网络爬虫——爬取京东数据
下面是我的代码框架(请先看代码需要改进的地方)

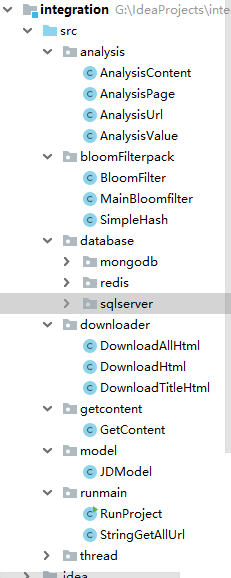
需要改进的是
1、采用双缓冲队列,即两个队列,可以理解为一个队列用于生产者的数据写入,一个用于消费者的数据读取,当消费者队列没有数据从生产者队列获取,减少锁的竞争。
2、使用selenium(webdriver)连接池(在另一个中会有)。
3、代码过于繁琐与冗余,可以进行精简(这个可能没时间了)。
架构及代码详细说明(后面附上我的完整代码)
1、model中包括一个模型,该模型表示我要爬取的京东的信息。比如一本书包括书的识别码,名字,价格,出版社等信息。
2、runmain中包含两个包,一个是运行包(有main函数,消费者-生产者模型),一个是需要调用包(作用是对字符串进行拼接以获取全部的要提取信息的url)。
3、thread包中是消费者-生产者模型,product和consumer。具体请看代码。
4、downloader中包括下载的所有类,需要有selenium基础。
5、analysis中包括所有解析的类,需要有selenium基础。
6、bloomFilterpack这是一个过滤器。
7、database数据库的有关操作,需要有mongodb基础,redis基础。
架构思路
1、首先获取京东官网的所有要爬取的数据(分类信息)。如下图所示,箭头所指方向即为要获取的分类信息。获取该部分所有的数据并存入redis数据库,具体看下方代码及注释。

解释:下图中蓝色的代码刚开始不显示,只有鼠标移动到上图右边红框上才会显示该部分代码。

package runmain;
/**
1.
创建时间:2019年1月18日 下午6:43:11
3.
4. 项目名称:integration_zhong
5.
6. @author 王锋洲
7.
8. @version 1.0
9.
10. @since JDK 1.8
11.
12. 文件名称:run_project.java
13.
14. 类说明:主类,调用方法将所有分类信息插入到数据库并进行后续操作。
15.
*/
public class RunProject {
public static void main(String[] args) {
Jedis jedis = new Jedis("192.168.50.194");
jedis.flushAll();
InitRedis init = new InitRedis();
init.Init();
//获取首页内容
GetContent content=new GetContent();
//调用方法,代码如下
content.getcontenttext();
System.out.println("title success");
}
}
public void getcontenttext()
{
try {
/*调用GetContent()方法,该方法以GetDownload_html方法返回值作为参数*/
ana_content.GetContent(down.GetDownload_html(base.GetToVisit()));
} catch (InterruptedException e) {
e.printStackTrace();
}
}
public class AnalysisContent
{
List<String> list = new ArrayList<String>();
Jedis jedis=new Jedis();
RedisBase jedis_content=new RedisBase();
public void GetContent(String result)
{
//这里可以用正则解析,具体可以自己编写
//用Jsoup解析代码
Document doc=Jsoup.parse(result);
Elements links = doc.select("div[class=JS_popCtn cate_pop]").select("div[class=cate_part clearfix]").select("div[class=cate_part_col1]").select("dd[class=cate_detail_con]").select("a[href]");
for(Element link:links)
{
String content="";
content=link.attr("title");
if(content.isEmpty())
{
content=link.text();
if((content.isEmpty()))
{
continue;
}
}
if(content.length()>5)
{
continue;
}
this.list.add(content);
}
//添加到redis数据库
jedis_content.AddToVisitTitle(list);
}
}
public class DownloadHtml {
private String downloadresult;
public void StartDownload(String download_url) throws InterruptedException {
System.setProperty("webdriver.chrome.driver", "G:\\Tools\\chromedriver.exe");// 相当于一个静态变量 ,存在内存里面!
