java类加载及双亲委派机制
目录
类加载流程
1、加载
2、验证
3、准备
4、解析
5、初始化
双亲委派模型
常见异常
NoClassDefFoundError
ClassNotFoundException
ClassCastException
线程上下文类加载器
JIT
编译器
谁被编译了?
触发条件
当我们第一次使用该类的时候,如果该类还未被加载到内存,则系统会通过加载-连接-初始化来实现这个类的初始化。其中连接又分为:验证,准备和解析三步。所以一个类被加载到jvm其生命周期包括以下7个阶段。类加载包括前5个阶段。具体流程如下:
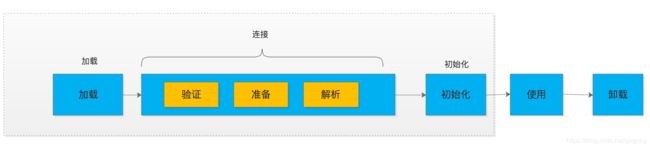 类加载过程
类加载过程
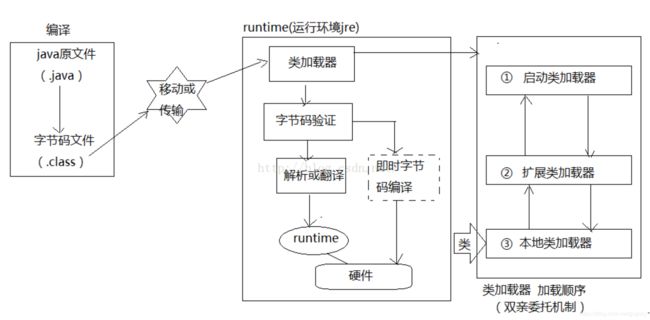 类加载流程图
类加载流程图
类加载流程
类加载器的任务就是根据一个类的全限定名来读取此类的二进制字节流到JVM中,然后转换为一个与目标类对应的java.lang.Class对象实例。具体流程如下:
1、加载
- 通过一个类的全限定名来获取此类的二进制字节流;
- 将字节流代表的静态存储结构转换为方法区的运行时数据结构;
- 在内存中创建一个代表此类的java.lang.Class对象,作为方法区此类的'各种数据的访问入口;
2、验证
- 格式验证:验证是否符合class文件规范
- 语义验证:检查一个被标记为final的类型是否包含子类;检查一个类中的final方法是否被子类进行重写;确保父类和子类之间没有不兼容的一些方法声明(比如方法签名相同,但方法的返回值不同)
- 操作验证:在操作数栈中的数据必须进行正确的操作,对常量池中的各种符号引用执行验证(通常在解析阶段执行,检查是否可以通过符号引用中描述的全限定名定位到指定类型上,以及类成员信息的访问修饰符是否允许访问等)
3、准备
- 为类中的所有静态变量分配内存空间,并为其设置一个初始值(由于还没有产生对象,实例变量不在此操作范围内)
- 被final修饰的static变量(常量),会直接赋值;
4、解析
- 将常量池中的符号引用转为直接引用(得到类或者字段、方法在内存中的指针或者偏移量,以便直接调用该方法),这个可以在初始化之后再执行。
- 解析需要静态绑定的内容。静态绑定包括一些final方法(不可以重写),static方法(只会属于当前类),构造器(不会被重写)
5、初始化
- 为静态变量赋值
- 执行static代码块【static代码块只有jvm能够调用】
- 如果是多线程需要同时初始化一个类,仅仅只能允许其中一个线程对其执行初始化操作,其余线程必须等待,只有在活动线程执行完对类的初始化操作之后,才会通知正在等待的其他线程。
因为子类存在对父类的依赖,所以类的加载顺序是先加载父类后加载子类,初始化也一样。不过,父类初始化时,子类静态变量的值也是有的,是默认值。
- 最终,方法区会存储当前类类信息,包括类的静态变量、类初始化代码(定义静态变量时的赋值语句 和 静态初始化代码块)、实例变量定义、实例初始化代码(定义实例变量时的赋值语句实例代码块和构造方法)和实例方法,还有父类的类信息引用
类加载(初始化)时机
- 创建类的实例
- 访问类的静态变量或者为静态变量赋值
- 调用类的静态方法
- 使用反射方法来强制创建某个类或接口对应的java.lang.Class对象
- 初始化某个类的子类
- 直接使用java.exe命令来运行某个主类
双亲委派模型
- 当前ClassLoader首先从自己已经加载的类中查询是否此类已经加载,如果已经加载则直接返回原来已经加载的类。每个类加载器都有自己的加载缓存,当一个类被加载了以后就会放入缓存,等下次加载的时候就可以直接返回了。
- 当前classLoader的缓存中没有找到被加载的类的时候,委托父类加载器去加载,父类加载器采用同样的策略,首先查看自己的缓存,然后委托父类的父类去加载,一直到bootstrp ClassLoader.
