跨版本迁移旧集群到新集群(hadoop2.2移到hadoop2.8),遇到无数问题,历时三周,终于圆满结束,总结如下:
一. 搭建新集群
新集群用了5台实体机,分别安装zookeeper、hadoop、hbase等。机器的ip尾号分别是16、17、18、19、20,所以下面的文字,用这几个数字代表这几台机器。参考帖子如下,建议下面两个链接的帖子都看完,再开始动手搭建自己的集群环境:
下载安装包,配置集群机器互相免密登录,zookeeper、hadoop、hbase启动前的配置,此帖子不错:https://blog.csdn.net/qazwsxpcm/article/details/78937820
查看启动顺序配置,此帖子不错:https://blog.csdn.net/u011414200/article/details/50437356#%E4%B8%89-%E5%BC%80%E5%90%AF%E4%B8%8E%E5%85%B3%E9%97%AD%E9%9B%86%E7%BE%A4%E9%A1%BA%E5%BA%8F
过程中遇到各种问题,所以把集群停止启动多次,总结 用到的命令如下:
(1)清场工作(如果初次安装,则不用这些命令)
step1:16-20所有机器,执行 ps -ef|grep java , 查看所有java进程,就可以看到所有集群相关的进程,比如zookeeper、hadoop、hbase之类的进程,执行 kill -9 xxx xxx 杀掉这些进程,这里的xxx是进程号。如果是按照以下步骤(2)中的启动方式启动的,那么在16这个master机器上,执行以下三条命令,能快速杀掉一批集群进程,提高杀进程的效率:
/data/hadoop/app/hbase-1.2.6/bin/stop-hbase.sh
step2:16-20所有机器 cd /data/hadoop/app/hadoop-2.8.2/hdfs rm -rf *
step1: 16-20所有机器上,启动zookeeper,也就是5个机器上都执行:/data/hadoop/app/zookeeper-3.4.10/bin/zkServer.sh start
step2: 16-20所有机器上,启动journalnode,也就是5个机器上都执行: /data/hadoop/app/hadoop-2.8.2/sbin/hadoop-daemon.sh start journalnode
step3: 16机器上(因为想选16机器为namenode的master机器),执行 /data/hadoop/app/hadoop-2.8.2/bin/hdfs namenode -format
step4: 16机器上,继续执行 /data/hadoop/app/hadoop-2.8.2/bin/hdfs zkfc -formatZK
step5:16机器上,执行 /data/hadoop/app/hadoop-2.8.2/sbin/start-dfs.sh, 这条命令执行的时候,你必须 已经参考上面的参考链接里的内容,把hadoop里的core-site.xml、 hdfs-site.xml、yarn-site.xml、 slaves 等文件,以及hbase/conf 下面的backup-masters文件(没有的话需要自己touch一下新建)、regionservers、hbase-site.xml等文件 都配置好了,
step6:想把17机器当成16机器的备机,17机器上执行:
/data/hadoop/app/hadoop-2.8.2/bin/hdfs namenode -bootstrapStandby
/data/hadoop/app/hadoop-2.8.2/bin/hdfs haadmin -getServiceState nn1 /data/hadoop/app/hadoop-2.8.2/bin/hdfs haadmin -getServiceState nn2 /data/hadoop/app/hadoop-2.8.2/sbin/start-yarn.sh ,也就是所有机器上启动了nodeManager,而且16机器上还启动了resourcemanager
step9: 17机器上,执行/data/hadoop/app/hadoop-2.8.2/sbin/yarn-daemon.sh start resourcemanager
step10: 16-17机器上,分别执行/data/hadoop/app/hadoop-2.8.2/sbin/mr-jobhistory-daemon.sh start historyserver ,这样就可以查看日志了,比如distcp命令的执行是否成功等,浏览器输入http://10.xx.xx.16:19888/jobhistory ,即可查看/data/hadoop/app/hbase-1.2.6/bin/start-hbase.sh 启动了所有的hmaster和hregionserver
(3)检查工作: jps 命令,查看启动了的进程,是否齐全。
step2: 16-20所有机器上,输入 hadoop checknative -a 命令,检查hadoop是否安装好,如果命令执行的结果,是所有配置都是空,那么就有问题。先 执行 cp /hadoop的目录/hadoop-2.8.2/lib/native/* /hadoop的目录/hadoop-2.8.2/lib/ , 然后再在 /etc/profile 文件里面添加一句 打印日志的配置:
export HADOOP_ROOT_LOGGER=DEBUG,console ,修改完profile文件后,保存,然后再次执行hadoop checknative -a 命令,发现提示信息 这个版本的hadoop 需要这个glibc 2.14版本及以上,那么开始安装glibc 2.14,不过安装方式得注意,不能安装glibc的tar.gz 这个包,要安装rpm包,否则会导致linux机器内核挂掉,机器崩溃,或者reboot了,glibc又回滚到之前的旧版本了。glibc 2.14 的rpm安装步骤,参考:https://blog.csdn.net/lxlmycsdnfree/article/details/80695593
大概7个需要安装的相关文件:
安装完glibc 2.14,然后再次执行hadoop checknative -a 命令,会发现返回的值都是不为空的。查看自己安装的glibc 新版本成功没有,命令是:strings /lib64/libc.so.6 | grep GLIBC
