/user/hive_remote/warehousevalue>
property>
<property>
<name>hive.metastore.schema.verificationname>
<value>falsevalue>
property>
<property>
<name>javax.jdo.option.ConnectionURLname>
<value>jdbc:mysql://node01/hive_remote?createDatabaseIfNotExist=truevalue>
property>
<property>
<name>javax.jdo.option.ConnectionDriverNamename>
<value>com.mysql.jdbc.Drivervalue>
property>
<property>
<name>javax.jdo.option.ConnectionUserNamename>
<value>rootvalue>
property>
<property>
<name>javax.jdo.option.ConnectionPasswordname>
<value>123value>
property>
configuration>
此时只要在/etc/profile下将HIVE_HOME配置好,以及将mysql的驱动jar包放入好hive的lib目录下即可,注意必须先安装mysql。
2.2 Mysql的安装
Mysql的安装yum install -y mysql-server,即可完成安装,完成安装以后,此时只是完成安装,还未启动,使用service mysqld start启动,chkconfig mysqld on检查是否开启,使用mysql进入到mysql,此时需要更改权限问题,确保此数据库通过其他网址只要用户名和密码正确都是能够访问到数据库中的内容的。
具体操作步骤如下:
show databases;展示所有数据库use mysql;使用mysql这个数据库show tables;展示库中的所有表,可以看到最后一行有user表- 使用
desc user;可以展示user表单具体信息 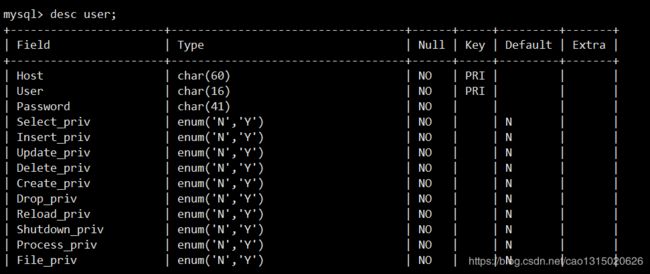
select user,host,password from user;获取到具体信息,- 修改权限:
GRANT ALL PRIVILEGES ON *.* TO 'root'@'%' IDENTIFIED BY '123' WITH GRANT OPTION;此时删除user表中其他的数据即可。flush privileges;刷新权限即可。 - 再次登录mysql,此时需要使用密码登录
mysql -uroot -p
2.3 多用户模式的安装(Remote分开)
这里主要是设定一台装有mysql的服务器作为存储元数据的关系型数据库,有一个服务端连接数据库,有一个客户端发起对服务端的请求,服务端负责处理请求返回结果。

具体:
node01 192.168.87.101 用作mysql服务器
node03 192.168.87.103 用作服务端
node04 192.168.87.104 用作客户端
具体配置:
首先需要确保node01,node03,node04需要安装好hive,而且整个过程都是在Hadoop集群的环境下搭建。
安装都是和前面一样,只需要修改hive-site.xml文件即可
服务端node03的配置文件:
<configuration>
<property>
<name>hive.metastore.warehouse.dirname>
<value>/user/hive/warehousevalue>
property>
<property>
<name>javax.jdo.option.ConnectionURLname>
<value>jdbc:mysql://192.168.87.101:3306/hive?createDatabaseIfNotExist=truevalue>
property>
<property>
<name>javax.jdo.option.ConnectionDriverNamename>
<value>com.mysql.jdbc.Drivervalue>
property>
<property>
<name>hive.metastore.schema.verificationname>
<value>falsevalue>
property>
<property>
<name>datanucleus.schema.autoCreateAllname>
<value>truevalue>
property>
<property>
<name>javax.jdo.option.ConnectionUserNamename>
<value>rootvalue>
property>
<property>
<name>javax.jdo.option.ConnectionPasswordname>
<value>123value>
property>
configuration>
客户端node04的配置:
<configuration>
<property>
<name>hive.metastore.warehouse.dirname>
<value>/user/hive/warehousevalue>
property>
<property>
<name>datanucleus.schema.autoCreateAllname>
<value>truevalue>
property>
<property>
<name>hive.metastore.schema.verificationname>
<value>falsevalue>
property>
<property>
<name>hive.metastore.urisname>
<value>thrift://192.168.87.103:9083value>
property>
configuration>
上述的配置好之后,使用hive命令,可以启动hive。注意,在启动之前最好先用hive --service metastore &;来先启动元数据同步服务(启动此服务可能会遇到阻塞,然后linux一直卡在这,使用ctrl+c可以继续执行)然后再启动hive即可。
这里一定要注意启动时候的顺序问题,我们的服务端是node03,所有的元数据的同步都是发生在node03上面,如果使用的是多用户的情况的话,我们需要在node03上面先使用hive --service metastore来同步元数据与关系型数据库中的数据。此时打开新开node03窗口,使用ss -nal可以发现9083端口在被客户端监听中:
注意,数据一定要同步,否则异常{FAILED: HiveException java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.ql.metadata.SessionHiveMetaStoreClient}会源源不断!!!!
