超详细中文预训练模型ERNIE使用指南-源码
作者 | 高开远,上海交通大学,自然语言处理研究方向
最近在工作上处理的都是中文语料,也尝试了一些最近放出来的预训练模型(ERNIE,BERT-CHINESE,WWM-BERT-CHINESE),比对之后还是觉得百度的ERNIE效果会比较好,而且使用十分方便,所以今天就详细地记录一下。希望大家也都能在自己的项目上取得进展~
1、A Glance at ERNIE
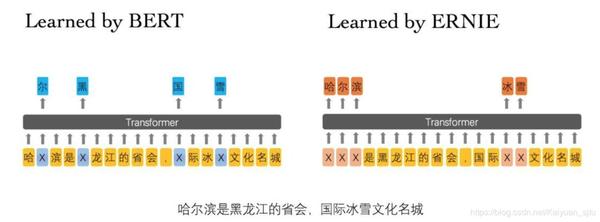

关于ERNIE模型本身的话这篇不会做过多介绍,网上的介绍文档也很多了,相信从事NLP的同学们肯定都非常熟悉啦。
2、ERNIE源码浅尝
Okay,当我们了解了ERNIE模型的大体框架及原理之后,接下来就可以深入理解一下具体的实现啦。ERNIE是基于百度自己的深度学习框架飞桨(PaddlePaddle)搭建的,(百度推这个飞桨的力度还是蛮大的,还开放了免费算力),大家平时炼丹用的更多的可能是TensorFlow和Pytorch,这里关于运行ERNIE的飞桨环境安装可以参考快速安装指南:
https://www.paddlepaddle.org.cn/#quick-start
2.1 关于输入
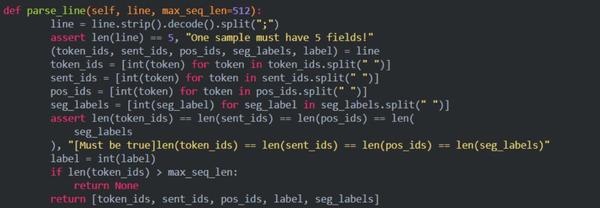
模型预训练的输入是基于百科类、资讯类、论坛对话类数据构造具有上下文关系的句子对数据,利用百度内部词法分析工具对句对数据进行字、词、实体等不同粒度的切分,然后基于 tokenization.py 中的 CharTokenizer 对切分后的数据进行 token 化处理,得到明文的 token 序列及切分边界,然后将明文数据根据词典config/vocab.txt 映射为 id 数据,在训练过程中,根据切分边界对连续的 token 进行随机 mask 操作。经过上述预处理之后的输入样例为:
11048 492 1333 1361 1051 326 2508 5 1803 1827 98 164 133 2777 2696 983 121 4 199 634 551 844 85 14 2476 1895 33 13 983 121 23 7 1093 24 46 660 12043 2 1263 6328 33 121 126 398 276 315 5 63 44 35 25 12043 2;0 0 0 0 0 0 0 0 0 0 0 0 0 0 00 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 11;0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 2829 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 5455;-1 0 0 0 0 1 0 1 0 0 1 0 0 1 0 1 0 0 0 0 0 0 1 0 1 0 0 1 0 1 0 0 0 0 1 0 0 00 -1 0 0 0 1 0 0 1 0 1 0 0 1 0 1 0 -1;0
一共有五个部分组成,每个部分之间用分号;隔开:
- token_ids:输入句子对的表示;
- sentence_type_ids:0或者1表示token属于哪一个句子;
- position_ids:绝对位置编码
- seg_labels:表示分词边界信息,0表示词首、1表示非词首、-1为占位符
- next_sentence_label:表示该句子对是否存在上下句的关系(0为无1为有)
reader.pretraining.py中的parse_line函数.