二. 迁移hbase数据
(1)选择迁移方法
旧集群的hbase里,就一个表,数据量大概四百多G, 迁移如果用 export/import的话,太慢,光export这个命令,就能执行40个小时。所以选用了distcp这个命令。
(2)执行命令前的一些配置工作:
A. 把旧集群机器上的 etc/hosts文件中的配置,复制粘贴,追加到 新机器的16-20机器上的etc/hosts文件中。也就是新集群机器上的hosts文件中,既有新集群机器的 hostname和ip的配置,又有旧集群的机器 hostname和ip的配置。如果不做这个步骤,distcp过程中会报错。
B. 16机器上的hadoop下的hdfs-site.xml文件中,还添加了以下配置,也是因为跨版本迁移的编码方式不一样,而添加的。
dfs.checksum.type CRC32
C. 最好把旧集群的hbase停掉,这样 distcp拷贝过程会很顺利,否则会报错。如果旧集群hbase实在不想停,那多执行几遍distcp命令,直到100%的数据都拷贝过来为止,没测过正确性,目测好像所有数据都拷过来了。
(3)执行命令:
16机器上,执行命令如下:hadoop distcp -update -skipcrccheck hftp://10.10.2x.xxx:50070/hbase/data/default/history_table hdfs://xx.xx.xx.16:9000/hbase/data/default/history_table
(4)命令详解:
其中的 -update -skipcrccheck 这个参数是必须的, 因为旧的集群,hadoop版本是2.2,新的hadoop版本是2.8,二者版本差异太大,编码方式不一样。旧集群的 前缀用了 hftp:// ,新集群的前缀用了 hftp://,也是因为跨版本集群的迁移。端口50070和9000,是分别在旧集群 和新集群的机器的 hadoop路径下的 hdfs-site.xml文件中查到的。
例如:
dfs.namenode.rpc-address.ns1.nn1 hadoop1:9000
(5)distcp常见错误:
首先,命令的参数之间不能有多余的空格,比如两三个空格。
其次,如果报running beyond physical memory limits 之类的错误,那就是需要修改Hadoop下的mapred-site.xml文件,里面添加内容有:
yarn.app.mapreduce.am.staging-dir
/user
yarn.app.mapreduce.am.resource.mb 8192
yarn.app.mapreduce.am.resource.cpu-vcores
1
mapreduce.job.ubertask.enable
false
yarn.app.mapreduce.am.command-opts -Djava.net.preferIPv4Stack=true -Xmx4294967296
mapreduce.map.java.opts -Djava.net.preferIPv4Stack=true -Xmx5368709120
mapreduce.reduce.java.opts -Djava.net.preferIPv4Stack=true -Xmx6442450944
mapreduce.map.memory.mb 6144
mapreduce.map.cpu.vcores
1
mapreduce.reduce.memory.mb 8192
mapreduce.reduce.cpu.vcores
1
保存后,如果distcp还报一样的错误,那就修改hadoop路径下的share文件夹里的hadoop-distcp-2.x.x.jar 这个jar包,用命令jar -xvf hadoop-distcp-2.x.x.jar 解压,把里面的xml文件里的内存配置删除掉,类似如下:
mapred.job.map.memory.mb 1024 mapred.job.reduce.memory.mb 1024
保存此xml文件,然后用 jar -cvf hadoop-distcp-2.x.x.jar * 再次打包,并替换掉之前的hadoop-distcp-2.x.x.jar 包,并保证集群每台机器都用这个新的jar包。改这个jar包,是因为这个jar包里对内存的配置,可能会覆盖掉之前mapred-site.xml文件对内存的配置
三. 分配hbase数据
16机器上,执行 hbase shell 命令,打开hbase命令窗口,执行 list , 发现并没有 表,因为distcp命令,把hbase数据,拷贝到datanode了,但是并没有和hbase挂钩。所以需要 退出hbase shell 窗口,需要依次执行:
hbase hbck -fixMeta (重新生成meta表数据,才能在hbase shell命令窗口看到 迁移过来的表),
hbase hbck -fixAssignments (分配到各个集群机器上)hbase hbck -repairHoles (修复漏洞,这个命令必须有,不然会出现 canal之类的都配置好后,hbase插入的数据的时间戳,慢两小时,报错信息如下:Requested row out of range for doMiniBatchMutation on HRegion ,用命令hbase hbck -details : 可以看出 hbase是否需要repair hole,不管有无hole,修复一下没坏处)
hbase shell命令窗口,可能用到的命令:
list 查看该空间下所有的表
scan '表名' 返回该表的所有数据
describe '表名' 返回表的结构描述
scan '表名',{FILTER=>"PrefixFilter('100990-154147')"} 查看 rowkey 为“100990-154147”开头的所有数据,其中-后面的这个数据一般为时间戳,单位为毫秒
get '表名','101244-1538396364000' 获取表中rowkey为101244-1538396364000的数据行
put '表名','100990-1541475190000','cf:q','54961736' 往表中插入一条数据:参数依次是表名,rowkey,列名,值,值得注意的是,时间戳是自动加的。