ChromeOptions option = new ChromeOptions();
option.setBinary("D:/Google/Chrome/Application/chrome.exe");
option.setHeadless(true);
WebDriver driver = new ChromeDriver(option);
driver.manage().window().maximize();
driver.manage().timeouts().implicitlyWait(5, TimeUnit.SECONDS);//
// 全局等待元素TimeUnit.SECONDS 线程
// JavascriptExecutor js = (JavascriptExecutor) driver;
driver.get(download_url);
// js.executeScript("window.scrollTo(0,document.body.scrollHeight)");
Thread.sleep(3000);
Actions action=new Actions(driver);
/*模拟鼠标移动到该元素上*/
action.moveToElement(driver.findElement(By.xpath("//div[@id='J_cate']/ul/li/a"))).perform();
try {
Thread.sleep(3000);
downloadresult=driver.getPageSource();
} catch (Exception e) {
e.printStackTrace();
}
finally
{
driver.quit();
System.out.println("已关闭3");
}
}
//该方法调用StartDownload()函数
public String GetDownload_html(String download_url) throws InterruptedException {
this.StartDownload(download_url);
return this.downloadresult;
}
}
redis数据库执行结果如下图

2、经过第一步的实现,将所有类别都加入了Redis数据库。使用生产者-消费者模型对数据进行精细处理。
解释1:当生产者的待处理队列不为空时,进行生产者睡眠,这时消费开始处理队列反之,当待处理队列为空时,生产者运行,存储数据到待处理队列 。
解释2:使用Future处理,防止中断,或者使用try–catch–finally进行代替。
(1)生产者从redis数据库中获取一个分类信息,使用selenium自动测试模拟输入商品类别并模拟点击“搜索按钮”以获取当前url,再对该url进行拼接并存入到redis待处理队列中。具体看代码注释。

//生产者
public void produce() {
lock.lock();
try {
//待处理队列非空,则睡眠
while (!base.ToVisitEmpty()) {
System.out.println("生产者" + Thread.currentThread().getName() + " waiting");
condition.await();
}
// while (!base.ToVisitEmptyTitle()) {
// 获取数据
ExecutorService executor = Executors.newSingleThreadExecutor();
//FutureTask处理,预防中断代码的执行。这个代码不是很好。
FutureTask<String> future = new FutureTask<String>(new Callable<String>() {
// 使用Callable接口作为构造参数
@Override
public String call() throws IOException {
//获取一个分类信息
String title = base.GetToVisitedTitle();
//添加到已访问的分类数据队列
base.AddVisitedTitle(title);
// 字符串拼接
pingjie.geturl(title);
Long length1 = jedis.llen("toVisitTitle");
Long length2 = jedis.llen("toVisit");
System.out.println("toVisitTitle当前长度:" + length1);
System.out.println("toVisit当前长度:" + length2);
return "执行成功";
}
});
executor.execute(future);
try {
String result = future.get(3000, TimeUnit.MILLISECONDS); // 取得结果,同时设置超时执行时间为5秒。同样可以用future.get(),不设置执行超时时间取得结果
System.out.println(result);
} catch (InterruptedException e) {
System.out.println("produceInterruptedException:error");
} catch (ExecutionException e) {
System.out.println("produceExecutionException:error");
} catch (TimeoutException e) {
System.out.println("produceTimeoutException:error");
} finally {
executor.shutdown();
}
// }
condition.signalAll();
System.out.println("消费者" + Thread.currentThread().getName() + " Runnable");
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
package runmain;
import java.util.LinkedList;
import java.util.concurrent.TimeUnit;
import javax.servlet.ServletContext;
import javax.servlet.http.HttpSession;
