js中的内存管理
目录
前言
一、内存结构
二、对象及数组的存储
Object 存储
Array 存储
三、内存生命周期
四、垃圾回收
五、V8引擎内存限制
六、内存泄露
内存泄漏的识别方法
常见的内存泄露案例
如何避免内存泄漏
七、视图类型(连续内存)
八、参考
前言
像C语言这样的底层语言一般都有底层的内存管理接口,比如 malloc()和free()用于分配内存和释放内存。 而对于JavaScript来说,会在创建变量时分配内存,并且在不再使用它们时“自动”释放内存,这个自动释放内存的过程称为垃圾回收。 因为自动垃圾回收机制的存在,让大多Javascript开发者感觉他们可以不关心内存管理,所以会在一些情况下导致内存泄漏。
一、内存结构
内存分为堆(heap)和栈(stack),堆内存存储引用数据类型(Object, Array,Function...),栈内存则存储基本数据类型和引用类型的地址索引,方便快速写入和读取数据。在访问数据时,如果是引用数据类型,先从栈内寻找相应数据的存储地址,再根据获得的地址,找到堆内该变量真正存储的内容读取出来。
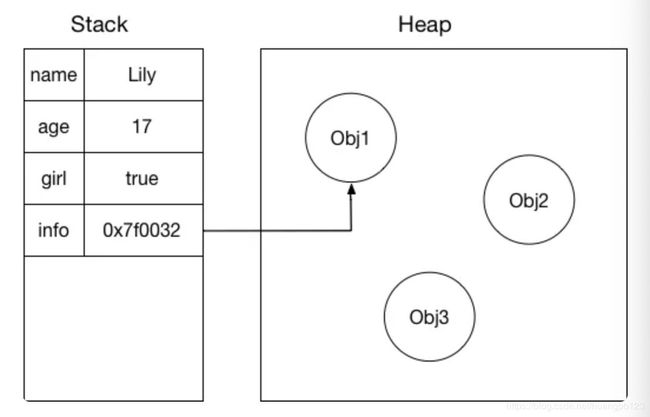
基本数据类型由于存储在栈中,读取写入速度相对引用类型(存在堆中)会更快些。
堆栈缓存方式
栈:一级缓存, 调用完毕立即释放。
堆:二级缓存,一般由程序员主动分配释放,如果没有主动释放会由虚拟机的垃圾回收算法来决定是否回收(并不是一旦成为孤儿对象就能被回收)。
二、对象及数组的存储
在JS中,一个对象可以任意添加和移除属性,似乎没有限制(实际上需要不能大于 2^32 个属性)。而JS中的数组,不仅是变长的,可以随意添加删除数组元素,每个元素的数据类型也可以完全不一样,更不一般的是,这个数组还可以像普通的对象一样,在上面挂载任意属性,这都是为什么呢?
Object 存储
首先了解一下,JS是如何存储一个对象的。
JS在设计复杂类型存储的时候面临的最直观的问题就是,选择一种数据结构,需要在读取,插入和删除三个方面都有较高的性能。
数组形式的结构,读取和顺序写入的速度最快,但插入和删除的效率都非常低下;
链表结构,移除和插入的效率非常高,但是读取效率过低,也不可取;
复杂一些的树结构等等,虽然不同的树结构有不同的优点,但都绕不过建树时较复杂,导致初始化效率低下;
综上所属,JS 选择了一个初始化,查询和插入删除都能有较好,但不是最好的性能的数据结构 -- 哈希表。
哈希表
哈希表存储是一种常见的数据结构。所谓哈希映射,是把任意长度的输入通过散列算法变换成固定长度的输出。
对于一个 JS 对象,每一个属性,都按照一定的哈希映射规则,映射到不同的存储地址上。在我们寻找该属性时,也是通过这个映射方式,找到存储位置。当然,这个映射算法一定不能过于复杂,这会使映射效率低下;但也不能太简单,过于简单的映射方式,会导致无法将变量均匀的映射到一片连续的存储空间内,而造成频繁的哈希碰撞。
对象生命周期
当创建一个对象时,JavaScript 会自动为该对象分配适当的内存。从这一刻起,垃圾回收器就会不断对该对象进行评估,以查看它是否仍是有效的对象。
垃圾回收器定期扫描对象,并计算引用了每个对象的其他对象的数量。如果一个对象的引用数量为 0(没有其他对象引用过该对象),或对该对象的惟一引用是循环的,那么该对象的内存即可回收。
Array 存储
JS 的数组为何也比其他语言的数组更加灵活呢?因为 JS 的 Array 的对象,就是一种特殊类型的数组!