- 当所有的父类加载器都没有加载的时候,再由当前的类加载器加载,并将其放入它自己的缓存中,以便下次有加载请求的时候直接返回。
流程如下图所示:
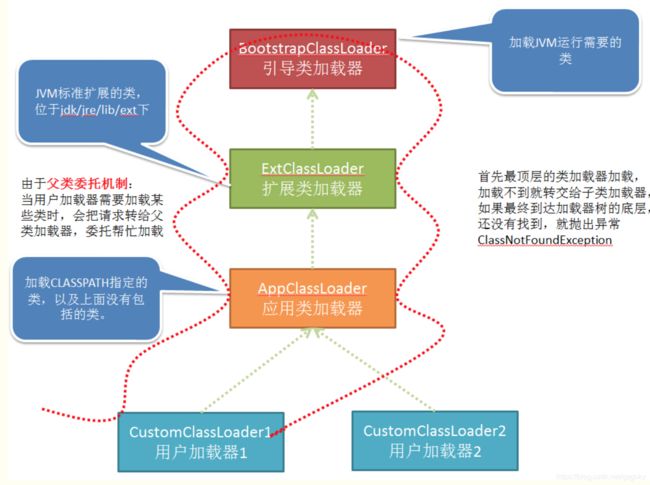
这里我们可以通过getParent()来返回该类的父类加载器。
public class ClassLoadTest {
public static void main(String[] args) {
try {
System.out.println(ClassLoader.getSystemClassLoader());
System.out.println(ClassLoader.getSystemClassLoader().getParent());
System.out.println(ClassLoader.getSystemClassLoader().getParent().getParent());
} catch (Exception e) {
e.printStackTrace();
}
}
}得到的结果如下:
sun.misc.Launcher$AppClassLoader@18b4aac2
sun.misc.Launcher$ExtClassLoader@312b1dae
null
Process finished with exit code 0正常的期望值是:系统类加载器的父类 -> 扩展类加载器 -> 启动类加载器,但是这里扩展类的父类不是启动类加载器?看了下源码:
public Class loadClass(String name) throws ClassNotFoundException {
return loadClass(name, false);
}
protected synchronized Class loadClass(String name, boolean resolve)
throws ClassNotFoundException {
// 首先判断该类型是否已经被加载
Class c = findLoadedClass(name);
if (c == null) {
//如果没被加载,就委托给父类加载或者委派给启动类加载器加载
try {
if (parent != null) {
//如果存在父类加载器,就委派给父类加载器加载
c = parent.loadClass(name, false);
} else {
//如果不存在父类加载器,就通过启动类加载器加载该类,
//通过调用本地方法native findBootstrapClass0(String name)
c = findBootstrapClass0(name);
}
} catch (ClassNotFoundException e) {
// 如果父类加载器和启动类加载器都不能完成加载任务,才调用自身的加载功能
c = findClass(name);
}
}
if (resolve) {
resolveClass(c);
}
return c;
}通过代码可以知道,如果发现某个类没有被加载,且当前的父加载类为空则会调用启动类加载器去加载,当启动类加载器也加载失败的时候,才会调用自定义的加载器。所以扩展类设置为null和设置启动类为父类是一样的,返回为null也就正常类。
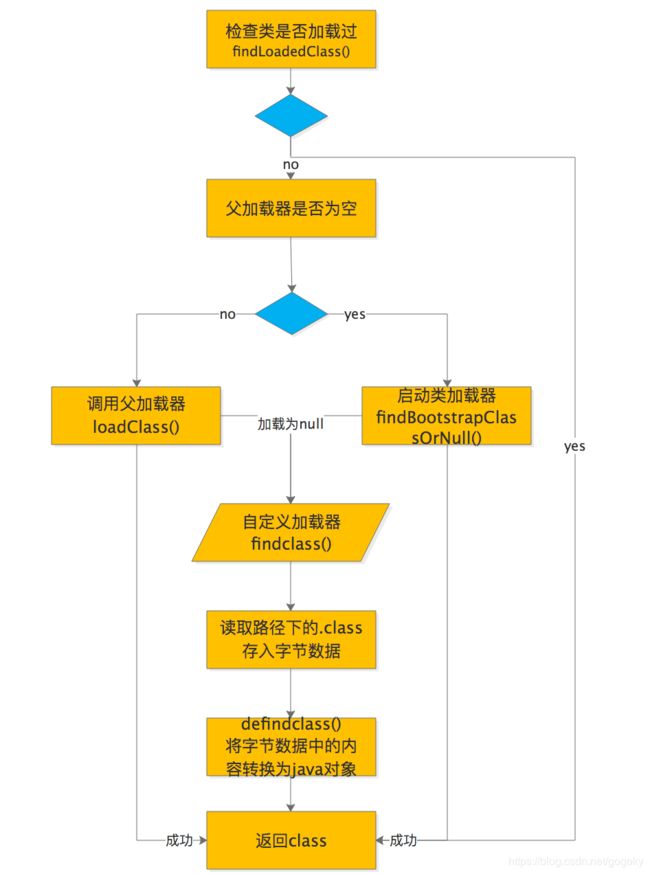 双亲委派流程
双亲委派流程
“双亲委派”机制只是Java推荐的机制,并不是强制的机制。从虚拟机的角度来说,只存在两种类加载器:一种是启动类加载器(Bootstrap ClassLoader),该类加载器使用C++语言实现,属于虚拟机自身的一部分。另外一种就是所有其它的类加载器,这些类加载器是由Java语言实现,独立于JVM外部,并且全部继承自抽象类java.lang.ClassLoader。
