Springboot2(51)集成jpa
源码地址
springboot2教程系列
Spring Data JPA 与 MyBatis简单对比
Spring Data JPA是Spring Data的子模块。使用Spring Data,使得基于“repositories”概念的JPA实现更简单和容易。Spring Data JPA的目标是大大简化数据访问层代码的编码。作为使用者,我们只需要编写自己的repository接口,接口中包含一些个性化的查询方法,Spring Data JPA将自动实现查询方法。
JPA默认使用hibernate作为ORM实现,所以,一般使用Spring Data JPA即会使用hibernate。我们再看看hibernate的官方概念,Hibernate是一个开放源代码的对象关系映射框架,它对JDBC进行了非常轻量级的对象封装,它将POJO与数据库表建立映射关系,是一个全自动的orm框架,hibernate可以自动生成SQL语句,自动执行,使得Java程序员可以随心所欲的使用对象编程思维来操纵数据库。
MyBatis 是一款优秀的持久层框架,它支持定制化 SQL、存储过程以及高级映射。MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取结果集。MyBatis 可以使用简单的 XML 或注解来配置和映射原生信息,将接口和 Java 的 POJOs(Plain Old Java Objects,普通的 Java对象)映射成数据库中的记录。
这样看,Spring Data JPA与MyBatis对比,起始也就是hibernate与MyBatis对比。所以,我们直接来比较后两者。
从基本概念和框架目标上看,两个框架差别还是很大的。hibernate是一个自动化更强、更高级的框架,毕竟在java代码层面上,省去了绝大部分sql编写,取而代之的是用面向对象的方式操作关系型数据库的数据。而MyBatis则是一个能够灵活编写sql语句,并将sql的入参和查询结果映射成POJOs的一个持久层框架。所以,从表面上看,hibernate能方便、自动化更强,而MyBatis 在Sql语句编写方面则更灵活自由。
但这只是从使用层面上看两者的区别,并未涉及的本质。但如果看问题,值看浅层次、表象问题的话,就不能理解技术本质,也不能发挥技术的最多效用。所以,如果更上一个抽象层次去看,对于数据的操作,hibernate是面向对象的,而MyBatis是面向关系的。当然,用hibernate也可以写出面向关系代码和系统,但却得不到面向关系的各种好处,最大的便是编写sql的灵活性,同时也失去面向对象意义和好处——一句话,不伦不类。那么,面向对象和关系型模型有什么不同,体现在哪里呢?实际上两者要面对的领域和要解决的问题是根本不同的:面向对象致力于解决计算机逻辑问题,而关系模型致力于解决数据的高效存取问题。我们不妨对比一下面向对象的概念原则和关系型数据库的不同之处:
- 面向对象考虑的是对象的整个生命周期包括在对象的创建、持久化、状态的改变和行为等,对象的持久化只是对象的一种状态,而面向关系型数据库的概念则更关注数据的高效存储和读取;
- 面向对象更强调对象状态的封装性,对象封装自己的状态(或数据)不允许外部对象随意修改,只暴露一些合法的行为方法供外部对象调用;而关系型数据库则是开放的,可以供用户随意读取和修改关系,并可以和其他表任意的关联(只要sql正确允许的情况下);
- 面向对象试图为动态的世界建模,他要描述的是世界的过程和规律,进而适应发展和变化,面向对象总是在变化中处理各种各样的变化。而关系型模型为静态世界建模,它通过数据快照记录了世界在某一时候的状态,它是静态的。
从上面两者基本概念和思想的对比来看,可以得出结论hibernate和MyBatis两个框架的侧重点完全不同。所以我们就两个框架选择上,就需要根据不同的项目需求选择不同的框架。在框架的使用中,也要考虑考虑框架的优势和劣势,扬长避短,发挥出框架的最大效用,才能真正的提高项目研发效率、完成项目的目标。但相反,如果使用Spring Data JPA和hibernate等ORM的框架而没有以面向对象思想和方法去分析和设计系统,而是抱怨框架不能灵活操作sql查询数据,那就是想让狗去帮你拿耗子了。
那么,话题再说回来,使用两个框架时候的时候,也要注意最佳的步骤和流程。下面我们来分别讨论一下,hibernate的一般使用步骤如下:
- 分析、抽象和归纳出系统中的业务概念,并梳理出各个业务概念之间的关系——创建概念模型
- 根据概念模型,进一步细化设计系统中的对象类以及类的依赖关系——创建设计模型
- 将设计好的类映射到数据库的表和字段配置好
- hibernate可以根据配置信息自动生成数据库表,这个时候也可以集中精力去梳理一下表关系,看看表结构是否合理,并适当调整一下类和表的映射关系,重新生成表结构