所谓特殊类型,就是指在 Array 中,每一个属性的 key 就是这个属性的 index;而这个对象还有 .length 属性;还有 concat, slice, push, pop 等方法;
于是这就解释了:
-
为何 JS 的数组每个数据类型都可以不一样?因为他就是个对象,每条数据都是一个新分配的类型连入链表中;
-
为何 JS 的数组无需提前设置长度,是可变数组?答案同上;
-
为何数组可以像 Object 一样挂载任意属性?因为他就是个对象;
-
为何数组可以直接根据索引取得对应的元素,不管取第1个值还是第n个值的速度都是一样的(时间复杂度都是 O(1));
等等一系列的问题。
三、内存生命周期

JS 环境中分配的内存有如下生命周期:
- 内存分配:当我们声明变量、函数、对象的时候,系统会自动为他们分配内存
- 内存使用:即读写内存,也就是使用变量、函数等
- 内存回收:使用完毕,由垃圾回收机制自动回收不再使用的内存
JS 的内存分配
为了不让程序员费心分配内存,JavaScript 在定义变量时就完成了内存分配。
JS 的内存使用
使用值的过程实际上是对分配内存进行读取与写入的操作。 读取与写入可能是写入一个变量或者一个对象的属性值,甚至传递函数的参数。
var a = 10; // 分配内存
console.log(a); // 对内存的使用JS 的内存回收
JS 有自动垃圾回收机制,其原理是找出那些不再继续使用的值,然后释放其占用的内存。
不再需要使用的变量也就是生命周期结束的变量,是局部变量,局部变量只在函数的执行过程中存在, 当函数运行结束,没有其他引用(闭包),那么该变量会被标记回收。
全局变量的生命周期直至浏览器卸载页面才会结束,也就是说全局变量不会被当成垃圾回收。
四、垃圾回收
垃圾回收算法主要依赖于引用的概念。
例如,一个Javascript对象具有对它原型的引用(隐式引用)和对它属性的引用(显式引用)。
在这里,“对象”的概念不仅特指 JavaScript 对象,还包括函数作用域(或者全局词法作用域)。
引用计数垃圾收集
这是最初级的垃圾回收算法。
引用计数算法定义“内存不再使用”的标准很简单,就是看一个对象是否有指向它的引用。 如果没有其他对象指向它了,说明该对象已经不再需了。
var o = {
a: {
b:2
}
};
// 两个对象被创建,一个作为另一个的属性被引用,另一个被分配给变量o
// 很显然,没有一个可以被垃圾收集
var o2 = o; // o2变量是第二个对“这个对象”的引用
o = 1; // 现在,“这个对象”的原始引用o被o2替换了
var oa = o2.a; // 引用“这个对象”的a属性
// 现在,“这个对象”有两个引用了,一个是o2,一个是oa
o2 = "yo"; // 最初的对象现在已经是零引用了
// 他可以被垃圾回收了
// 然而它的属性a的对象还在被oa引用,所以还不能回收
oa = null; // a属性的那个对象现在也是零引用了
// 它可以被垃圾回收了由上面可以看出,引用计数算法是个简单有效的算法。但它却存在一个致命的问题:循环引用。
如果两个对象相互引用,尽管他们已不再使用,垃圾回收不会进行回收,导致内存泄露。
来看一个循环引用的例子:
function f(){
var o = {};
var o2 = {};
o.a = o2; // o 引用 o2
o2.a = o; // o2 引用 o 这里
return "azerty";
}
f();上面我们申明了一个函数 f ,其中包含两个相互引用的对象。 在调用函数结束后,对象 o1 和 o2 实际上已离开函数范围,因此不再需要了。 但根据引用计数的原则,他们之间的相互引用依然存在,因此这部分内存不会被回收,内存泄露不可避免了。
再来看一个实际的例子:
var div = document.createElement("div");
div.onclick = function() {
console.log("click");
};上面这种JS写法再普通不过了,创建一个DOM元素并绑定一个点击事件。 此时变量 div 有事件处理函数的引用,同时事件处理函数也有div的引用!(div变量可在函数内被访问)。 一个循序引用出现了,按上面所讲的算法,该部分内存无可避免的泄露了。
为了解决循环引用造成的问题,现代浏览器通过使用标记清除算法来实现垃圾回收。
标记清除算法
标记清除算法将“不再使用的对象”定义为“无法达到的对象”。 简单来说,就是从根部(在JS中就是全局对象)出发定时扫描内存中的对象。 凡是能从根部到达的对象,都是还需要使用的。 那些无法由根部出发触及到的对象被标记为不再使用,稍后进行回收。
工作流程:
- 垃圾收集器会在运行的时候会给存储在内存中的所有变量都加上标记。
- 从根部出发将能触及到的对象的标记清除。