我们可以继承java.lang.ClassLoader类,实现自己的类加载器。如果想保持双亲委派模型,就应该重写findClass(name)方法;如果想破坏双亲委派模型,可以重写loadClass(name)方法
双亲委派模型的好处:
- 能够有效确保一个类的全局唯一性;【当程序中出现多个限定名相同的类时,类加载器在执行加载时,始终只会加载其中的某一个类】
- 避免类加载恶意代码,信任机制,保证类 Java 核心库的类型安全。【例如如果自己去编写一个与rt.jar类库中已有类重名的Java类(java.lang.Object),将会发现可以正常编译,但永远无法被加载运行。】
- 分层思想
另外:(1)父加载器中加载的类对于所有子加载器可见 (2)子类之间各自加载的类对于各自是不可间的(达到隔离效果)
常见异常
NoClassDefFoundError
我们知道类加载器采用的是双亲委派原则,类加载器会首先代理给其它类加载器来尝试加载某个类。这就意味着真正完成类的加载工作的类加载器和启动这个加载过程的类加载器,可能不是同一个。真正完成类的加载工作是通过调用 defineClass来实现的;而启动类的加载过程是通过调用 loadClass来实现的。前者称为一个类的定义加载器(defining loader),后者称为初始加载器(initiating loader)。在 Java 虚拟机判断两个类是否相同的时候,使用的是类的定义加载器。也就是说,哪个类加载器启动类的加载过程并不重要,重要的是最终定义这个类的加载器。两种类加载器的关联之处在于:一个类的定义加载器是它引用的其它类的初始加载器。如类 com.example.Outer引用了类 com.example.Inner,则由类 com.example.Outer的定义加载器负责启动类 com.example.Inner的加载过程。 java.lang.ClassNotFoundException是被loadClass()抛出的, java.lang.NoClassDefFoundError是被defineClass()抛出。
类加载器在成功加载某个类之后,会把得到的 java.lang.Class类的实例缓存起来。下次再请求加载该类的时候,类加载器会直接使用缓存的类的实例,而不会尝试再次加载。也就是说,对于一个类加载器实例来说,相同全名的类只加载一次,即 loadClass方法不会被重复调用。
loadClass()是来启动类的加载过程的,其源代码在前面我们已经分析过,即当父加载器不为null同时不能完成加载请求的情况下会抛出ClassNotFoundException异常,而导致父加载器无法完成加载的一个原因很简单就是找不到这个类,通常这种情况是传入的类的字符串名称书写错误,如调用class.forName(String name)或者loadClass(String name)时传入了一个错误的类的名称导致类加载器无法找到这个类。
ClassNotFoundException
defineClass()是用来完成类的加载工作的,此时已经表明类加载的启动已经完成了,即当前执行的类已经编译,但运行时找不到它的定义时就会抛出NoClassDefFoundError异常,这种情况通常出现在创建一个对象实例的时候(creating a new instance),如在类X中定义了一个类Y,如在类X中定义如下语句ClassY y=new ClassY; 程序运行成功之后(此时X与Y的字节码文件已经存在),如果将类Y的字节码文件删除了重新运行上述代码,则会在运行时候抛出NoClassDefFoundError异常。当然这只是为了说明抛出这种异常的原因,一般不会出现删除该类字节码情况,实际上是其它原因导致类似删除的效果导致的,如JAR重复引入,版本不一致导至。因为jar中都是一些已经编译好的Class文件,如果存在多个版本那么在加载的时候就不知道应该调用哪一个版本(相当于删除字节码的效果),此种情况一般出现在引入第三方SDK的时候。
总结:
| ClassNotFoundException | NoClassDefFoundError |