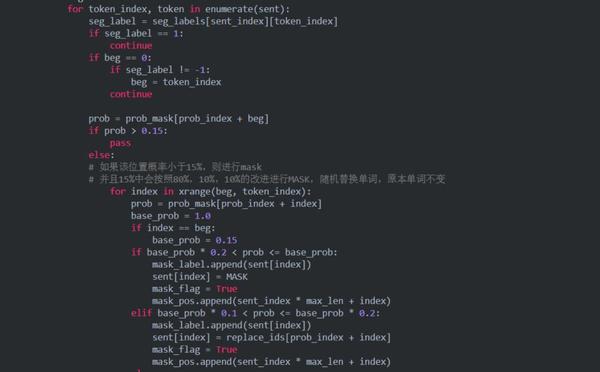
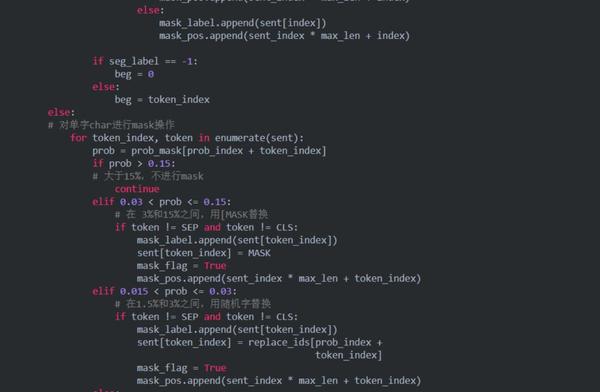
2.2 关于mask策略 batching.py
我们知道,相较于BERT,ERNIE最大的改进就是中文 + 短语/实体掩码(这个短语掩码的操作后来也被BERT采用训练出了WWM-BERT),所以我们首先来看看ERNIE的掩码机制是怎么样实现的。




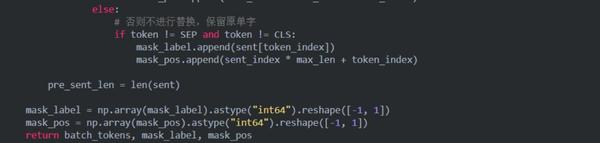

2.3 关于infer过程代码改写
ERNIE代码很方便使用,但是有一个不足的地方就是目前官方还没有给出infer.py文件,也就是模型训练之后给出快速推理结果的文件。Github上简直万人血书求接口呀。
所以我们的目的就是需要改写源码,完成这样一个接口:输入为我们需要预测的文件predict.tsv,调用接口后输出为相应任务的结果pred_result。下面我们以分类任务为例,改写一个infer接口。
Step 1. finetune下的classifier.py
在文件中完成predict函数
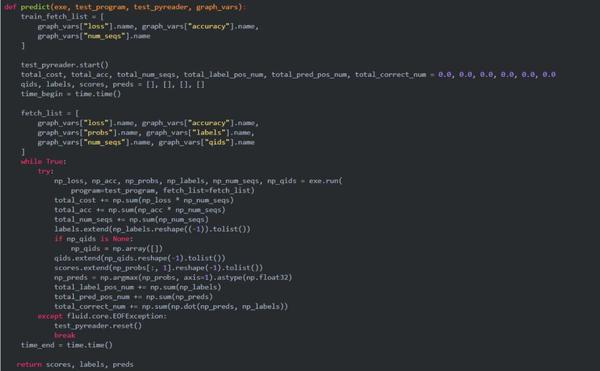

Step 2. run_classifier.py
修改predict_only=True时的逻辑
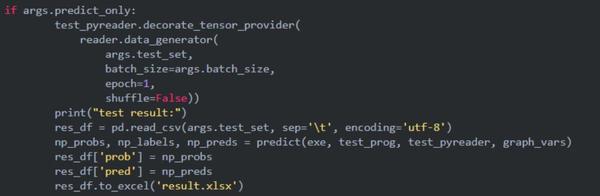

