用机器学习预测股票,3个事项助你避开雷区
全文共2547字,预计学习时长5分钟

图片来源:Unsplash Aron Visuals
机器学习的普及前所未有。它广泛应用于基于数据决策的领域,在投资领域亦是如此。只需要在谷歌中同时搜索“机器学习”和“股票预测”,便可以得到大量关于时间序列预测和循环神经网络的内容。尽管股票价格对于这类算法来说是绝佳的数据选择,但是我们仍应当谨慎行事,尤其是涉及到钱的时候。
开始学习机器学习预测技术的人基本都知道维恩图迭代:

可以清楚地看到,机器学习(或数据科学)将技术技能(例如编程和数学)和各领域专业知识相融合。没有这三种形式的共同呈现,就只能回归至其中一个纯粹的领域之中。
这一描述对金融领域的机器学习尤其适用。时间序列财务数据十分微妙,应用现成的算法去处理未加工的价格数据是发现错误和防止资金损失的一个很好的方法。因此,使用这些数据需要注意一些特殊事项,尤其是关于行业知识的应用。
基于此,本文致力于提供一些常常被新人忽略的直观事实。由于数学和编码相关的可用资源已经十分丰富了,这里主要关注对问题的探讨。
1. 数据

图片来源:Unsplash Markus Spiske
这也许并没有什么可惊讶的,因为数据是任何一种机器学习模型的重要组成元素,股票预测也不例外。首先需要理解数据产生的过程,进而才能知道为什么需要如此谨慎。通常所分析领域的股票预测数据集就是时间序列数据,例如宏观经济数据、基础数据和价格数据。这类数据存在一种序列相关现象(serial correlation),简而言之就是每一个观测值都是以前一个时间间隔的观测值为基础的。
为了在实践中说明这一点,以价格为例。如果我们观察任何一支股票并追踪其每日价格走势,便会发现,除了一些“小”偏差,每支股票的收盘价都与前一天的收盘价紧密挂钩。
这是为什么呢?简单来说,股票是企业所有权份额,其价值由永恒不变的会计等式所决定,即资产减负债等于股东权益(assets minus liabilities equals equity)。股票是股价主体的企业基础价值,投资者情绪、交易行为和噪音则影响着每日偏差值。企业资产价值,即机器、土地、建筑物和库存,不会在一夜之间发生巨大变化,负债大多数情况也是如此。如果没有财务丑闻,那么企业的基础价值整体来说是相对稳定的。
这对机器学习意味着什么呢?它意味着模型可以通过与损失函数进行博弈,并选择前一天的股价作为今日价格预测值,以出色地完成工作。当许多“优秀预测模型”的预测输出曲线与实际股价滞后的移动平均线相接近时,便可以清楚地看到这一点。任何这类模型都在不断地接近实际价格。
平稳性问题也有类似的特征。许多机器学习模型和预处理技术都以生成数据的分布参数是常量为假设前提的。换句话说,特征的均值和标准差不随时间的变化而变化,数据中也看不出趋势。然而,只要看看长期以来常用的美国季度GDP数据,就会很快打消这种想法。这些数据中显然存在一种趋势,因此,如果一个经济体呈增长态势,便可以预料到其产出及价格会随着时间而增长。

图片来源:BEA 名称:美国象征性的GDP
该数据的平均值和标准差随时间而变动,这也给盲目应用回归分析等算法和标准化及主成分分析等预处理技术带来一定不便。
在(投资)文献和实践中,预防时间序列中异常情况出现的常用方式是在两个时间段之间选取股价收益率(或其他数据变化率)而非取绝对值。其背后的规律与自回归求和移动平均模式(ARIMA) 的时间序列预测中的去趋势化和差分化十分相似,目的都是保持数据的平稳。我们如果将这一方法应用于美国的GDP数据,将会得到一个类似于常规id变量的结果。
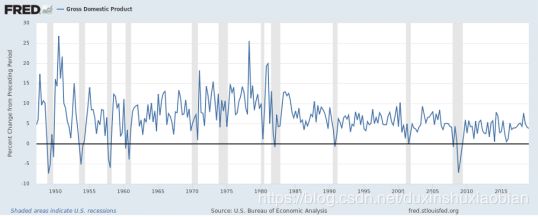
图片来源:BEA 名称:国内生产总值较前期变动百分比
这并非一个完美的方法,甚至会产生其它各种各样的问题,但它是广为接受的。
2. 随机误差项——现实世界的结果

图片来源:Unsplash Emily Morter
大多数监督机器学习的方法都是通过估计或优化一组使目标函数最小化的权值来拟定的。在回归分析问题中,这个函数通常是均方根误差(RMSE) ,在分类中,属于交叉熵(Cross Entropy)。对于像ILSVRC这类经典基准数据集来说,这已经成为一场“逐底竞争”,高水平的团队正在年复一年地大幅降低错误率。虽然这对学术研究有一定的价值意义,但过于追求降低任意误差同时也导致了现实世界中一些亟待解决的问题更加抽象化。
在投资领域内,能够找到一个准确率达到95%的模型对何时买进或卖出股票进行分类已经十分不错了。但通常情况下,这个模型不会模拟真实的投资组合行为,而且最重要的是,它不会考虑出错的代价。市场瞬息万变,虽然看似有利的投资环境可能会持续多年,但是调整变化或者“黑天鹅事件”(纳西姆•塔勒布提出这一概念,即难以预测、不寻常的事件)可能会随时发生。
若任何一个代表5%错误率的事件与一件罕见却又具有灾难性的事件同时发生,那么你的投资组合一定会受到影响,甚至95%正确率所累计的价值都会不复存在(假设不存在泛化误差)。这一问题对于专业投资经理来说则更为严重,因为10%的减少足以导致投资者大规模撤离基金。收益和投入不对称产生的影响在经验丰富的从业者心中根深蒂固,这也解释了为什么这个行业既注重创造收益又重视风险管理。
这里为机器学习者和数据科学家介绍这些知识是为了帮助他们更深入地理解模型背后的意义,摆脱仅仅被告知错误率和损失函数的状况,并执行前向测试(walk forward testing )。这就好比你随着时间的变化而持有预期交易,并采用能够惩罚模型错误的成本敏感型措施。
3. 击败市场比你想象的还要难

图片来源:Unsplash Inactive.
要理解机会成本这一概念,仅拥有一个可以获取收益的机器学习模型是远远不够用的。机会成本这一重要经济原则阐述了放弃下一个最佳投资机会所需承担的代价。
如果不使用拟议的机器学习模型进行投资,那么下一个最佳机会,也是一个不需要太多技巧的机会,就是购买交易所交易基金来增加市场份额。这些产品可以让你以相对较低的成本获得标普500等指数水平的回报。因此必须思考一个问题,如果模型的性能调整过交易成本后,没有显著超过标准普尔500指数日历年迄今为止收益率达到18.74%的表现,那么你真的做出明智的理财投资了吗?
职业投资经理总是受制于某种基准,在这种基准下,他们的技能是由他们超越该基准的能力来衡量的,而机器学习者和数据科学家在评估自己的财务预测能力时却没有类似的基准进行衡量。

留言 点赞 发个朋友圈
我们一起分享AI学习与发展的干货
编译组:何孟琛、黄雪娇
相关链接:
https://towardsdatascience.com/predicting-stocks-with-machine-learning-1f8c53faaca3
如需转载,请后台留言,遵守转载规范
长按识别二维码可添加关注
读芯君爱你