| 从java.lang.Exception继承,是一个Exception类型 | 从java.lang.Error继承,是一个Error类型 |
| 当动态加载Class的时候找不到类会抛出该异常 | 当编译成功以后执行过程中Class找不到导致抛出该错误 |
| 一般在执行Class.forName()、ClassLoader.loadClass()或ClassLoader.findSystemClass()的时候抛出 | 由JVM的运行时系统抛出 |
ClassNotFoundException发生在装入阶段。
当应用程序试图通过类的字符串名称,使用常规的三种方法装入类,但却找不到指定名称的类定义时就抛出该异常。
NoClassDefFoundError: 当目前执行的类已经编译,但是找不到它的定义时,发生连接阶段:
也就是说你如果编译了一个类B,在类A中调用,编译完成以后,你又删除掉B,运行A的时候那么就会出现这个错误
加载时从外存储器找不到需要的class就出现ClassNotFoundException
连接时从内存找不到需要的class就出现NoClassDefFoundError
ClassCastException
在jvm的世界里,确定是否是相同的一个类需要判断两个条件:类的全名 + 类加载器。如果一个相同的类,com.test.Sample,在通过不同的加载器加载后,如果相互赋值,则会出现ClassCastException的异常。
打破双亲委派机制
第一次:在双亲委派模型出现之前—–即JDK1.2发布之前。
第二次:模型自身缺点导致:
| 双亲委派模型的第二次“被破坏”是由这个模型自身的缺陷所导致的,双亲委派很好地解决了各个类加载器的基础类的统一问题(越基础的类由越上层的加载器进行加载),基础类之所以称为“基础”,是因为它们总是作为被用户代码调用的API,但世事往往没有绝对的完美,如果基础类又要调用回用户的代码,那该怎么办? 这并非是不可能的事情,一个典型的例子便是JNDI服务,JNDI现在已经是Java的标准服务,它的代码由启动类加载器去加载(在JDK 1.3时放进去的rt.jar),但JNDI的目的就是对资源进行集中管理和查找,它需要调用由独立厂商实现并部署在应用程序的ClassPath下的JNDI接口提供者(SPI,Service Provider Interface)的代码,但启动类加载器不可能“认识”这些代码啊!那该怎么办? 为了解决这个问题,Java设计团队只好引入了一个不太优雅的设计:线程上下文类加载器(Thread Context ClassLoader)。这个类加载器可以通过java.lang.Thread类的setContextClassLoaser()方法进行设置,如果创建线程时还未设置,它将会从父线程中继承一个,如果在应用程序的全局范围内都没有设置过的话,那这个类加载器默认就是应用程序类加载器。 有了线程上下文类加载器,就可以做一些“舞弊”的事情了,JNDI服务使用这个线程上下文类加载器去加载所需要的SPI代码,也就是父类加载器请求子类加载器去完成类加载的动作,这种行为实际上就是打通了双亲委派模型的层次结构来逆向使用类加载器,实际上已经违背了双亲委派模型的一般性原则,但这也是无可奈何的事情。Java中所有涉及SPI的加载动作基本上都采用这种方式,例如JNDI、JDBC、JCE、JAXB和JBI等。 |
第三次:为了实现热插拔,热部署,模块化,意思是添加一个功能或减去一个功能不用重启,只需要把这模块连同类加载器一起换掉就实现了代码的热替换。
线程上下文加载器的使用场景
- 当高层提供了统一接口让低层去实现,同时又要是在高层加载(或实例化)低层的类时,必须通过线程上下文类加载器来帮助高层的ClassLoader找到并加载该类。
- 当使用本类托管类加载,然而加载本类的ClassLoader未知时,为了隔离不同的调用者,可以取调用者各自的线程上下文类加载器代为托管。
JIT