Step 3. finetune_args.py
在该文件中添加一个参数do_predict

OK, 篇幅有限后面还要介绍具体ERNIE实战,源码阅读部分就先这样,其实剩下的很多都跟BERT代码比较相似,感兴趣的同学也可以参考之前的 BERT源码分析系:https://blog.csdn.net/Kaiyuan_sjtu/article/details/90265473
3、ERNIE实战指南
上面扯的都是务虚的,接下来我们务实地来看看ERNIE这个预训练模型的具体应用。和BERT相比,ERNIE的使用更加简单,在之前介绍过的BERT模型实战之多文本分类(https://blog.csdn.net/Kaiyuan_sjtu/article/details/88709580)中,我们需要手动改写一个适应自己任务的Processor,而对于ERNIE来说,简单到只需要三步:
- 把数据准备成要求的格式(源码中使用tsv格式,不过在bert中我们也说过了,可以修改成各种格式的)
- 写一下训练脚本 run_script.sh
- 跑脚本得到结果 bashrun_script.sh
3.1 准备工作
对于最近大火的预训练模型来说,绝大多数我们是不太可能自己从头开始训练的,最多使用的是官方开源的模型进行特定任务的Finetune。所以第一步就是下载模型代码(https://github.com/PaddlePaddle/ERNIE/tree/develop/ERNIE
)以及相应的参数(https://baidu-nlp.bj.bcebos.com/ERNIE_stable-1.0.1.tar.gz)。
接下去就是准备我们任务的数据,使其符合ERNIE模型输入要求。一般来说字段之间都是label和text_a用制表符分割,对于句对任务还需要额外的text_b字段。在后面我们会具体介绍每种任务的示例输入。
ok,前面我们一直强调ERNIE是超友好上手超快的模型,下面我们结合实际任务来看一看到底有多简单~
3.2 情感分类
情感分类是属于非常典型的NLP基础任务之一,因为之前BERT写过文本分类,所以这里我们就稍微换一换口味~这里我们只考虑最简单情况的情感分类任务,即给定一个输入句子,要求模型给出一个情感标签,可以是只有正负的二分类,也可以是包括中性情感的三分类。ok,我们来看看数据,网上随便找了一个财经新闻数据集,数据来源于雪球网上万得资讯发布的正负面新闻标题,数据集中包含17149条新闻数据,包括日期、公司、代码、正/负面、标题、正文6个字段,其中正面新闻12514条,负面新闻4635条。大概长这样:


处理成ERNIE分类任务所需要的输入,大概长这样:


将处理完成的数据和前面下载好的预训练模型参数放置到合适的位置,就可以开始写我们跑模型的脚本文件了:
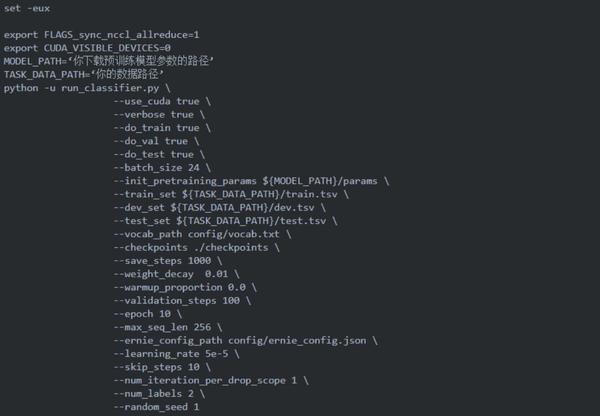