四. 迁移 canal
将老集群上的1.0.16 ,用scp -r命令 拷贝到 新集群的其中一个机器上,我选择了20机器。然后把canal-1.0.16/conf/example下的instance.properties文件中的canal.instance.mysql.slaveId值改了一下,比如之前旧集群的是1236,我这里改成1237 。因为canal相当于mysql的一个slave,测试的时候,想着 旧集群的canal和新集群的canal同时使用着,所以这里的slaveId改了一下。
依次启动 canal 和 hbase_netty.jar canal_netty.jar ,这两个jar,相当于canal客户端,canal_netty.jar 的代码,配置了20这个机器的root和机器密码,可以参考canal官方的canal client代码。hbase_netty.jar 里,配置了集群的信息,需要把新集群的core-site.xml、 hdfs-site.xml、hbase-site.xml 三个文件,拷贝到这个hbase_netty.jar的 项目里,替换掉就的xml文件即可。
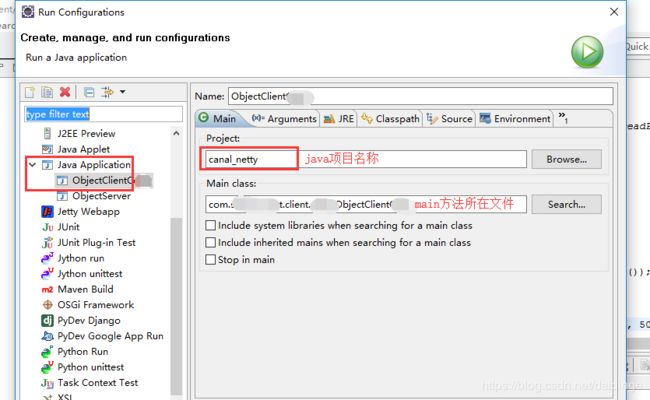
打包jar包的时候,注意两点:
1. eclipse中对这两个jar包打包前,需要配置一下 run configuration,在run configuration里面的application里面指定一下main方法的位置。
2. eclipse打包这两个jar包, export 的时候,选择 成 Runnable JAR file, 否则上传到linux执行不起来。
五. 升级 旧项目的jdk、tomcat等
将旧项目的jdk1.6 tomcat6,升级成 jdk1.8 tomcat9,需要修改对应的jar包,从集群的hbase的lib目录下,拷贝了所有jar包,替换掉旧项目的jar包,并且旧项目的前端文件 tld文件,之前在 目录WEB-INF/tags下,由于新版本的tomcat 规则变了,查看tomcat9的apache-tomcat-9.0.12\webapps\examples\WEB-INF 路径下的每个文件,发现tld文件,应该放到WEB-INF/jsp2 路径下,所以项目的前端代码中,新建jsp2路径,将tld文件,移到它下面。
你可能感兴趣的:(HBase)
Hbase - 表导出CSV数据
kikiki1
新鲜文章,昨天刚经过线上验证过的,使用它导出了3亿的用户数据出来,花了半个小时,性能还是稳稳的,好了不吹牛皮了,直接上代码吧。MR考查了Hbase的各种MR,没有发现哪一个是能实现的,如果有请通知我,我给他发红包。所以我们只能自己来写一个MR了,编写一个Hbase的MR,官方文档上也有相应的例子。我们用来加以化妆就得到我们想要的了。导出的CSV格式为admin,22,北京admin,23,天津依赖
ftp文件服务器有连接数限制,查看ftp服务器连接数命令
赵承铭
ftp文件服务器有连接数限制
查看ftp服务器连接数命令内容精选换一换本章节适用于MRS3.x之前版本。Loader支持以下多种连接,每种连接的配置介绍可根据本章节内容了解。obs-connectorgeneric-jdbc-connectorftp-connector或sftp-connectorhbase-connector、hdfs-connector或hive-connectorOBS连接是Loa“数据导入”章节适用于
HBase总结
HBase1.HBase核心概念HBase的作用HBase主要用于存储和管理超大规模的结构化或半结构化数据(如PB级),特点包括:高扩展性:通过分布式架构横向扩展,支持数千台服务器高吞吐量:适合实时随机读写(如用户行为日志、实时分析)强一致性:保证同一行数据的原子性操作灵活的数据模型:支持动态列和稀疏存储典型应用场景:互联网公司的用户行为日志存储(如点击流数据)社交媒体的实时消息存储物联网设备时序
Hadoop核心组件最全介绍
Cachel wood
大数据开发 hadoop 大数据 分布式 spark 数据库 计算机网络
文章目录一、Hadoop核心组件1.HDFS(HadoopDistributedFileSystem)2.YARN(YetAnotherResourceNegotiator)3.MapReduce二、数据存储与管理1.HBase2.Hive3.HCatalog4.Phoenix三、数据处理与计算1.Spark2.Flink3.Tez4.Storm5.Presto6.Impala四、资源调度与集群管
HBase 开发:使用Java操作HBase
睡觉的时候我不困
hbase java python
第1关:创建表任务描述相关知识如何使用Java连接HBase数据库HBaseConfigurationConnectionFactory创建表HBase2.X创建表编程要求测试说明任务描述本关任务:使用Java代码在HBase中创建表。相关知识为了完成本关任务,你需要掌握:1.如何使用Java连接HBase数据库,2.如何使用Java代码在HBase中创建表。如何使用Java连接HBase数据库J
头歌作业-HBase 开发:使用Java操作HBase
http_lizi
hbase java python
第一关packagestep1;importjava.io.IOException;importorg.apache.hadoop.conf.Configuration;importorg.apache.hadoop.hbase.HBaseConfiguration;importorg.apache.hadoop.hbase.HColumnDescriptor;importorg.apache.h
PostgreSql、Hbase的安装
月光一族吖
postgresql hbase 数据库
在CentOS8中安装PostgreSQL和HBase,以下是详细步骤,包括使用sudo权限的命令:安装PostgreSQL更新系统包在两台CentOS8上运行以下命令,确保系统是最新的:sudodnfupdate-y安装PostgreSQLCentOS8默认仓库提供PostgreSQL。你可以直接安装所需版本的PostgreSQL:sudodnfinstall-ypostgresql-serve
HDFS与HBase有什么关系?