此时的hive --service metastore进程处于阻塞中:

此时可以在node04也就是客户端操作我们的数据库,可以使用navicat来连接数据库,做到数据看可视化。

此时在navicat中可以看到:

表明操作成功。
3. Hive-SQL的学习
3.1 建表(create table)
建立学生表:
数据集
编号 姓名 爱好 地址
1,小明1,lol-book-movie,beijing:shangxuetang-shanghai:pudong
2,小明2,lol-book-movie,jiujiang:shangxuetang-shanghai:pudong
3,小明3,lol-book-basketball,nanchang:shangxuetang-shanghai:pudong
4,小明4,lol-book,nanjing:shangxuetang-shanghai:pudong
5,小明5,lol-book-play,beijing:shangxuetang-shanghai:pudong
6,小明6,lol-book-swim,beijing:shangxuetang-shanghai:pudong
7,小明7,lol-book-run,beijing:shangxuetang-shanghai:pudong
建表语句:
CREATE TABLE student(
id INT,
name STRING,
hobby ARRAY<STRING>,
addredd MAP<STRING,STRING>
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY '-'
MAP KEYS TERMINATED BY ':'
LINES TERMINATED BY '\n';
desc student查看此表的相关字段与类型
desc formatted student查看此表的详情
向表中插入数据:LOAD DATA [LOCAL] INPATH 'filepath' [OVERWRITE] INTO TABLE tablename [PARTITION (partcol1=val1, partcol2=val2 ...)] [INPUTFORMAT 'inputformat' SERDE 'serde'] (3.0 or later) 其中local字段如果加上的上表示上传的文件使用的是linux本地文件系统,如果不写local的话,使用的是HDFS文件系统中的文件。
-- 表示插入/datas/data文件到student表中
LOAD DATA LOCAL INPATH '/datas/data' INTO TABLE student;
注意,hive写入文件的时候是不做检查的,之后在读的时候会做检查,如果写入的文件和设定的文件格式化的标准不一致的话,文件的加载是完全正确的,但是不会有读取输出。
3.2 Hive内部表与外部表
Hive有内部表和外部表的区别,内部表的话存储的是HDFS的文件系统,外部表虽然存储的也是HDFS系统,但是在创建的时候需要指定文件存放的目录。
新建外部表语句:
CREATE EXTERNAL TABLE student2(
id INT,
name STRING,
hobby ARRAY<STRING>,
addredd MAP<STRING,STRING>
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY '-'
MAP KEYS TERMINATED BY ':'
LINES TERMINATED BY '\n'
LOCATION '/usr/data';
使用desc formatted table_name可以查看到表的详情,其中含有表的属性类型
Table Type: EXTERNAL_TABLE // 外部表
Table Type: MANAGED_TABLE // 内部表
内部表与外部表的区别:
- 外部表创建的时候需要指定目录,而内部表不需要
- 删除时内部表会将表结构和元数据全部删除,而外部表只删除表结构,不删除表数据。
3.3 Hive的分区
Hive分区类似于Mysql中的分库分表,在Hadoop中就类似于分组,这样在查询某一特征的时候,表查询的速度会非常的块,不至于全表查询会带来额外的负载。
Hive的分区需要在建表的语句中添加分区的标志位,以确保此表中含有分区的字段。
此时:
CREATE TABLE student3(
id INT,
name STRING,
hobby ARRAY<STRING>,
addredd MAP<STRING,STRING>
)
PARTITIONED BY (age int) // 这一句是给表中添加分区的标志
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY '-'
MAP KEYS TERMINATED BY ':'
LINES TERMINATED BY '\n';
注意,如果涉及到分区,往其中添加分区,此时会有hadoop来执行操作。
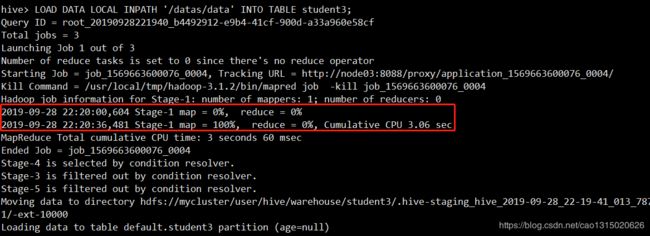
添加分区的值,可以设定几个不同的值作为不同的分区。以此来划分组。
注意分区值的导入需要添加入设定的分区字段的值,否则系统会报错,文件找不到:
Caused by: java.io.FileNotFoundException: File file:/datas/data does not exist
如果再次没有设定分区值运行,你将会收到一连串的错误。根本原因就是因为你没有设定分区字段的值。
注意如果单纯的是在已有的分区字段添加新的分区值,则新增的分区不会有数据,因为你没有进行导入
alter table student add partition(age=10,sex='boy'),只是新建分区,没有load数据加载进去
load data local inpath '/datas/data' into table student partition (age=20,sex='boy');新建了分区,且分区中含有数据。
分区的删除:
新建分区,两个有数据,两个没有数据(未加载数据)
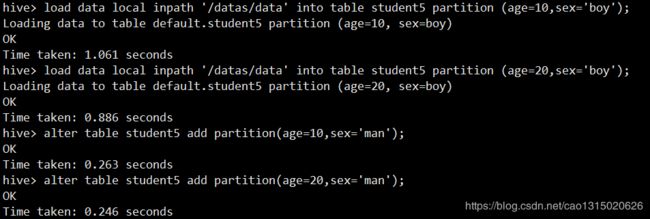
alter table student5 drop partition(sex='man')删除sex为man的分区

此时可以看见,由于age=10中含有两组数据,此时只会删除所有sex=man的那组数据,而不会把age=10删除,如果age=10中只有一组数据,那么age=10也将被删除。
这里注意,即使在partition中加入age=10,也只会删除一组数据,因为存在依赖,所以不会删除age=10,,但此时age=20中的sex=man没有被删除,所以这种方式是指定删除
对于分区的添加与删除:
- 添加分区的时候,必须在现有分区的基础之上添加,而且设定了分区,导入数据的时候一定要设定分区的值!
- 删除分区的时候,会将所有存在的分区都删除,这是指定了一个字段的时候,如果是组合字段的话,就会定位删除。否则就将删除所有的数据!