import org.openqa.selenium.By;
import org.openqa.selenium.WebDriver;
import org.openqa.selenium.chrome.ChromeDriver;
import org.openqa.selenium.chrome.ChromeOptions;
import org.openqa.selenium.support.ui.ExpectedConditions;
import org.openqa.selenium.support.ui.WebDriverWait;
import analysis.AnalysisUrl;
import analysis.AnalysisPage;
import database.redis.RedisBase;
import downloader.DownloadTitleHtml;
/**
* 创建时间:2019年1月19日 上午10:05:25
* 项目名称:integration_zhong
* @author 王锋洲
* @version 1.0
* @since JDK 1.8
* 文件名称:String_pingjie.java
* 类说明: 拼接url,调用的类库有 AnalysisUrl,AnalysisPage,RedisBase,DownloadTitleHtml
*/
public class StringGetAllUrl
{
AnalysisPage ana_page=new AnalysisPage();
//下载页面
DownloadTitleHtml down_html=new DownloadTitleHtml();
//rdis数据库操作
RedisBase base = new RedisBase();
//解析页面
AnalysisUrl anaurl=new AnalysisUrl();
//传递要处理的分类数据,进行拼接操作
public void geturl(String title)
{
System.out.println("解析当前url");
String currenturl=anaurl.AnalysisCurrentUrl(title);
System.out.println("currenturl"+currenturl);
//生产者中对url进行截取与拼接,以产生不同的页码对应的不同url
String[] str1 = currenturl.split("&");
String url1 = str1[0] + "&" + str1[1]+"&page=";
System.out.println("解析当前页面页数");
int n=ana_page.GetPage(down_html.GetTitleHtml(title));
//该拼接方式不完善,会漏抓数据,请改进或者使用selenium一页一页的模拟点击
for(int i=1;i<=n*2;i++)
{
String url2=url1+i;
//加入到redis数据库中
base.AddToVisit(url2);
//System.out.println("插入成功");
i++;
}
}
}
//获取当前url并返回,该方法在上面被调用
public String AnalysisCurrentUrl(String title)
{
String current_url ="";
System.setProperty("webdriver.chrome.driver", "G:\\Tools\\chromedriver.exe");// 相当于一个静态变量 ,存在内存里面!
ChromeOptions option = new ChromeOptions();
option.setBinary("D:/Google/Chrome/Application/chrome.exe");
option.setHeadless(true);
WebDriver driver = new ChromeDriver(option);
driver.manage().window().maximize();
driver.manage().timeouts().implicitlyWait(7, TimeUnit.SECONDS);// 全局等待元素TimeUnit.SECONDS 线程
String url = "https://www.jd.com/";
try
{
driver.get(url);
}
catch(Exception ew)
{
ew.printStackTrace();
}
WebDriverWait webDriverWait = new WebDriverWait(driver, 5);
webDriverWait.until(ExpectedConditions.elementToBeClickable(By.id("key"))).sendKeys(title);
webDriverWait.until(ExpectedConditions.elementToBeClickable(By.xpath("//div[@id='search']/div/div[2]/button"))).click();
try {
Thread.sleep(5000);
current_url = driver.getCurrentUrl();
} catch (InterruptedException e1) {
e1.printStackTrace();
}
driver.quit();
System.out.println("已关闭1");
try {
current_url = new String(current_url.getBytes("iso-8859-1"), "utf-8");
} catch (UnsupportedEncodingException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
return current_url;
}
//获取页面的html代码
public String GetTitleHtml(String title) {
String downloadresult = "";
try {
System.out.println("GetTitleHtml");
System.setProperty("webdriver.chrome.driver", "G:\\Tools\\chromedriver.exe");// 相当于一个静态变量 ,存在内存里面!