完成以上步骤,基本上完成了体统中主要的业务概念类和表结构的设计工作,只是完成表结构设计的出发点事如何持久化系统的对象,同时兼顾数据库表、字段、字段类型、表的关联关系的合理性和合规性,而不是单纯表设计。这两者思考和关注点还是有很大差别的。另外,需要说明一点,这只是使用hibernate的最通用步骤,实际操作过程中还是需要根据具体项目情况来安排。
而MyBatis对于面向对象的概念强调比较少,更适用于灵活的对数据进行增、删、改、查,所以在系统分析和设计过程中,要最大的发挥MyBatis的效用的话,一般使用步骤则与hibernate有所区别:
- 综合整个系统分析出系统需要存储的数据项目,并画出E-R关系图,设计表结构
- 根据上一步设计的表结构,创建数据库、表
- 编写MyBatis的SQL 映射文件、Pojos以及数据库操作对应的接口方法
这样看来MyBatis更适合于面向关系(或面向数据、或面向过程)的系统设计方法,这样的系统一般称为“事务脚步”系统(事务脚步(Transaction Script) 出自Martin Fowler 2004年所著的企业应用架构模式(Patterns of Enterprise Application Architecture))。而hibernate(也可以说Spring Data JPA)更适合于构建领域模型类的系统。当然,我们也不能说MyBatis无法构建领域模型驱动的系统,而hibernate无法构建事务脚步系统。只是用MyBatis构建领域模型要做更多、更脏、更累的工作;而用hibernate构建一个事务脚本系统有些大材小用,数据的查询反而没那么灵活。
综合上面所有描述和对比,我们对这两个框架的本质区别应该有所了解了。我们了解了这些区别,可以帮助我们选择更合适的框架,同时,也可以利用不同的框架,让他们去做更合适事,这也是所谓的物尽其用吧,更不至于我们“为物所役”。
引入依赖
org.springframework.boot
spring-boot-starter-data-jpa
添加配置
spring:
messages:
basename: i18n/Messages,i18n/Pages
datasource:
type: com.alibaba.druid.pool.DruidDataSource # 配置当前要使用的数据源的操作类型
driver-class-name: org.gjt.mm.mysql.Driver # 配置MySQL的驱动程序类
url: jdbc:mysql://47.106.106.53:3306/mybatis?allowMultiQueries=true&useUnicode=true&characterEncoding=UTF-8 # 数据库连接地址
username: root # 数据库用户名
password: Rojao@123
# JPA 相关配置
spring.jpa.database-platform: org.hibernate.dialect.MySQL5InnoDBDialect
spring.jpa.database: mysql
# 显示后台处理的SQL语句
spring.jpa.show-sql: true
# 自动检查实体和数据库表是否一致,如果不一致则会进行更新数据库表
spring.jpa.hibernate.ddl-auto: create
spring.jpa.show-sql=true 配置在日志中打印出执行的 SQL 语句信息。
spring.jpa.hibernate.ddl-auto=create 配置指明在程序启动的时候要删除并且创建实体类对应的表。这个参数很危险,因为他会把对应的表删除掉然后重建。所以千万不要在生成环境中使用。只有在测试环境中,一开始初始化数据库结构的时候才能使用一次。
-
create:每次加载hibernate时都会删除上一次的生成的表,然后根据你的model类再重新来生成新表,哪怕两次没有任何改变也要这样执行,这就是导致数据库表数据丢失的一个重要原因(一般只会在第一次创建时使用)
-
create-drop:每次加载hibernate时根据model类生成表,但是sessionFactory一关闭,表就自动删除
-
update:最常用的属性,第一次加载hibernate时根据model类会自动建立起表的结构(前提是先建立好数据库),以后加载hibernate时根据model类自动更新表结构,即使表结构改变了但表中的行仍然存在不会删除以前的行。要注意的是当部署到服务器后,表结构是不会被马上建立起来的,是要等应用第一次运行起来后才会
-
validate:每次加载hibernate时,验证创建数据库表结构,只会和数据库中的表进行比较,不会创建新表,但是会插入新值
spring.jpa.database-platform=org.hibernate.dialect.MySQL5InnoDBDialect 。在 SrpingBoot 2.0 版本中,Hibernate 创建数据表的时候,默认的数据库存储引擎选择的是 MyISAM (之前好像是 InnoDB,这点比较诡异)。这个参数是在建表的时候,将默认的存储引擎切换为 InnoDB 用的。