3.4 Hive表复制与数据的加载
从查询中获取信息插入到建立的表中:
FROM page_view_stg pvs -- 表名与别名 插入到另一张表,方式覆盖
INSERT OVERWRITE TABLE page_view PARTITION(dt='2008-06-08', country)
SELECT pvs.viewTime, pvs.userid, pvs.page_url, pvs.referrer_url, null, null, pvs.ip, pvs.cnt
如果各位在插入的过程中遇到如下的bug:
FAILED: Execution Error, return code 2 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask
MapReduce Jobs Launched:
Stage-Stage-1: Map: 1 HDFS Read: 0 HDFS Write: 0 FAIL
Total MapReduce CPU Time Spent: 0 msec

原因:主要是由于我们的内存分配不足:
[2019-09-29 17:51:22.365]Container [pid=6130,containerID=container_1569746591716_0008_01_000005] is running 254020096B beyond the ‘VIRTUAL’ memory limit. Current usage: 100.5 MB of 1 GB physical memory used; 2.3 GB of 2.1 GB virtual memory used. Killing container.
Dump of the process-tree for container_1569746591716_0008_01_000005 :
解决办法:
修改hadoop中的yarn-site.xml文件将所分配的内存提升到最大,或者比现阶段大即可。
<property>
<name>yarn.scheduler.maximum-allocation-mbname>
<value>8192value>
property>
<property>
<name>yarn.nodemanager.resource.memory-mbname>
<value>8192value>
property>
此时表复制成功:
FROM page_view_stg pvs -- 表名与别名 插入到另一张表,方式覆盖
INSERT OVERWRITE TABLE page_view PARTITION(dt='2008-06-08', country)
SELECT pvs.viewTime, pvs.userid, pvs.page_url, pvs.referrer_url, null, null, pvs.ip, pvs.cnt
作用:
- 复制表
- 可以作为中间表存在
- 可以分别对表做复制处理,如下:
FROM student8
INSERT OVERWRITE TABLE student10
SELECT id,name,hobby;
INSERT OVERWRITE TABLE student9
SELECT id,name,hobby,address;
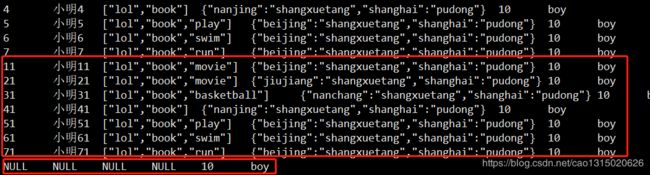
文件直接加载进入到data目录,对于数据来说查询表的话也会有数据显示:
hdfs dfs -put /a/data2 /user/hive/warehouse/student5/age=10/sex=boy/
在hive中select * from student5可以查询到通过hdfs文件系统添加的文件在表中呈现,如果格式错误的数据会显示为null展示数据。
3.5 Serde(Serializer&Deserializer )
- SerDe用于做序列化与反序列化
- 构建在数据存于与执行引擎之间,对两者实现解耦
- 在Hive中,Hive通过ROW FORMAT DELIMITED以及SERDE进行内容的读写
通过serde方式写入文件的语句:
CREATE TABLE logtbl(
host STRING,
identity STRING,
t_user STRING,
times STRING, // 注意这里的time,如果写的是time,我的hive报错说time不应该为string
request STRING,
referer STRING,
agent STRING
)
ROW FORMAT SERDE 'org.apache.hadoop.hive.serde2.RegexSerDe'
WITH SERDEPROPERTIES (
"input.regex" = "([^ ]*) ([^ ]*) ([^ ]*) \\[(.*)\\] \"(.*)\" (-|[0-9]*) (-|[0-9]*)"
)
STORED AS TEXTFILE;
输入的文本数据:上面sql中的regex的语句是利用正则表达式获取下面数据中的有用数据
192.168.57.4 - - [29/Feb/2016:18:14:35 +0800] "GET /bg-upper.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2016:18:14:35 +0800] "GET /bg-nav.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2016:18:14:35 +0800] "GET /asf-logo.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2016:18:14:35 +0800] "GET /bg-button.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2016:18:14:35 +0800] "GET /bg-middle.png HTTP/1.1" 304 -
192.168.57.4 - - [29/Feb/2016:18:14:36 +0800] "GET / HTTP/1.1" 200 11217
192.168.57.4 - - [29/Feb/2016:18:14:36 +0800] "GET / HTTP/1.1" 200 11217
3.6 Hive的Beeline启动方式
Beeline:
- Beeline要与hiveserver2配合来使用
- 服务端启动hiveserver2
hive --service hiveserver2 - 客户端启动beeline有两种方式连接到服务端的hive
beeline -u jdbc:hive2://node03:10000/default -n root- 先输入
beeline启动beeline,然后!connect jdbc:hive:hive2://node03:10000/default,输入完成会有一个校验过程,只需要填写用户名即可,密码随便填写,默认不做校验。
问题点:
- 当使用beeline的时候客户端使用此链接方式的时候会报错,User: root is not allowed to impersonate root,此时需要做的事情,是改变hdfs-site.xml与core-site.xml文件的配置:
hdfs-site.xml添加的配置:
<property>
<name>dfs.webhdfs.enabledname>
<value>truevalue>
property>
core-site.xml添加的配置:
<property>
<name>hadoop.proxyuser.root.hostsname>
<value>*value>
property>
<property>
<name>hadoop.proxyuser.root.groupsname>
<value>*value>
property>
修改配置之后,分发之后对于hadoop最好重启一下,确保配置文件生效,否则继续beeline会报一样的错,会浪费很多时间!
4. Hive函数
- 内置运算符
1.1 关系运算符(=、==、<>、<、<=、>、>=、A IS NULL、A IS NOT NULL、A LIKE B、A RLIKE B、A REGEXP B)
1.2 算数运算符(+、-、*、/、%、&、|、^、~)
1.3 逻辑运算符(AND、&&、OR、|、NOT、!)