- 那些还存在标记的变量被视为准备删除的变量。
- 最后垃圾收集器会执行最后一步内存清除的工作,销毁那些带标记的值并回收它们所占用的内存空间。
再看之前循环引用的例子:
function f(){
var o = {};
var o2 = {};
o.a = o2; // o 引用 o2
o2.a = o; // o2 引用 o
return "azerty";
}
f();函数调用返回之后,两个循环引用的对象在垃圾收集时从全局对象出发无法再获取他们的引用。 因此,他们将会被垃圾回收器回收。
五、V8引擎内存限制
谷歌浏览器的V8引擎只能使用系统的一部分内存,具体来说,在64位系统下,V8最多只能分配1.4G, 在 32 位系统中,最多只能分配0.7G。
V8 为什么要给它设置内存上限?明明我的机器大几十G的内存,只能让我用这么一点?
究其根本,是由两个因素所共同决定的,一个是JS单线程的执行机制,另一个是JS垃圾回收机制的限制。
首先JS是单线程运行的,这意味着一旦进入到垃圾回收,那么其它的各种运行逻辑都要暂停; 另一方面垃圾回收其实是非常耗时间的操作,V8 官方是这样形容的:
以 1.5GB 的垃圾回收堆内存为例,V8 做一次小的垃圾回收需要50ms 以上,做一次非增量式的垃圾回收甚至要 1s 以上。
可见其耗时之久,而且在这么长的时间内,我们的JS代码执行会一直没有响应,造成应用卡顿,导致应用性能和响应能力直线下降。因此,V8 做了一个简单粗暴的选择,那就是限制堆内存,也算是一种权衡的手段,因为大部分情况是不会遇到操作几个G内存这样的场景的。
不过,如果你想调整这个内存的限制也不是不行。配置命令如下:
// 这是调整老生代这部分的内存,单位是MB。后面会详细介绍新生代和老生代内存
node --max-old-space-size=2048 xxx.js V8 把堆内存分成了两部分进行处理——新生代内存和老生代内存。顾名思义,新生代就是临时分配的内存,存活时间短, 老生代是常驻内存,存活的时间长。V8 的堆内存,也就是两个内存之和。
六、内存泄露
内存泄漏,指任何对象在你不再拥有或需要它之后未能释放仍然存在,造成内存的浪费。
内存泄漏的识别方法
经验法则是,如果连续五次垃圾回收之后,内存占用一次比一次大,就有内存泄漏。 这就要求实时查看内存的占用情况。
在 Chrome 浏览器中,我们可以这样查看内存占用情况
- 打开开发者工具,选择 Performance 面板
- 在顶部勾选 Memory
- 点击左上角的 record 按钮
- 在页面上进行各种操作,模拟用户的使用情况
- 一段时间后,点击对话框的 stop 按钮,面板上就会显示这段时间的内存占用情况
来看一张效果图:

我们有两种方式来判定当前是否有内存泄漏:
- 多次快照后,比较每次快照中内存的占用情况,如果呈上升趋势,那么可以认为存在内存泄漏
- 某次快照后,看当前内存占用的趋势图,如果走势不平稳,呈上升趋势,那么可以认为存在内存泄漏
使用 Chrome 浏览器控制台 Memory 提供的 Heap Profile 管理内存
在服务器环境中使用 Node 提供的 process.memoryUsage 方法查看内存情况
console.log(process.memoryUsage());
// {
// rss: 27709440,
// heapTotal: 5685248,
// heapUsed: 3449392,
// external: 8772
// }process.memoryUsage返回一个对象,包含了 Node 进程的内存占用信息。
该对象包含四个字段,单位是字节,含义如下:
- rss(resident set size):所有内存占用,包括指令区和堆栈。
- heapTotal:"堆"占用的内存,包括用到的和没用到的。
- heapUsed:用到的堆的部分。
- external: V8 引擎内部的 C++ 对象占用的内存。
判断内存泄漏,以 heapUsed 字段为准。
常见的内存泄露案例
意外的全局变量
function foo() {
bar1 = 'some text'; // 没有声明变量 实际上是全局变量 => window.bar1
this.bar2 = 'some text' // 全局变量 => window.bar2
}
foo();被遗忘的定时器和回调函数
var serverData = loadData();
setInterval(function() {
var renderer = document.getElementById('renderer');
if(renderer) {
renderer.innerHTML = JSON.stringify(serverData);
}