lucky_syq
hdfs hbase hadoop
1、HDFS文件存储系统和HBase分布式数据库HDFS是Hadoop分布式文件系统。HBase的数据通常存储在HDFS上。HDFS为HBase提供了高可靠性的底层存储支持。Hbase是Hadoopdatabase,即Hadoop数据库。它是一个适合于非结构化数据存储的数据库,HBase基于列的而不是基于行的模式。
Hbase和关系型数据库、HDFS、Hive的区别
别这么骄傲
hive hbase 数据库
目录1.Hbase和关系型数据库的区别2.Hbase和HDFS的区别3.Hbase和Hive的区别1.Hbase和关系型数据库的区别关系型数据库Hbase存储适合结构化数据,单机存储适合结构化和半结构数据的松散数据,分布式存储功能(1)支持ACID(2)支持join(3)使用主键PK(4)数据类型:int、varchar等(1)仅支持单行事务(2)不支持join,把数据糅合到一张大表(3)行键ro
大数据基础知识-Hadoop、HBase、Hive一篇搞定
原来是猪猪呀
hadoop 大数据 分布式
HadoopHadoop是一个由Apache基金会所开发的分布式系统基础架构,其核心设计包括分布式文件系统(HDFS)和MapReduce编程模型;Hadoop是一个开源的分布式计算框架,旨在帮助用户在不了解分布式底层细节的情况下,开发分布式程序。它通过利用集群的力量,提供高速运算和存储能力,特别适合处理超大数据集的应用程序。Hadoop生态圈Hadoop生态圈是一个由多个基于Hadoop开发的相
Hadoop、HDFS、Hive、Hbase区别及联系
静心观复
大数据 hadoop hdfs hive
Hadoop、HDFS、Hive和HBase是大数据生态系统中的关键组件,它们都是由Apache软件基金会管理的开源项目。下面将深入解析它们之间的区别和联系。HadoopHadoop是一个开源的分布式计算框架,它允许用户在普通硬件上构建可靠、可伸缩的分布式系统。Hadoop通常指的是整个生态系统,包括HadoopCommon(共享库和工具)、HadoopDistributedFileSystem(
大数据(1)-hdfs&hbase
viperrrrrrr
大数据 hdfs hbase
hbase&hdfs一、体系结构HDFS是一个标准的主从(Master/Slave)体系结构的分布式系统;HDFS集群包含一个或多个NameNode(NameNodeHA会有多个NameNode)和多个DataNode(根据节点情况规划),用户可以通过HDFS客户端同NameNode和DataNode进行交互以访问文件系统。HDFS公开文件系统名称空间,并允许将用户数据存储在文件中。在内部,一个文
HBase 开发:使用Java操作HBase 第1关:创建表
是草莓熊吖
hbase 大数据 Educoder hbase hadoop 大数据
为了完成本关任务,你需要掌握:1.如何使用Java连接HBase数据库,2.如何使用Java代码在HBase中创建表。如何使用Java连接HBase数据库Java连接HBase需要两个类:HBaseConfigurationConnectionFactoryHBaseConfiguration要连接HBase我们首先需要创建Configuration对象,这个对象我们需要通过HBaseConfig
Hbase-表操作
红笺Code
Hbase hbase 大数据 数据分析 非关系型数据库 zookeeper
目录一、创建表:1.创建表时指定列族的属性2.创建表时不指定列族的属性多学一招:克隆表二、查看表信息三、查看表四、停用和启用表1.停用表2.启用表多学一招:停用或启用多个表五、判断表1.exists命令2.is_enabled命令3.is_disabled命令六、修改表1.修改表属性(1)添加属性(2)删除属性2.修改列族(1)修改列族属性(2)添加列族(3)删除列族七、删除表drop命令多学一招
头歌 当HBase遇上MapReduce
敲代码的苦13
头歌 hbase mapreduce 数据库
头歌当HBase遇上MapReduce第1关:HBase的MapReduce快速入门代码行:packagecom.processdata;importjava.io.IOException;importjava.util.List;importjava.util.Scanner;importorg.apache.hadoop.conf.Configuration;importorg.apache.