JIT是just in time,即时编译技术。使用该技术,可以加速java程序的运行速度,是一种优化手段。
对于 Java 代码,刚开始都是被编译器编译成字节码文件,然后字节码文件会被交由 JVM 解释执行,所以可以说 Java 本身是一种半编译半解释执行的语言。为了进一步提高代码的执行速度,HotSpot VM的热点代码探测能力可以通过执行计数器找出最具有编译价值的代码,然后通知JIT编译器以方法为单位进行编译,提高优化。
编译器
HotSpot虚拟机内置了两个即时编译器:
- Client Compiler
C1编译器是一个简单快速的三段式编译器,主要关注“局部性能优化”,放弃许多耗时较长的全局优化手段 ;
过程:class -> 1. 高级中间代码 -> 2. 低级中间代码 -> 3. 机器代码
- Server Compiler
C2是专门面向服务器应用的编译器,是一个充分优化过的高级编译器,几乎能达到GNU C++编译器使用-O2参数时的优化强度。
谁被编译了?
两类热点代码
- 被多次调用的方法
- 一个方法被多次调用,理应称为热点代码,这种编译也是虚拟机中标准的JIT编译方式
- 被多次执行的循环体
- 编译动作由循环体出发,但编译对象依然会以整个方法为对象;
- 这种编译方式由于编译发生在方法执行过程中,因此形象的称为:栈上替换(On Stack Replacement- OSR编译,即方法栈帧还在栈上,方法就被替换了)
触发条件
判断一段代码是不是热点代码,是不是需要触发JIT编译,这样的行为称为:热点探测(Hot Spot Detection),有几种主流的探测方式:
-
基于计数器的热点探测(Counter Based Hot Spot Detection)
虚拟机会为每个方法(或每个代码块)建立计数器,统计执行次数,如果超过阀值那么就是热点代码。缺点是维护计数器开销。 -
基于采样的热点探测(Sample Based Hot Spot Detection)
虚拟机会周期性检查各个线程的栈顶,如果某个方法经常出现在栈顶,那么就是热点代码。缺点是不精确。 -
基于踪迹的热点探测(Trace Based Hot Spot Detection)
Dalvik中的JIT编译器使用这种方式
hotspot默认使用计数器的热点探测:
- 方法计数器
- 回边计数器
目前主流商用JVM都采用编译器和解释器并存的架构,但主流商用虚拟机,都同时包含这两部分。
-
当程序需要迅速启动然后执行的时候,解释器可以首先发挥作用,编译器不运行从而省去编译时间,立即执行程序;
-
在程序运行后,随着时间的推移,编译器逐渐发挥作用,把越来越多的代码编译成本地代码之后,可以获得更高的执行效率。
参考资料:
《深入理解jvm虚拟机》
https://blog.csdn.net/yangcheng33/article/details/52631940
https://blog.csdn.net/moakun/article/details/81257897
https://blog.csdn.net/weixin_39222112/article/details/81316511
https://blog.csdn.net/qq_26963433/article/details/78048561
https://www.cnblogs.com/xiaoxian1369/p/5498817.html
https://www.cnblogs.com/insistence/p/5901457.html
http://www.cnblogs.com/aspirant/p/8991830.html
https://blog.csdn.net/chen364567628/article/details/52561588
https://www.cnblogs.com/tinytiny/p/3200448.html
http://www.cnblogs.com/charlesblc/p/5993804.html