嗯,这样一个任务就结束了…运行脚本后等待输出结果即可,是不是很简单~
当然如果你还想玩点花样的话,就可以多看看论文。比如复旦之前有一篇文章是在BERT的基础上,将ABSA情感分类的单句分类任务转变成了句子对的相似度匹配任务。简单来说就是通过构建辅助句子,把输入这家餐馆的锅包肉超好吃变成了这家餐馆的锅包肉超好吃 + 菜品口感的情感是正的,论文表明这一trick是会比单句分类的效果更好。更具体的细节可以参考论文:《UtilizingBERT for Aspect-Based Sentiment Analysis via Constructing Auxiliary Sentence》(https://www.aclweb.org/anthology/N19-1035)。
3.3 命名实体识别
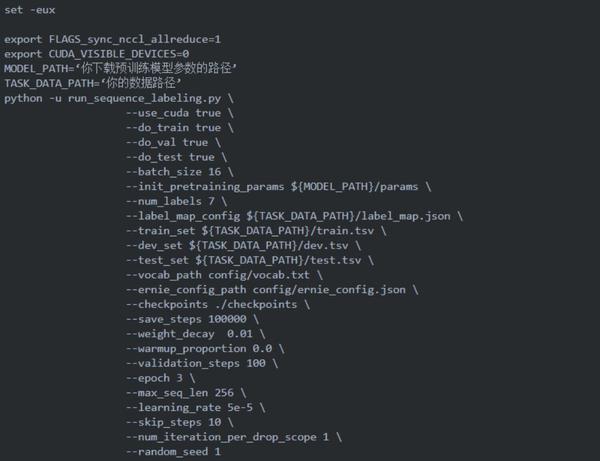
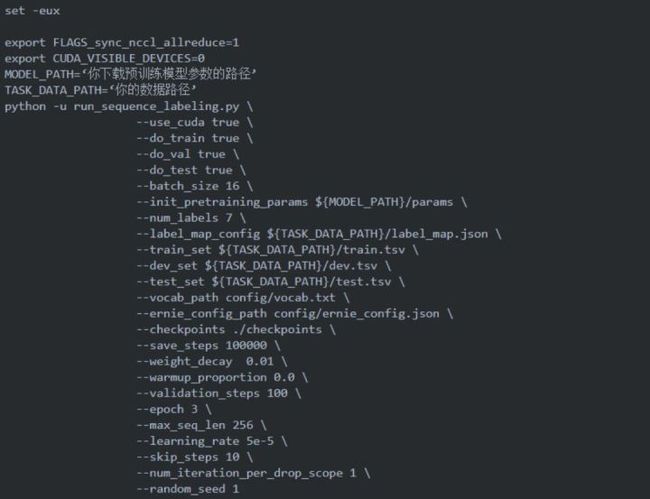
命名实体识别也是NLP的一个基础任务,之前在博客中也有过介绍:【论文笔记】命名实体识别论文(https://blog.csdn.net/Kaiyuan_sjtu/article/details/89143573)关于NER的处理思路也是跟上面情感分类的大同小异,只不过NER是属于序列标注任务,在运行脚本的时候注意使用源码中的run_senquence_labeling.py。
4、有趣的ISSUE
Github上比源码更有价值的是对应的issue,一个好的开源项目会吸引很多人的关注,issue区里会有很多有趣的思考,所以大家千万不要错过噢~下面就列几个我觉得比较有意思的issue供大家参考。
4.1 关于batch_size
https://github.com/PaddlePaddle/LARK/issues/4
刚打开ERNIE脚本打算跑的同学可能会发现,它的batch_size竟然是8192,我的天哪(小岳岳脸),这不得炸!于是乎你非常机智地把batch_size改为了32,美滋滋地输入bash script/pretrain.py,然后自信地敲下Enter键。嗯???报错???
报的什么错大家感兴趣的自己去复现吧~
对,在pretrain的时候这里的batch_size指的是所有输入token的总数,所以才会那么大~
4.2 关于Mask机制的逻辑
https://github.com/PaddlePaddle/LARK/issues/33
正如我开篇说的,ERNIE的最大创新就是它的mask机制,这一点的代码实现也在issue区被热烈讨论
4.3 关于获取输入的中间向量表示
https://github.com/PaddlePaddle/LARK/issues/41
有时候我们会需要获取句子Embedding 和 tokenEmbeddings,可参照下面的方案。


4.4 预测被masked的词
https://github.com/PaddlePaddle/LARK/issues/135
将一个句子的某个词语mask后,然后使用模型去预测这个词语,得到候选词和词语的概率
4.5. ERNIE模型部署
飞桨(PaddlePaddle)模型的部署可以在官方说明文档中找到
https://www.paddlepaddle.org.cn/documentation/docs/zh/1.4/advanced_usage/deploy/inference/index_cn.html
5、Some Tips
最后一部分打算说一下关于使用预训练模型的一些小tips:
- 学习率是第一种重要的参数,当你开始着手调参时优先从学习率开始。
- 根据你的任务来选择预训练模型。每个模型的训练大规模语料是不一样的,这就说明了有些模型天生就是更加适用于某个领域。
- 所有的预训练模型为了在尽可能多的下游任务上取得较好的效果,所使用的训练语料的覆盖范围都是非常大的,但这也带来了一个问题----过于general。也就是说如果你的任务所属domain与训练语料的相差较大,比如关于医学材料学之类的领域,反而不容易取得好的效果。所以我们可以在特定领域下尝试post-train预训练模型。
- 目前来说,对于中文领域的NLP任务,可以优先选择ERNIE。听小道消息说,ERNIE 2.0快出来了,据说效果很猛。
- 不要过分迷信预训练模型!!!
关于ERNIE的更多信息,可点击文末阅读原文或查看以下链接:
https://github.com/PaddlePaddle/ERNIE/tree/develop/ERNIE
Reference:
- 《Enhanced Representation through kNowledge IntEgration》:
https://arxiv.org/abs/1904.09223 - 《如何评价百度新发布的NLP预训练模型ERNIE?》:
https://www.zhihu.com/question/316140575 - 《中文任务全面超越 BERT:百度正式发布NLP预训练模型ERNIE》
https://www.jiqizhixin.com/articles/2019-03-16-3 - 官方源码:
https://www.jiqizhixin.com/articles/2019-03-16-3