大数据集群架构hadoop集群、Hbase集群、zookeeper、kafka、spark、flink、doris、dataeas(二)
争取不加班!
hadoop hbase zookeeper 大数据 运维
zookeeper单节点部署wget-chttps://dlcdn.apache.org/zookeeper/zookeeper-3.8.4/apache-zookeeper-3.8.4-bin.tar.gz下载地址tarxfapache-zookeeper-3.8.4-bin.tar.gz-C/data/&&mv/data/apache-zookeeper-3.8.4-bin//data/zoo
JT808教程:设置/查询终端参数
REDISANT提供互联网与物联网开发测试套件#互联网与中间件:RedisAssistantZooKeeperAssistantKafkaAssistantRocketMQAssistantRabbitMQAssistantPulsarAssistantHBaseAssistantNoSqlAssistantEtcdAssistantGarnetAssistant工业与物联网:MQTTAssist
Squirrel: 通用SQL、NoSQL客户端
antui1957
安装配置数据库配置驱动配置连接如果你的工作中,需要使用到多个数据库,又不想在多种客户端之间切换来切换去。那么就需要找一款支持多数据库的客户端工具了。如果你要连接多个关系型数据库,你就可以使用NavicatPremium。但是如果你有使用到NOSQL(譬如HBase、MongoDB等),还是建议使用SquirrelSQLClient。1、安装下载地址:http://squirrel-sql.sour
使用datax进行mysql的表恢复
是桃萌萌鸭~
mysql 数据库
DataXDataX是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括MySQL、SQLServer、Oracle、PostgreSQL、HDFS、Hive、HBase、OTS、ODPS等各种异构数据源之间高效的数据同步功能。FeaturesDataX本身作为数据同步框架,将不同数据源的同步抽象为从源头数据源读取数据的Reader插件,以及向目标端写入数据的Writer插件,理论上Dat
hbase:meta 表解析
有数的编程笔记
HBase
hbase:meta表中存储了Hbase集群中全部表的所有的region信息,在Hbase2.x之后新增了表的状态信息。hbase:meta表的结构非常简单,在Hbase2.x之前整个表只有一个名为info的ColumnFamily。在Hbase2.x新增表状态信息后,增加了名为table的ColumnFamily。HBase保证hbase:meta表始终只有一个Region,这是为了确保meta
Hadoop等大数据处理框架的Java API
扬子鳄008
Java hadoop java 大数据
Hadoop是一个非常流行的大数据处理框架,主要用于存储和处理大规模数据集。Hadoop主要有两个核心组件:HDFS(HadoopDistributedFileSystem)和MapReduce。此外,还有许多其他组件,如YARN(YetAnotherResourceNegotiator)、HBase、Hive等。下面详细介绍Hadoop及其相关组件的JavaAPI及其使用方法。HadoopHad
手把手教你玩转 Sqoop:从数据库到大数据的「数据搬运工」
AAA建材批发王师傅
数据库 sqoop 大数据 hive hdfs
一、Sqoop是什么?——数据界的「超级搬运工」兄弟们,今天咱们聊个大数据圈的「搬运小能手」——Sqoop!可能有人会问:这玩意儿跟Flume啥区别?简单来说:Flume是专门搬日志数据的「快递员」而Sqoop是搬数据库数据的「搬家公司」它的名字咋来的?SQL+Hadoop,直接告诉你核心技能:在关系型数据库(比如MySQL)和Hadoop家族(HDFS、Hive、HBase)之间疯狂倒腾数据!核
【请关注】hBase要用的顺畅的思路
DoWeixin6
数据相关 数据库
玩楞一下HBase,要让这玩意儿在大数据量下跑得顺,索引和优化可都是实打实的硬活。先说索引这块。HBase就认RowKey这个主索引,所有数据都按它排得明明白白。平时查数据,只要RowKey设计得好,直接就能定位到对应的Region,速度快得很。但RowKey要是拍脑袋瞎写,比如全按时间戳排序,那准得出大问题——数据全往一个Region挤,妥妥的热点,集群直接卡住。所以设计RowKey时,我一般会
【赵渝强老师】HBase的体系架构
赵渝强老师
NoSQL数据库 hbase 架构 数据库 大数据 hadoop hdfs nosql