ChromeOptions option = new ChromeOptions();
option.setBinary("D:/Google/Chrome/Application/chrome.exe");
option.setHeadless(true);
WebDriver driver = new ChromeDriver(option);
driver.manage().window().maximize();
driver.manage().timeouts().implicitlyWait(5, TimeUnit.SECONDS);// 全局等待元素TimeUnit.SECONDS 线程
String url = "https://www.jd.com/";
try
{
Thread.sleep(2000);
driver.get(url);//时间超时
}
catch(Exception e)
{
e.printStackTrace();
}
WebDriverWait webDriverWait = new WebDriverWait(driver, 5);
webDriverWait.until(ExpectedConditions.elementToBeClickable(By.id("key"))).sendKeys(title);
webDriverWait
.until(ExpectedConditions.elementToBeClickable(By.xpath("//div[@id='search']/div/div[2]/button")))
.click();
try {
Thread.sleep(3000);
downloadresult = driver.getPageSource();//时间超时
} catch (Exception e1) {
e1.printStackTrace();
}
driver.quit();
System.out.println("已关闭2");
} catch (Exception e) {
e.printStackTrace();
}
return downloadresult;
}
//解析当前页面的html代码以获取页码并返回
public int GetPage(String result)
{
Document doc=Jsoup.parse(result);
String link=doc.getElementById("J_topPage").select("span[class=fp-text]").select("i").text();
if(link.isEmpty())
{
return 0;
}
return Integer.parseInt(link);
}
(2)消费者从待处理队列中取出url(用多线程)对该url进行获取页面数据->解析要获取的数据->存入到mongodb数据库过程。具体看代码注释。
//消费者
public void consumer() {
lock.lock();
try {
//当待处理队列为空则该线程睡眠
while (base.ToVisitEmpty()) {
System.out.println("消费者" + Thread.currentThread().getName() + " waiting");
condition.await();
}
//当待处理队列非空时一直处理直到处理完毕
while (!base.ToVisitEmpty()) {
ExecutorService executor = Executors.newSingleThreadExecutor();
FutureTask<String> future = new FutureTask<String>(new Callable<String>() {
// 使用Callable接口作为构造参数
@Override
public String call() throws IOException, InterruptedException {
// 从数据库中取数据读取链接
String aimurl = base.GetToVisit();
String aimhtml = "";
// 下载aimurl的全部的HTML资源用于解析数据,这里和上面的的方法大体一样,就不一一赘述了
aimhtml = get.GetAllHtml_aimurl(aimurl);
//解析数据并存到mongodb数据库,看下面代码
ana_value.deal_download_result(aimhtml);
System.out.println("ana_value");
System.out.println("aimurl:" + aimurl);
//添加到已处理队列
base.AddVisited(aimurl);
return "执行成功";
}
});
executor.execute(future);
// 在这里可以做别的任何事情
try {
String result = future.get(3000, TimeUnit.MILLISECONDS);
// 取得结果,同时设置超时执行时间为5秒。同样可以用future.get(),不设置执行超时时间取得结果
System.out.println(result);
} catch (InterruptedException e) {
System.out.println("consumerInterruptedException:error");
} catch (ExecutionException e) {
System.out.println("consumerExecutionException:error");
} catch (TimeoutException e) {
System.out.println("consumerTimeoutException:error");
} finally {
executor.shutdown();
}
}
//唤醒线程
condition.signalAll();
System.out.println("生产者" + Thread.currentThread().getName() + " Runnable");
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
lock.unlock();
}
}
//处理解析数据存入mongodb数据库
public void deal_download_result(String downloadresult) {
List<org.bson.Document> data = new ArrayList<org.bson.Document>();
//使用jsoup解析,可以用正则替代,xpath也可以
Document doc = Jsoup.parse(downloadresult);
Elements elements = doc.select("ul[class=gl-warp clearfix]").select("li[class=gl-item]");
String name = "";
String price = "";
String publish = "";
String href = "";
String Textcommit = "";
String commith = "";
for (Element ele : elements) {
id++;
name = ele.select("div[class=p-name p-name-type-2]").select("a").select("em").text();
price = ele.select("div[class=p-price]").select("strong").select("i").text().trim();
publish = ele.select("div[class=p-shop]").select("a").attr("title");
href = ele.select("div[class=p-name p-name-type-2]").select("a").attr("href");
Textcommit = ele.select("div[class=p-commit]").select("strong").select("a").text();
commith = ele.select("div[class=p-commit]").select("strong").select("a").attr("href");
if (publish.isEmpty()) {
publish = "未知出版社";
}
org.bson.Document document = new org.bson.Document("name", name)
.append("price", price)
.append("publish", publish)
.append("href", href)
.append("Textcommit", Textcommit)
.append("commith", commith);
data.add(document);
}
BatchData bachdata=new BatchData();
bachdata.data_batch(data);
完整代码:https://gitee.com/zfenghan/internet_worm.git