1.4 复杂函数类型(map、struct、array)
1.5 对复杂函数类型进行操作(A[n]、M[key]、S.x(struct)) - 内置函数
2.1 数学函数(round(double a)、round(double a, int d)、floor(double a)、ceil(double a)、rand()、exp(double a)、ln(double a)、log10(double a)、log2(double a)、log(double base,double a)、pow(double a, double p)、sqrt(double a))
2.2 收集函数(size(Map
2.3 类型转换函数(cast(expr as ))
2.4 日期函数(unix_timestamp()、unix_timestamp(string date)、year(string date)、month(string date)、day(string date))
2.5 条件函数(if(boolean testCondition, T valueTrue, T valueFalseOrNull)、CASE a WHEN b THENc[WHEN d THEN e]*[ELSE f] END)
2.6 字符函数(length(string A)、reverse(string A)、concat(string A,string B)、trim(String A)) - 内置的聚合函数(UDAF)(count(*)、sum(col)、avg(col)、min(col)、max(col)…)
- 内置表生成函数(UDTF)(explode(array a)、json_tuple)
- 自定义函数:包含三种UDF、UDAF、UDTF
- UDF(User-Defined-Function)一进一出
- UDAF(User-Defined Aggreation Funcation)聚集函数,多进一出,count/max/avg
- UDTF(User-Defined Table-Generating Function)一进多出,lateral view explode()
自定义函数使用的方式:
在hive会话中add文件自定义函数的jar文件,然后创建function继而使用函数。
UDF开发:(自定义函数的编写)
直接上代码:需要继承UDF,现在这个类被废弃了,新的类是GenericUDF
pom.xml添加的依赖:
<dependency>
<groupId>org.apache.hivegroupId>
<artifactId>hive-execartifactId>
<version>3.1.2version>
dependency>
代码:
public class TuoMin extends UDF {
public Text evaluate(final Text s) {
if (s == null) {
return null;
}
String res = s.toString().substring(0, 3) + "*****";
return new Text(res);
}
}
打包的话:建议使用后maven的packge自动打包。否则很难被执行。
- 上传jar包到linux服务器上
- hive中
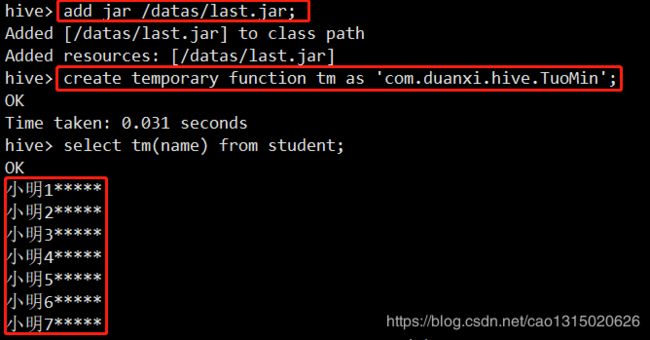
add jar /datas/TuoMin.jar在hive中添加jar包 create temporary function tm as 'com.duanxi.hive.TuoMin',构建临时的函数select tm(name) from student可以对查询出的数据进行一个脱敏处理:
4.1 Hive小练习
4.1.1 基站掉线率topN
给出数据集,求基站掉线率topN
数据集地址:
首先建表:
create table call_monitor(
dates string,
imei string,
cell string,
ph_num string,
call_num string,
drop_num int,
duration int,
drop_rate double,
net_type string,
erl string
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ',';
导入数据集load data local inpath '/datas/practice.csv' into call_monitor
数据集中有很多数据,但对于求解掉线率只需要掉线的次数,和此次通话持续的总长度即可。
创建结果集存储结果:
create table call_result(
imei string,
drop_num int,
duration int,
drop_rate double
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ',';
利用上面的数据表数据的插入使用sql语句先算出掉线率然后再插入数据表
FROM call_monitor cm
INSERT into TABLE call_result
select cm.imei,sum(cm.drop_num) drop_num,
sum(cm.duration) duration,sum(cm.drop_num)/sum(cm.duration) drop_rate
group by cm.imei order by drop_rate desc;
由于结果集数量很大,计算的时候很可能出现内存溢出的情况,具体可以参考下面博客:
解决Hive的beyond the ‘VIRTUAL’ memory limit

4.1.2 Hive的wordcount实现
实现Wordcount,跟之前在hadoop中写的一样,只是需要先数据分组,然后再做数据的统计分组计算。
数据集:
hello hadoop hive
world hadoop hive
caoduanxi hello
hello
hive
建立数据表:
create table wc(
word string
);
建立结果表:
create table wc_result(
word string,
count int
);
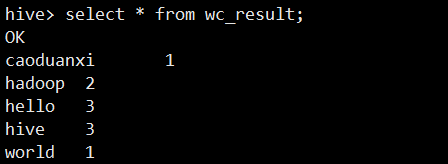
数据的插入:需要使用到explode与split函数,作为分割和数据的分行,作为表的数据插入
from (select explode(split(word,' '))word from wc) t1
insert into table wc_result
select t1.word as word, count(t1.word) as count group by t1.word;
最后结果展示:
5. Hive的参数设置与动态分区
Hive的参数设置:
- 在Hive中参数、变量都是以命名空间开头的:命名空间有四种
hiveconf、system、env、hivevar.