HBase是大表(BigTable)思想的一个具体实现。它是一个列式存储的NoSQL数据库,适合执行数据的分析和处理。简单来说,就是适合执行查询操作。从体系架构的角度看,HBase是一种主从架构,包含:HBaseHMaster、RegionServer和ZooKeeper,下图展示了这一架构。其中:HBaseHMaster负责Region的分配及数据库的创建和删除等操作。Regionserver负
大数据学习(141)-分布式数据库
viperrrrrrr
大数据 学习 分布式 clickhouse hdfs hbase
在分布式数据库中主要有hdfs、hbase、clickhouse三种。HDFS(HadoopDistributedFileSystem)、HBase和ClickHouse都是处理大数据的分布式系统,但它们的设计目标、架构和适用场景有所不同。一、HDFS(HadoopDistributedFileSystem)HDFS是Hadoop生态系统的一部分,是一个高度容错的系统,适合存储大量数据。它被设计为
TiDB 替换 HBase 全场景实践指南 ——从架构革新到业务赋能
TiDB 社区干货传送门
tidb hbase 架构 数据库 大数据
作者:数据源的TiDB学习之路原文来源:https://tidb.net/blog/c687d474第一章:HBase的历史使命与技术瓶颈1.1HBase的核心价值与经典场景作为Hadoop生态的核心组件,HBase凭借LSM-Tree存储引擎和Region分片机制,在2010年代成为海量数据存储的标杆。其典型场景包括:日志流处理:支持Kafka每日TB级数据持久化,写入吞吐达百万级QPS(如某头
【Ambari3.0.0 部署】Step3—安装JDK17与JDK1.8-适用于el8
TTBIGDATA
ambari bigtop hdp hidataplus edp 大数据 el8
如果有其他系统部署需求可以参考原文https://doc.janettr.com/install/manual/Step3—安装JDK17与JDK1.8Ambari3.0及部分Bigtop/Hadoop新组件强制要求JDK17,而HBase/Hive/Spark生态仍有组件长期依赖JDK1.8。因此推荐双版本共存方案,让集群灵活兼容各种大数据组件,满足未来升级和遗留需求。JDK17与JDK1.8可
时序数据管理的新维度:解析IoTDB与HBase的技术边界
时序数据说
iotdb hbase 数据库 时序数据库 分布式 开源
在物联网与工业大数据场景中,数据的时序特性对存储与计算提出了独特挑战。面对海量设备生成的高频时序数据,如何在有限的资源内实现高效写入、灵活查询与实时分析,成为企业技术选型的核心考量。本文将从架构设计、数据建模、性能表现及场景适配等角度,对比分析IoTDB与HBase的技术差异,探索时序数据库的演进方向。一、设计哲学的分野:专用时序与通用存储HBase作为经典的NoSQL数据库,以宽表模型和LSM-
大数据领域HBase的数据压缩技术应用
AI天才研究院
AI大模型企业级应用开发实战 AI Agent 应用开发 大数据 hbase 数据库 ai
大数据领域HBase的数据压缩技术应用关键词:大数据、HBase、数据压缩技术、压缩算法、性能优化摘要:本文深入探讨了大数据领域中HBase的数据压缩技术应用。首先介绍了HBase的背景以及数据压缩技术在其中的重要性,详细阐述了常见的压缩算法原理,包括LZO、Snappy、Gzip等。通过数学模型和公式分析了不同压缩算法的性能指标,如压缩比和压缩速度。给出了在HBase中应用数据压缩技术的项目实战
大数据、数据挖掘技术收集(Vivo互联网技术)
XiaoQiong.Zhang
数据挖掘 大数据
Hudi在vivo湖仓一体的落地实践用户行为分析模型实践(四)——留存分析模型用户行为分析模型实践(三)——H5通用分析模型用户行为分析模型实践(二)——漏斗分析模型用户行为分析模型实践(一)——路径分析模型AB实验遇到用户不均匀怎么办?——vivo游戏中心业务实践经验分享HBaseCompaction原理与线上调优实践vivo游戏黑产反作弊实践Kafka实时数据即席查询应用与实践Hive和Spa
java Illegal overloaded getter method with ambiguous type for propert的解决
zwllxs
java jdk
好久不来iteye,今天又来看看,哈哈,今天碰到在编码时,反射中会抛出
Illegal overloaded getter method with ambiguous type for propert这么个东东,从字面意思看,是反射在获取getter时迷惑了,然后回想起java在boolean值在生成getter时,分别有is和getter,也许我们的反射对象中就有is开头的方法迷惑了jdk,
IT人应当知道的10个行业小内幕
beijingjava
工作 互联网
10. 虽然IT业的薪酬比其他很多行业要好,但有公司因此视你为其“佣人”。
尽管IT人士的薪水没有互联网泡沫之前要好,但和其他行业人士比较,IT人的薪资还算好点。在接下的几十年中,科技在商业和社会发展中所占分量会一直增加,所以我们完全有理由相信,IT专业人才的需求量也不会减少。