}, 5000); // 每 5 秒调用一次如果后续 renderer 元素被移除,整个定时器实际上没有任何作用。 但如果你没有回收定时器,整个定时器依然有效, 不但定时器无法被内存回收, 定时器函数中的依赖也无法回收。在这个案例中的 serverData 也无法被回收。
闭包
在 JS 开发中,我们会经常用到闭包,一个内部函数,有权访问包含其的外部函数中的变量。 下面这种情况下,闭包也会造成内存泄露:
var theThing = null;
var replaceThing = function () {
var originalThing = theThing;
var unused = function () {
if (originalThing) // 对于 'originalThing'的引用
console.log("hi");
};
theThing = {
longStr: new Array(1000000).join('*'),
someMethod: function () {
console.log("message");
}
};
};
setInterval(replaceThing, 1000);这段代码,每次调用 replaceThing 时,theThing 获得了包含一个巨大的数组和一个对于新闭包 someMethod 的对象。 同时 unused 是一个引用了 originalThing 的闭包。
这个范例的关键在于,闭包之间是共享作用域的,尽管 unused 可能一直没有被调用,但是 someMethod 可能会被调用,就会导致无法对其内存进行回收。 当这段代码被反复执行时,内存会持续增长。
DOM 引用
很多时候, 我们对 Dom 的操作, 会把 Dom 的引用保存在一个数组或者 Map 中。
var elements = {
image: document.getElementById('image')
};
function doStuff() {
elements.image.src = 'http://example.com/image_name.png';
}
function removeImage() {
document.body.removeChild(document.getElementById('image'));
// 这个时候我们对于 #image 仍然有一个引用, Image 元素, 仍然无法被内存回收.
}上述案例中,即使我们对于 image 元素进行了移除,但是仍然有对 image 元素的引用,依然无法对齐进行内存回收。
另外需要注意的一个点是,对于一个 Dom 树的叶子节点的引用。 举个例子: 如果我们引用了一个表格中的td元素,一旦在 Dom 中删除了整个表格,我们直观的觉得内存回收应该回收除了被引用的 td 外的其他元素。 但是事实上,这个 td 元素是整个表格的一个子元素,并保留对于其父元素的引用。 这就会导致对于整个表格,都无法进行内存回收。所以我们要小心处理对于 Dom 元素的引用。
如何避免内存泄漏
记住一个原则:不用的东西,及时归还。
- 减少不必要的全局变量,使用严格模式避免意外创建全局变量。
- 在你使用完数据后,及时解除引用(闭包中的变量,dom引用,定时器清除)。
- 组织好你的逻辑,避免死循环等造成浏览器卡顿,崩溃的问题。
七、视图类型(连续内存)
通过上面的介绍可以知道,我们使用的数组实际上是伪数组。这种伪数组给我们的操作带来了极大的方便性,但这种实现方式也带来了另一个问题,及无法达到数组快速索引的极致,像文章开头时所说的上百万的数据量的情况下,每次新添加一条数据都需要动态分配内存空间,数据索引时都要遍历链表索引造成的性能浪费会变得异常的明显。
好在 ES6 中,JS 新提供了一种获得真正数组的方式:ArrayBuffer,TypedArray 和 DataView。
ArrayBuffer
ArrayBuffer 代表分配的一段定长的连续内存块。但是我们无法直接对该内存块进行操作,只能通过 TypedArray 和 DataView 来对其操作。
TypedArray
TypeArray 是一个统称,他包含 Int8Array / Int16Array / Int32Array / Float32Array等等。
DataView
DataView 相对 TypedArray 来说更加的灵活。每一个 TypedArray 数组的元素都是定长的数据类型,如 Int8Array 只能存储 Int8 类型;但是 DataView 却可以在传递一个 ArrayBuffer 后,动态分配每一个元素的长度,即存不同长度及类型的数据。
八、参考
- 前端内存优化的探索与实践
- 「前端进阶」JS中的内存管理
- 掘金:原生JS灵魂之问(下), 冲刺进阶最后一公里