| 命名空间 | 读写权限 | 含义 |
|---|---|---|
| hiveconf | 可读写 | hive-site.xml当中的配置变量,例如:hive–hiveconf hive.cli.print.header-true |
| system | 可读写 | 系统变量,包括JVM运行参数等,例:system.user.name=root |
| env | 只读 | 环境变量,例:env:JAVA_HOME |
| hivevar | 可读写 | 例:hive -d val=key |
- 通过${}方式进行引用,其中system、env下的变量必须以前缀开头
5.1 Hive的参数设置
Hive的参数设置方式:
- 修改配置文件
$HIVE_HOME/conf/hive-site.xml - 在hive启动的时候,通过
--hiveconf key = value设置- 例如:
hive --hiveconf hive.cli.print.header=true
- 例如:
- 进入cli之后,使用set命令设置(正常的hive启动即可)
- 上面三种方式设置的参数当退出hive之后,都会还原为默认值,如果需要配置长时间不失效的参数,可以在
cd ~ 、 vi .hive.rc在rc文件中添加入设置的参数值,hive启动的时候会先去这里检查是否含有rc文件,如果有就加载,没有的话就使用默认的参数值。 - set命令有两种含义,对于参数的话,带上设置的value则为设置值,如果不带,那就是查询,此时可以看到此时当前查询的参数设置的值
5.3 Hive的动态分区
之前的分区都是静态的,必须设置好分区,而且分完区以后的数据都是在同一个目录下。加入了动态分区以后,可以动态的对数据实行一个分区,导入到不同的表格中。
数据集:注意,必须有分区字段区分度
1,小明1,10,man,lol-book-movie,beijing:shangxuetang-shanghai:pudong
2,小明2,10,man,lol-book-movie,jiujiang:shangxuetang-shanghai:pudong
3,小明3,20,man,lol-book-basketball,nanchang:shangxuetang-shanghai:pudong
4,小明4,20,boy,lol-book,nanjing:shangxuetang-shanghai:pudong
5,小明5,20,boy,lol-book-play,beijing:shangxuetang-shanghai:pudong
6,小明6,20,man,lol-book-swim,beijing:shangxuetang-shanghai:pudong
7,小明7,10,boy,lol-book-run,beijing:shangxuetang-shanghai:pudong
构建数据存储表:
create table partone(
id int,
name string,
age int,
sex string,
hobby Array<string>,
address MAP<string,string>
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY '-'
MAP KEYS TERMINATED BY ':'
LINES TERMINATED BY '\n';
构建结果存储表:
create table partresone(
id int,
name string,
hobby ARRAY<string>,
address MAP<string,string>
)
PARTITIONED BY (age int,sex string) -- 需要指明分区字段
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ','
COLLECTION ITEMS TERMINATED BY '-'
MAP KEYS TERMINATED BY ':'
LINES TERMINATED BY '\n';
结果导入:
有用到distribute by这个的主要作用是:
- hive中的distribute by是控制在map端如何拆分数据给reduce端的。
- hive会根据distribute by后面列,根据reduce的个数进行数据分发,默认是采用hash算法。
FROM partone
INSERT OVERWRITE table partresone partition(age,sex)
select id,name,hobby,address,age,sex distribute by age,sex;
6. Hive的分桶
Hive分桶:
- 分桶表示对列值取哈希值的方式,将不同的数据放到不同的文件中存储
- 对于hive中的每一个表、分区都可以进一步进行分桶
- 由列的哈希值除以桶的个数来决定每条数据划分在哪个桶里
适用场景:数据抽样(sampling)、map-join
官方文档:set hive.enforce.bucketing = true; – (Note: Not needed in Hive 2.x onward)
如果是2.x版本一下的hive,需要设置分桶为true,set hive.enforce.bucketing = true;
示例:数据集
1,tom,11
2,cat,22
3,dog,33
4,hive,44
5,hbase,55
6,mr,66
7,alice,77
8,scala,88
创建数据存储表:
create table bucket(
id int,
name string,
age int
)
row format DELIMITED
fields terminated by ',';
创建分桶数据表:注意这时候需要设定桶的数量
create table partitionbucket(
id int,
name string,
age int
)
clustered by(age) into 4 buckets
row format delimited
fields terminated by ',';
从bucket中导入数据到分桶表中:
insert into table partitionbucket select id,name,age from bucket;
此时由于按照年龄age来分桶,此时在hdfs文件系统中,会有四个文件分区:
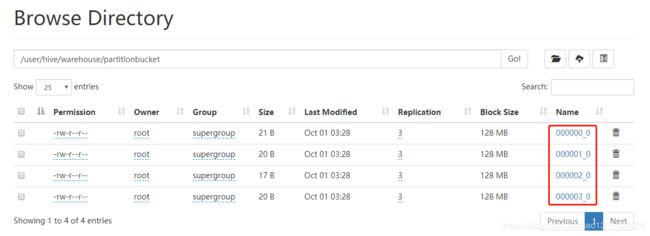
分桶的主要作用就是用于抽样数据:
select id,name,age from partitionbucket tablesample(bucket 2 out of 4 on age);
select id,name,age from partitionbucket tablesample(bucket x out of y on age);
其中的x表示从哪个桶开始取,y表示桶的因子或者倍数
例如上面的数据,表示4/4取一组数据,从2号桶开始。ps:这里自己有实践,但是出来的数据是第三个桶中的数据和第四个桶中的数据各有一条。-_-||

7. Hive视图&索引
7.1 Hive Lateral View
hive lateral view:
- Lateral View用于和UDTF函数(explode、split)结合来使用
- 通过UDTF函数拆分成多行,再将多行的结果组合成一个支持别名的虚拟表
- 主要的作用是解决select使用UDTF在查询过程中,查询只能包含单个UDTF,不能包含其他的字段、 以及多个UDTF的问题( UDTF(User-Defined Table-Generating Function)一进多出,lateral view explore() )
lateral view的主要作用就是配合explode查询出分解表中的数据,例如从student中explode可以查询出,所有学生爱好的总数,explode可以查询出所有的地址个数,但是如何将他们放在一张表中显示呢,这个时候就需要lateral view起作用构建一个虚拟的视图表
实现:
select count(distinct(col1)),count(distinct(col2)) from student
lateral view explode(hobby) student as col1
-- address中由于是map的数据集,explode会解析为两列数据,但是计算的话只需要取一列即可
lateral view explode(address) studetn as col2,col3
输出的数据:

7.2 Hive的视图
摘自百度百科:
视图是指计算机数据库中的视图,是一个虚拟表,其内容由查询定义。同真实的表一样,视图包含一系列带有名称的列和行数据。但是,视图并不在数据库中以存储的数据值集形式存在。行和列数据来自由定义视图的查询所引用的表,并且在引用视图时动态生成。
视图我们可以创建,但是不能平白无故的建立一个视图,因为视图看上面的释义知道是基于我们所查询的数据来的,如果我们没有查询数据,那么要视图干什么????