建立第一个数据实体类
@Data
@Entity
@Table(name = "bus_receiver")
public class BusReceiverEntity {
//主键
@Id
@Column(name="id")
private Long id;
//姓名
@Column(name="name",length = 32)
private String name;
//区域
@Column(name="region_code")
private String regionCode;
//地址
@Column(name="address")
private String address;
//地址英文名字
@Column(name="enname")
private String enName;
//家庭成员
@Column(name="memberfamily")
private int memberFamily;
//创建时间
@Column(name="create_date")
private Date createDate;
}
其中:
- @Entity 是一个必选的注解,声明这个类对应了一个数据库表。
- @Table(name = “region_code”) 是一个可选的注解。声明了数据库实体对应的表信息。包括表名称、索引信息等。这里声明这个实体类对应的表名是 AUTH_USER。如果没有指定,则表名和实体的名称保持一致。
- @Id 注解声明了实体唯一标识对应的属性。
- @Column(length = 32) 用来声明实体属性的表字段的定义。默认的实体每个属性都对应了表的一个字段。字段的名称默认和属性名称保持一致(并不一定相等)。字段的类型根据实体属性类型自动推断。这里主要是声明了字符字段的长度。如果不这么声明,则系统会采用 255 作为该字段的长度
* 常用注解解释:
* @Entity 用来标示这个类是实体类
* @Table 实体类与数据表的映射,通过name确定在表名(默认类名为表名)
* @Id 主键注解,表示该字段为主键
* @GeneratedValue 定义主键规则,默认AUTO
* @Column 类属性与表字段映射注解,其中可以设置在字段名,长度等信息
* @ManyToOne 多对一,可以设置数据加载方式等 默认加载方式是EAGER 就是使用left join
* @OneToMany 一对多 默认加载方式是 LAZY 懒加载
* @JoinColumn 与*对*配合使用,用来设置外键名等信息
* @Basic 实体类中会默认为每一个属性加上这个注解,表示与数据表存在关联,
* 没有使用Column注解的类属性会以属性名作为字段名,驼峰命名需要转为_
* @Temporal 对于Date属性的格式化注解,有 TIME,DATE,TIMESTAMP 几个选择
* @Transient 若存在不想与数据表映射的属性,则需要加上该注解
实现一个持久层服务
在 Spring Data JPA 的世界里,实现一个持久层的服务是一个非常简单的事情。以上面的 UserDO 实体对象为例,我们要实现一个增加、删除、修改、查询功能的持久层服务,那么我只需要声明一个接口,这个接口继承
org.springframework.data.repository.Repository
然后再简单的在这个接口上增加一个 @Repository 注解就结束了。
@Repository
public interface BusReceiverDao extends JpaRepository<BusReceiverEntity,Long> {
}
已经拥有下下面的功能

Dao 保存实体功能

Dao 保存实体删除功能

Dao 查询实体功能
该Dao成继承了JpaRepository接口,指定了需要操作的实体对象和实体对象的主键类型,通过查看JpaRepository接口源码可以看到,里面已经封装了创建(save)、更新(save)、删除(delete)、查询(findAll、findOne)等基本操作的函数,使用起来非常方便了,但是还是会存在一些复杂的sql,spring-data-jpa还提供了一个非常方便的方式,通过实体属性来命名方法,它会根据命名来创建sql查询相关数据,对应更加复杂的语句,还可以用直接写sql来完成,具体例子如上所示。
根据属性来查询
根据属性来查询
如果想要根据实体的某个属性来进行查询我们可以在 Dao 接口中进行接口声明。例如,如果我们想根据实体的 name 这个属性来进行查询,只需要
BusReceiverEntity findByName(String name);
这种方式非常强大,不经能够支持单个属性,还能支持多个属性组合。例如如果我们想查找账号和密码同时满足查询条件的接口。那么我们在 Dao 接口中声明