然而,正因为IT人士的薪水普遍较高,所以有些公司认为给了你这么多钱,就把你看成是公司的“佣人”,拥有你的支配
java 实现自定义链表
CrazyMizzz
java 数据结构
1.链表结构
链表是链式的结构
2.链表的组成
链表是由头节点,中间节点和尾节点组成
节点是由两个部分组成:
1.数据域
2.引用域
3.链表的实现
&nbs
web项目发布到服务器后图片过一会儿消失
麦田的设计者
struts2 上传图片 永久保存
作为一名学习了android和j2ee的程序员,我们必须要意识到,客服端和服务器端的交互是很有必要的,比如你用eclipse写了一个web工程,并且发布到了服务器(tomcat)上,这时你在webapps目录下看到了你发布的web工程,你可以打开电脑的浏览器输入http://localhost:8080/工程/路径访问里面的资源。但是,有时你会突然的发现之前用struts2上传的图片
CodeIgniter框架Cart类 name 不能设置中文的解决方法
IT独行者
CodeIgniter Cart 框架
今天试用了一下CodeIgniter的Cart类时遇到了个小问题,发现当name的值为中文时,就写入不了session。在这里特别提醒一下。 在CI手册里也有说明,如下:
$data = array(
'id' => 'sku_123ABC',
'qty' => 1,
'
linux回收站
_wy_
linux 回收站
今天一不小心在ubuntu下把一个文件移动到了回收站,我并不想删,手误了。我急忙到Nautilus下的回收站中准备恢复它,但是里面居然什么都没有。 后来我发现这是由于我删文件的地方不在HOME所在的分区,而是在另一个独立的Linux分区下,这是我专门用于开发的分区。而我删除的东东在分区根目录下的.Trash-1000/file目录下,相关的删除信息(删除时间和文件所在
jquery回到页面顶端
知了ing
html jquery css
html代码:
<h1 id="anchor">页面标题</h1>
<div id="container">页面内容</div>
<p><a href="#anchor" class="topLink">回到顶端</a><
B树、B-树、B+树、B*树
矮蛋蛋
B树
原文地址:
http://www.cnblogs.com/oldhorse/archive/2009/11/16/1604009.html
B树
即二叉搜索树:
1.所有非叶子结点至多拥有两个儿子(Left和Right);
&nb
数据库连接池
alafqq
数据库连接池
http://www.cnblogs.com/xdp-gacl/p/4002804.html
@Anthor:孤傲苍狼
数据库连接池
用MySQLv5版本的数据库驱动没有问题,使用MySQLv6和Oracle的数据库驱动时候报如下错误:
java.lang.ClassCastException: $Proxy0 cannot be cast to java.sql.Connec
java泛型
百合不是茶
java泛型
泛型
在Java SE 1.5之前,没有泛型的情况的下,通过对类型Object的引用来实现参数的“任意化”,任意化的缺点就是要实行强制转换,这种强制转换可能会带来不安全的隐患
泛型的特点:消除强制转换 确保类型安全 向后兼容
简单泛型的定义:
泛型:就是在类中将其模糊化,在创建对象的时候再具体定义
class fan
javascript闭包[两个小测试例子]
bijian1013
JavaScript JavaScript
一.程序一
<script>
var name = "The Window";
var Object_a = {
name : "My Object",
getNameFunc : function(){
var that = this;
return function(){
探索JUnit4扩展:假设机制(Assumption)
bijian1013
java Assumption JUnit 单元测试
一.假设机制(Assumption)概述 理想情况下,写测试用例的开发人员可以明确的知道所有导致他们所写的测试用例不通过的地方,但是有的时候,这些导致测试用例不通过的地方并不是很容易的被发现,可能隐藏得很深,从而导致开发人员在写测试用例时很难预测到这些因素,而且往往这些因素并不是开发人员当初设计测试用例时真正目的,
【Gson四】范型POJO的反序列化
bit1129
POJO
在下面这个例子中,POJO(Data类)是一个范型类,在Tests中,指定范型类为PieceData,POJO初始化完成后,通过
String str = new Gson().toJson(data);
得到范型化的POJO序列化得到的JSON串,然后将这个JSON串反序列化为POJO
import com.google.gson.Gson;
import java.