视图建立的语句:官网
CREATE VIEW [IF NOT EXISTS] [db_name.]view_name [(column_name [COMMENT column_comment], ...) ]
[COMMENT view_comment]
[TBLPROPERTIES (property_name = property_value, ...)]
AS SELECT ...;
示例:
create view one_view(
id,
name
)
as select id,name from student;
此时在navicat中可以看见:

此时查询出视图展示:注意没有单独视图展示show views; ,show tables可以看见视图,因为视图本质是表。注意,在hdfs文件系统上是不会有视图的!!一切只因为它是虚拟的。

删除视图:drop view one_view;
7.3 Hive的索引
Hive索引:
- 目的:优化查询以及检索性能
- 创建索引:由于我自己安装的是3.1.2也就是3.x版本,索引被移除了,导致只要创建索引就会报错
FAILED: ParseException line 1:7 cannot recognize input near 'CREATE' 'INDEX' 'stu_idx' in ddl statement

- 如果是2.x版本还是可以使用索引的:
CREATE INDEX stu_idx
on table student(name)
as 'org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler'
with deferred rebuild
in table one_idx_table;
-----------------------------
-- 不指定表名会生成默认的表名
create index t2_index on table student(name)
as 'org.apache.hadoop.hive.ql.index.compact.CompactIndexHandler' with deferred rebuild;
-- 索引的展示
show index on student;
-- 重建索引(建立索引之后必须重建索引才能生效)
ALTER INDEX t1_index ON psn2 REBUILD;
-- 删除索引
DROP INDEX IF EXISTS t1_index ON psn2;
具体索引的例子这里就不做介绍了。
8. Hive的运行方式
Hive的运行方式:
- 命令行方式cli:控制台模式
- 脚本运行方式(实际生产环境中用的最多)
- JDBC方式(hiveserver2)
- web GUI接口(hwi等)
8.1 命令行方式
与hdfs的交互:
dfs -ls /展示hdfs根目录
与linux的交互:
!pwd
8.2 脚本运行方式
hive -e "select * from student"其中-e表示exec,执行脚本,与我们hive直接进入客户端是会产生一样效果。hive -e "select * from student" > aaa表示hive执行脚本之后的内容重定向到aaa文件中hive -S -e "select * from student" > bbb其中-S表示静默执行,此时输出控制台不会有任何的执行语句输出,表示静默。hive -f file表示执行文件中事先编写好的sql语句hive -i file表示执行文件中编写的sql语句,然后进入到hive控制台source file表示在hive中执行linux文件系统中的文件中的sql语句(这是在hive的控制台中执行的,即hive cli)
8.3 JDBC运行方式
在之前的执行中介绍过hiveserver2,这里的jdbc运行方式就是采用的hiveserver2+beeline的启动方式:
服务端node03:hive --service hiveserver2
客户端node04:beelne -u jdbc:hive2//node03:10000/default -n root,即可启动,后续的操作与hive cli类似,不过beeline的控制台的输出会和mysql的客户端执行一样,使用的是表结构的数据。
8.4 Web GUI接口hwi
这个组件在2.2版本被移除了
它的本质就是帮助那些不会使用hive的人提供一个可视化的界面,只要他们懂得基本的sql命令即可实现数据分析的功能。

9. Hive权限管理
Hive权限管理:
- 三种授权模型
- Storage Based Authorization in the Metastore Server (基于存储的授权),可以对metastore中的元数据进行保护,但是没有提供更加细粒度的访问控制(例如:列级别,行级别)。
- SQL Standard Based Authorization in Hiveserver2,基于SQL标准的hive授权,完全兼容的SQL授权模型,推荐使用该模式
- Default Hive Authorization (Legacy Mode) hive默认授权,设计目的仅仅是防止用户产生误操作,而不是防止恶意用户访问未经授权的数据
9.1 SQL Standards Based Authorization in HiveServer2
- 完全兼容SQL的授权模型
- 除了支持用户的授权认证,还支持角色role的授权认证
- role可以理解为是一组权限的集合,通过role对角色进行授权
- 一个用户可以具有一个或者多个角色
- 默认包含的其他角色:public admid
- 限制:
- 启动当前认证之后,dfs,add,delete,compile,and reset等命令被禁用
- 通过set命令设置hive configuration的方式被限制某些用户使用,可以通过修改配置文件hive-site.xml中的hive.security.authorization.sqlstd.confwhitelist进行设置
- 添加、删除函数以及宏的操作,仅为具有admin的用户开放
- 用户自定义函数(开放支持永久的自定义函数),可通过具有admin的角色创建,其他用户可以直接使用
- Transform功能被禁用
具体权限管理的实现:
第一步:在hive服务端修改配置文件hive-site.xml添加一下配置内容
<property>
<name>hive.security.authorization.enabledname>
<value>truevalue>
property>
<property>
<name>hive.server2.enable.doAsname>
<value>falsevalue>
property>
<property>
<name>hive.users.in.admin.rolename>
<value>rootvalue>
property>
<property>
<name>hive.security.authorization.managername>
<value>org.apache.hadoop.hive.ql.security.authorization.plugin.sqlstd.SQLStdHiveAuthorizerFactoryvalue>
property>
<property>
<name>hive.security.authenticator.managername>
<value>org.apache.hadoop.hive.ql.security.SessionStateUserAuthenticatorvalue>
property>
第二步:服务端启动hiveserver2,客户端启动beline(beeline -u jdbc:hive2://node03:10000/default -n root)
角色权限:
- CREATE ROLE role_name; – 创建角色
- DROP ROLE role_name; – 删除角色
- SET ROLE (role_name|ALL|NONE); – 设置角色
- SHOW CURRENT ROLES; – 查看当前具有的角色
- SHOW ROLES; – 查看所有存在的角色
-- 将角色授予某个用户、角色
GRANT role_name [, role_name] ...