BusReceiverEntity findByNameAndAddress(String name,String address);
这个语句结构可以用下面的表来说明
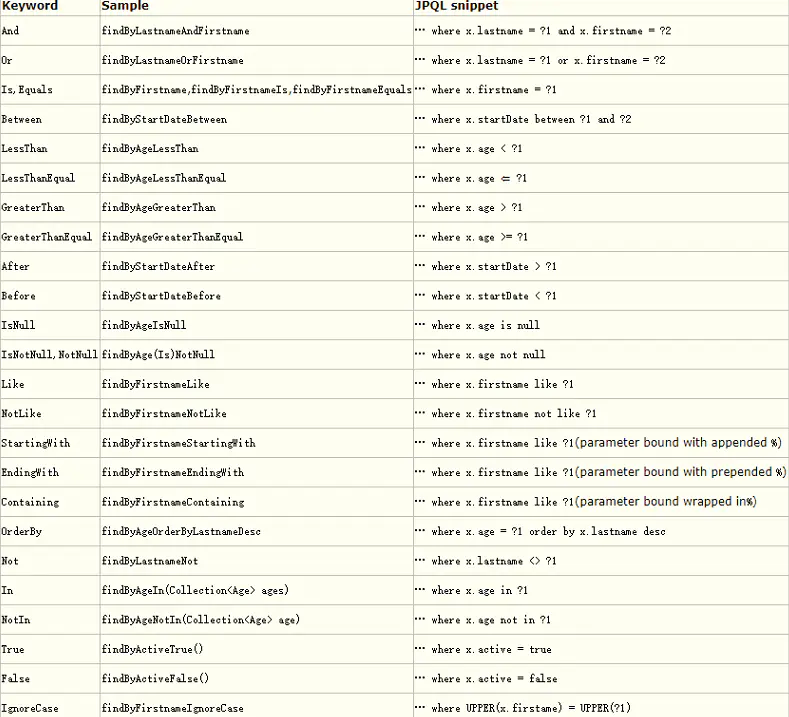
自定义查询
如果上述的情况还无法满足需要。那么我们就可以通过通过 import org.springframework.data.jpa.repository.Query注解来解决这个问题。
@Query("SELECT r FROM BusReceiverEntity r where r.name = ?1")
BusReceiverEntity findByName(String name);*/
这里是用 PQL 的语法来定义一个查询。 (注意是HQL,不是SQL语句)
如果你习惯编写 SQL 语句来完成查询,还可以在用下面的方式实现
@Query(nativeQuery = true, value = "SELECT * FROM AUTH_USER WHERE name = :name1 OR name = :name2 ")
List<UserDO> findSQL(@Param("name1") String name1, @Param("name2") String name2);
这里在 @Query 注解中增加一个 nativeQuery = true 的属性,就可以采用原生 SQL 语句的方式来编写查询。
(
@Param注解注入参数,:引入参数,需要指定参数名)
修改语句的自定义使用
@Query和@Modifying同时使用用来自定义数据更改操作的SQL,@Transactional负责提交事务
@Transactional
@Query(value = "update BusReceiverEntity p set p.name = ?1")
@Modifying
Integer updateName(String name);
添加二级缓存
引入依赖
org.springframework.boot
spring-boot-starter-cache
org.hibernate
hibernate-jcache
5.4.3.Final
org.ehcache
ehcache
3.5.2
此处需要注意,如果高版本的 SpringBoot,我们需要使用org.hibernate:hibernate-jcache,而不是org.hibernate:hibernate-ehcache。否则启动异常
配置
ehcache配置
这里需要注意的是,百度里面的文章大部分都是告诉大家怎么配置ehcache2.x,但是ehcache的2.x和3.x完全就两码事情了 ,这里使用ehcache3.x配置
600
2000
100
1
24
SpringBoot配置
#开启二级缓存
spring.jpa.properties.hibernate.cache.use_second_level_cache: true
spring.jpa.properties.cache.use_query_cache: true
spring.jpa.properties.cache.provider_configuration_file_resource_path: ehcache.xml
#指定缓存provider
spring.jpa.properties.hibernate.cache.region.factory_class: org.hibernate.cache.jcache.internal.JCacheRegionFactory
spring.jpa.open-in-view: false
spring.jpa.properties.javax.persistence.sharedCache.mode: ENABLE_SELECTIVE
启用注解
@SpringBootApplication
@EnableCaching
public class JpaApplication {
public static void main(String[] args){
SpringApplication app = new SpringApplication(JpaApplication.class);
// app.setWebEnvironment(false);
app.run(args);
}
}
应用缓存
@Entity
@Table(name = "bus_receiver")
@Cacheable
@Cache(usage = CacheConcurrencyStrategy.READ_WRITE)
public class BusReceiverEntity {
....
}
在使用 jpa 的 findById方法进行查询和 save进行更新数据的时候,hibernate 就会使用到缓存了 .
根据属性来查询是不使用缓存