【Spark八十五】Spark Streaming分析结果落地到MySQL
bit1129
Stream
几点总结:
1. DStream.foreachRDD是一个Output Operation,类似于RDD的action,会触发Job的提交。DStream.foreachRDD是数据落地很常用的方法
2. 获取MySQL Connection的操作应该放在foreachRDD的参数(是一个RDD[T]=>Unit的函数类型),这样,当foreachRDD方法在每个Worker上执行时,
NGINX + LUA实现复杂的控制
ronin47
nginx lua
安装lua_nginx_module 模块
lua_nginx_module 可以一步步的安装,也可以直接用淘宝的OpenResty
Centos和debian的安装就简单了。。
这里说下freebsd的安装:
fetch http://www.lua.org/ftp/lua-5.1.4.tar.gz
tar zxvf lua-5.1.4.tar.gz
cd lua-5.1.4
ma
java-递归判断数组是否升序
bylijinnan
java
public class IsAccendListRecursive {
/*递归判断数组是否升序
* if a Integer array is ascending,return true
* use recursion
*/
public static void main(String[] args){
IsAccendListRecursiv
Netty源码学习-DefaultChannelPipeline2
bylijinnan
java netty
Netty3的API
http://docs.jboss.org/netty/3.2/api/org/jboss/netty/channel/ChannelPipeline.html
里面提到ChannelPipeline的一个“pitfall”:
如果ChannelPipeline只有一个handler(假设为handlerA)且希望用另一handler(假设为handlerB)
来
Java工具之JPS
chinrui
java
JPS使用
熟悉Linux的朋友们都知道,Linux下有一个常用的命令叫做ps(Process Status),是用来查看Linux环境下进程信息的。同样的,在Java Virtual Machine里面也提供了类似的工具供广大Java开发人员使用,它就是jps(Java Process Status),它可以用来
window.print分页打印
ctrain
window
function init() {
var tt = document.getElementById("tt");
var childNodes = tt.childNodes[0].childNodes;
var level = 0;
for (var i = 0; i < childNodes.length; i++) {
安装hadoop时 执行jps命令Error occurred during initialization of VM
daizj
jdk hadoop jps
在安装hadoop时,执行JPS出现下面错误
[slave16]
[email protected] :/tmp/hsperfdata_hdfs# jps
Error occurred during initialization of VM
java.lang.Error: Properties init: Could not determine current working
PHP开发大型项目的一点经验
dcj3sjt126com
PHP 重构
一、变量 最好是把所有的变量存储在一个数组中,这样在程序的开发中可以带来很多的方便,特别是当程序很大的时候。变量的命名就当适合自己的习惯,不管是用拼音还是英语,至少应当有一定的意义,以便适合记忆。变量的命名尽量规范化,不要与PHP中的关键字相冲突。 二、函数 PHP自带了很多函数,这给我们程序的编写带来了很多的方便。当然,在大型程序中我们往往自己要定义许多个函数,几十
android笔记之--向网络发送GET/POST请求参数
dcj3sjt126com
android
使用GET方法发送请求
private static boolean sendGETRequest (String path,
Map<String, String> params) throws Exception{
//发送地http://192.168.100.91:8080/videoServi
linux复习笔记 之bash shell (3) 通配符
eksliang
linux 通配符 linux通配符
转载请出自出处:
http://eksliang.iteye.com/blog/2104387
在bash的操作环境中有一个非常有用的功能,那就是通配符。
下面列出一些常用的通配符,如下表所示 符号 意义 * 万用字符,代表0个到无穷个任意字符 ? 万用字符,代表一定有一个任意字符 [] 代表一定有一个在中括号内的字符。例如:[abcd]代表一定有一个字符,可能是a、b、c
Android关于短信加密
gqdy365
android
关于Android短信加密功能,我初步了解的如下(只在Android应用层试验):
1、因为Android有短信收发接口,可以调用接口完成短信收发;
发送过程:APP(基于短信应用修改)接受用户输入号码、内容——>APP对短信内容加密——>调用短信发送方法Sm
asp.net在网站根目录下创建文件夹
hvt
.net C# hovertree asp.net Web Forms
假设要在asp.net网站的根目录下建立文件夹hovertree,C#代码如下:
string m_keleyiFolderName = Server.MapPath("/hovertree");
if (Directory.Exists(m_keleyiFolderName))
{
//文件夹已经存在
return;
}
else
{
try
{
D
一个合格的程序员应该读过哪些书
justjavac
程序员 书籍
编者按:2008年8月4日,StackOverflow 网友 Bert F 发帖提问:哪本最具影响力的书,是每个程序员都应该读的?
“如果能时光倒流,回到过去,作为一个开发人员,你可以告诉自己在职业生涯初期应该读一本, 你会选择哪本书呢?我希望这个书单列表内容丰富,可以涵盖很多东西。”
很多程序员响应,他们在推荐时也写下自己的评语。 以前就有国内网友介绍这个程序员书单,不过都是推荐数
单实例实践
跑龙套_az
单例
1、内部类
public class Singleton {
private static class SingletonHolder {
public static Singleton singleton = new Singleton();
}
public Singleton getRes
PO VO BEAN 理解
q137681467
VO DTO po
PO:
全称是 persistant object持久对象 最形象的理解就是一个PO就是数据库中的一条记录。 好处是可以把一条记录作为一个对象处理,可以方便的转为其它对象。
BO:
全称是 business object:业务对象 主要作用是把业务逻辑封装为一个对象。这个对
战胜惰性,暗自努力
金笛子
努力
偶然看到一句很贴近生活的话:“别人都在你看不到的地方暗自努力,在你看得到的地方,他们也和你一样显得吊儿郎当,和你一样会抱怨,而只有你自己相信这些都是真的,最后也只有你一人继续不思进取。”很多句子总在不经意中就会戳中一部分人的软肋,我想我们每个人的周围总是有那么些表现得“吊儿郎当”的存在,是否你就真的相信他们如此不思进取,而开始放松了对自己的要求随波逐流呢?
我有个朋友是搞技术的,平时嘻嘻哈哈,以
NDK/JNI二维数组多维数组传递
wenzongliang
二维数组 jni NDK
多维数组和对象数组一样处理,例如二维数组里的每个元素还是一个数组 用jArray表示,直到数组变为一维的,且里面元素为基本类型,去获得一维数组指针。给大家提供个例子。已经测试通过。
Java_cn_wzl_FiveChessView_checkWin( JNIEnv* env,jobject thiz,jobjectArray qizidata)
{
jint i,j;
int s