TO principal_specification [, principal_specification] ...
[ WITH ADMIN OPTION ];
principal_specification
: USER user
| ROLE role
-- 移除某个用户、角色的角色
REVOKE [ADMIN OPTION FOR] role_name [, role_name] ...
FROM principal_specification [, principal_specification] ... ;
principal_specification
: USER user
| ROLE role
-- 查看授予某个用户、角色的角色列表
SHOW ROLE GRANT (USER|ROLE) principal_name;
-- 查看属于某种角色的用户、角色列表
SHOW PRINCIPALS role_name;
具体实践:
create role test创建test角色
grant test to role public,将test角色授予public角色(注意需要选定role角色,如果是用户使用user)
查看与移除类似,注意需要选定角色或者用户,否则执行不了!
Hive的权限管理的权限:
- SELECT privilege – gives read access to an object.
- INSERT privilege – gives ability to add data to an object (table).
- UPDATE privilege – gives ability to run update queries on an object (table).
- DELETE privilege – gives ability to delete data in an object (table).
- ALL PRIVILEGES – gives all privileges (gets translated into all the above privileges).
权限的授予、移除、查看:
-- 将权限授予某个用户、角色:
GRANT
priv_type [, priv_type ] ...
ON table_or_view_name
TO principal_specification [, principal_specification] ...
[WITH GRANT OPTION];
principal_specification
: USER user
| ROLE role
priv_type
: INSERT | SELECT | UPDATE | DELETE | ALL
-- 移除某个用户、角色的权限
REVOKE [GRANT OPTION FOR]
priv_type [, priv_type ] ...
ON table_or_view_name
FROM principal_specification [, principal_specification] ... ;
-- 查看某个用户、角色的权限
SHOW GRANT [principal_name] ON (ALL| ([TABLE] table_or_view_name)
实践:给test赋予表table的查询的权限,并查看其的权限
create role test创建角色grant select on student to role test给test赋予student表查询的权限show grant role test on student查看角色test在表student中的权限

10. Hive的优化
10.1 Hive优化的简介&EXPLAIN
Hive的优化:
- 核心思想:把Hive SQL当做MapReduce程序去优化
- 以下SQL不会转化为MapReduce程序去执行
- select仅查询本表字段
- where仅对本表字段做过滤
- Explain显示执行计划(会解释输出语句执行的流程,下面的三部分)
- EXPLAIN [EXTENDED] query
- 抽象的语法树
- 计划执行的不同阶段所需要的不同依赖
- 每一个阶段的描述
10.2 Hive运行方式的优化
Hive的运行方式分为两种:
- 本地模式
- 集群模式
集群模式,基本采用的都是集群模式,耗时比较久,一般本地测试可以采用本地模式,这样的执行效率比较高,但是本地模式的执行需要注意如果文件的大小超过128M,还是会采取集群的方式运行。
本地模式运行:
- 开启本地模式
set hive.exec.mode.local.auto=true;默认为false
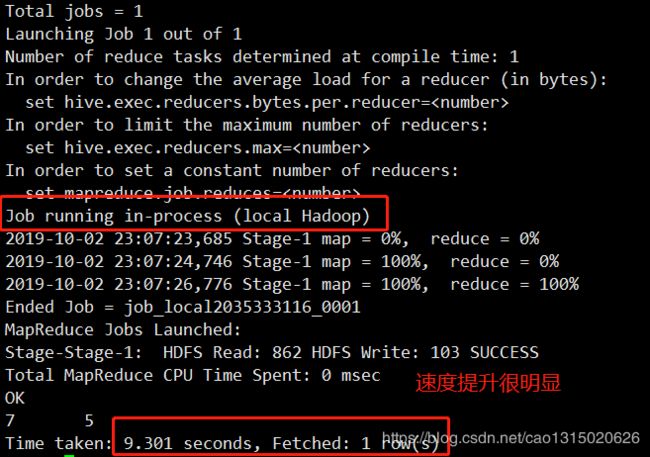
- 对于文件大小超过128M,仍旧会以集群的方式运行,128是默认值,可以自己根据业务需求来设定大小,
set hive.exec.mode.local.auto.inputbytes.max=value可以设定
10.3 并行计算
当执行的sql有几个任务的查询,而这些任务又可以通过并行执行,此时可以开启hive的并行执行
set hive.exec.parallel=true;设置参数开启并行计算
set hive.exec.parallel.thread.number可以设置并集计算job的个数的最大值
注意,设置并行开启的前提是hive执行的SQL命令支持并行,否则也是不能得到优化的,并行计算的个数,也需要根据sql的分析来设定,不是一味的大就有用的。
10.4 严格模式
设置了严格模式,由于校验的规则更加的严格,从而增大了时间的损耗,造成hive运行时间长,从这里可以得到优化,设置为非严格模式。
set hive.mapred.mode=strict,设置为严格模式
set hive.mapred.mode=nonstrict,设置为非严格模式
注意,设置了严格模式以后,查询需要遵循以下几条限制:
- 对于分区表,必须添加where对于分区字段的过滤
- order by语句必须包含limit语句输出限制
- 限制执行笛卡尔积的查询
10.5 Hive排序
Hive的排序:
- Order By:对于查询的结果做全排序,只允许有一个reduce来处理(当数据量较大时,应该慎用;严格模式下,应该结合limit使用)
- Sort By:对于单个reduce的数据进行排序
- Distribute By:分区排序,进场和Sort By结合使用
- Cluster By:相当于Sort By + Distribute By来使用,注意:Cluster By不能通过asc/desc的方式执行排序规则,默认倒序排列,但是可以使用
distribute by column sort by column asc|desc
10.6 Hive Join
Hive Join:
- Join计算时,将小表(驱动表)放在join的左边(10*1000比1000*10的复杂度要小)
- Map join:在map端执行join操作,节省在reduce方法中执行join的时间
- 1 SQL方式,在SQL语句中添加MapJoin标记(Mapjoin hint)
- 语法:
- SELECT /*+ MAPJOIN(smallTable) */ smallTable.key, bigTable.value
FROM smallTable JOIN bigTable ON smallTable.key = bigTable.key; - 2 开启自动的MapJoin
开启自动的MapJoin,自动的MapJoin,通过修改一下配置启用自动的mapjoin:
set hive.auto.convert.join=true,设置的该参数为true时,hive自动对左边的表统计量,如果是小表就加入内存,表名对小表做Mapjoin操作
相关参数配置:
hive.mapjoin.smalltable.filesize;- (大表小表判断的阈值,如果表的大小小于该值则会被加载到内存中运行)
hive.ignore.mapjoin.hint;- (默认值:true;是否忽略mapjoin hint 即mapjoin标记)
hive.auto.convert.join.noconditionaltask;- (默认值:true;将普通的join转化为普通的mapjoin时,是否将多个mapjoin转化为一个mapjoin)
hive.auto.convert.join.noconditionaltask.size;- (将多个mapjoin转化为一个mapjoin时,其表的最大值)
10.7 Map-Side聚合
Map-Side聚合:
通过设置以下的参数开启Map-Side聚合:set hive.map.aggr=true;
相关参数设置:
hive.groupby.mapaggr.checkinterval:- map端group by执行聚合时处理的多少行数据(默认:100000)
hive.map.aggr.hash.min.reduction:- 进行聚合的最小比例(预先对100000条数据做聚合,若聚合之后的数据量/100000的值大于该配置0.5,则不会聚合)
hive.map.aggr.hash.percentmemory:- map端聚合使用的内存的最大值
hive.map.aggr.hash.force.flush.memory.threshold:- map端做聚合操作是hash表的最大可用内容,大于该值则会触发flush
hive.groupby.skewindata- 是否对GroupBy产生的数据倾斜做优化,默认为false
上述参数的设置都需要根据业务的需求来定
10.8 控制Hive中的Map和Reduce数量
Map数量控制需要设置的相应的参数:
mapred.max.split.size- 一个split的最大值,即每个map处理文件的最大值,split与map之间1:1关系
mapred.min.split.size.per.node- 一个节点上split的最小值
mapred.min.split.size.per.rack- 一个机架上split的最小值
Reduce数量控制需要设置的相应的参数:
mapred.reduce.tasks- 强制指定reduce任务的数量
hive.exec.reducers.bytes.per.reducer- 每个reduce任务处理的数据量
hive.exec.reducers.max- 每个任务最大的reduce数
10.9 JVM重用
JVM重用:
Hadoop的默认配置通常是使用派生JVM来执行map和Reduce任务的。这时JVM的启动过程可能会造成相当大的开销,尤其是执行的job包含有成百上千task任务的情况。JVM重用可以使得JVM实例在同一个job中重新使用N次
- 适用场景:1.小文件个数过多 2.task个数过多
- 通过
set mapred.job.reuse.jvm.num.tasks=n来设置,n表示task插槽个数 - 缺点:设置开启之后,task插槽会一直占用资源,不论是否有task运行,直到所有的task即整个job全部执行完成时,才是释放所有的task插槽资源
11. 小结
本次hive的学习基本学习了关于hive的所以知识,其中设计到hive的简介,hive简而言之就是一个仓库,储存着元数据信息,元数据存储在关系型数据库中,hive每次运行时都需要hive --service metastore与关系型数据库之间实现元数据的同步,hive由于存在关系型数据库中,还学习了mysql的安装与具体的配置,安装yum install mysql-server即可安装,注意,service myslqd start是开启mysql服务。学习了hive的单用户的搭建,以及多用户的搭建,远程分离,真实的生产环境,都是多用户模式的远程分离形式。学习了Hive的sql语句,基本与mysql的一致,不过Hive由于数据类型的问题,除了含有基本的数据类型,还加入了数组,map,以及struct数据类型。Hive表的创建与删除,数据的序列化与反序列化,分区,动态分区,分桶实现数据的不同目录下的存储。学习了hive的各种函数,其中自定义函数的编写需要打包成jar包,在hive下运行,还有通过基站掉话率和wordcount的练习,学习了explode函数的使用方法,对hive的sql使用进一步加深。学习了Hive的lateral view主要是合并表的数据并展示出来,以及hive的视图,虚拟表,索引,提升查询的效率,但在3.x版本以后索引被移除了。学习了Hive的四种执行方式,命令行方式,脚本运行方式,JDBC运行方式以及WEB GUI接口运行方式(也被移除了)。学习了Hive的权限管理,对于Hive角色的创建,权限的分配移除查看。最后就是Hive的优化,Hive的优化部分,核心思想:把Hive SQL当做MapReduce程序来优化,其中优化部分包含:EXPLAIN查看语句执行计划,Hive运行方式的优化,开启并行计算的优化,严格模式与非严格模式切换的优化,Hive排序的优化,针对于各种排序的使用规则,加入业务需求考虑得出相对优化的排序规则,Hive的join优化策略,在map端做join操作,优化reduce处理阶段的join。Map-side的聚合操作,一般适用于大量的业务数据重复的情况,可解决数据倾斜问题,以及最后的控制Hive中的Map和Reduce的数量来使得sql语句执行的更加有效率,最后就是针对小文件个数过多或者task个数过多的情况,可以通过jvm重用的优化,来使得jvm重复执行,从而提高执行的效率,但是jvm重用也有其缺点,就是tasks插槽会一直被占用,除非全部执行完毕。
Hive学习知识如上,还是要多实践,多看知识,大数据学习加油!