Hadoop-2.7.3环境搭建之伪分布式模式
#准备工作之环境变量的配置
##安装jdk
1.复制jdk-8u121-linux-x64.tar.gz 到 ~/Downloads目录下
$>cp jdk-8u121-linux-x64.tar.gz ~/Downloads
2.解压缩
$>tar -xzvf jdk-8u121-linux-x64.tar.gz
3.在根目录下建立目录/soft
$>sudo mkdir /soft
注:将所有相关的安装软件放入/soft文件夹内
4.改变/soft文件夹的拥有者
$>sudo chown ubuntu:ubuntu /soft
注:ubuntu:ubuntu分别代表用户与组,每个人视自己的情况而定
5.将解压之后的文件夹移动到/soft
$>mv ~/Downloads/jdk-8u121 /soft/
进入到jdk的/bin目录,查看java是否安装成功
$>./java -version
[创建符号链接]
$>ln -s /soft/jdk-8u121 jdk
6.配置环境变量
若为当前用户配置环境变量,可以在/.bashrc或/.profile中配置
若为系统配置环境变量则:[/etc/environment]
注:前者切换用户之后会失效,后者不管哪个用户都有效
JAVA_HOME=/soft/jdk
PATH="...:/soft/jdk/bin"
7.让环境变量生效
$>source /etc/environment
8.在/soft/jdk目录下查看JAVA_HOME
$>echo $JAVA_HOME
9.检验安装是否成功
$>cd ~
$>java -version
##安装hadoop
1.复制并解压hadoop-2.7.3.tar.gz
$>cp hadoop-2.7.3.tar.gz ~/Downloads
$>tar -xzvf hadoop-2.7.3.tar.gz
2.移动到/soft文件夹下
$>mv ~/Downloads/hadoop-2.7.3 /soft/
创建符号链接
$>ln -s /soft/hadoop-2.7.3 hadoop
3.进入到/hadoop2.7.3/bin下检验hadoop是否安装成功
$>./hadoop version
4.配置环境变量
hadoop文件夹中的/bin与/sbin文件夹都必须配置到PATH路径中去
$>sudo vi /etc/environment
HADOOP_HOME = /soft/hadoop
PATH="...:/soft/hadoop/bin:/soft/hadoop/sbin"
注:用冒号进行分割
5.让环境变量生效
$>source /etc/environment
6.在/soft/hadoop目录下查看HADOOP_HOME
$>echo $HADOOP_HOME
7.检验安装是否成功
$>hadoop version
#伪分布式搭建
##配置SSH
1.安装ssh
$>sudo apt-get install ssh
2.生成公钥、私钥对
$>ssh-keygen -t rsa -P '' -f ~/.ssh/id_rsa
ssh-keygen秘钥生成指令 -t rsa为rsa算法 -p为密码 -f为文件,生成的秘钥存在目录~/.ssh/id_rsa
$>cd ~/.ssh
$>ls -al 查看私钥和公钥 pub为公钥,另一个为私钥
3.导入公钥数据到授权库keys中,实现无密登陆
$>cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
因为伪分布式也需要无密登录,但是工作方式并没有变,导入到密钥库
authorized_keys内容与id_rsa.pub一样
4.登陆到localhost
$>ssh localhost
跳出,填yes,登陆成功之后,退出
$>exit
再度登陆,不需要密码
$>ssh localhost
##配置文件的修改
进入/hadoop/etc/hadoop目录下:
1.core-site.xml
fs.defaultFS
hdfs://localhost/ 注:默认端口8020
2.hdfs-site.xml
fs.replication 注:replication:副本,副本数为1 因为是伪分布模式,只有一个节点所以值为1;默认值为3
1
3.mapred-site.xml
因为没有mapred-site.xml这个文件,因此执行命令:
$>cp mapred-site.xml.template mapred-site.xml
mapreduce.framework.name
yarn 注:framework为框架的意思,框架的名字起名为yarn
4.yarn-site.xml
yarn.resourcemanager.hostname
localhost 注:资源管理器的主机名为localhost
yarn.nodemanager.aux-services
mapreduce_shuffle
##启动hadoop
注:hadoop启动之后生成的文件均保存在了临时目录/tmp下,因此每次重新启动之前就需要格式化一回;可在配置文件里配置,这里并没有配置,在后续的文章里会进行介绍
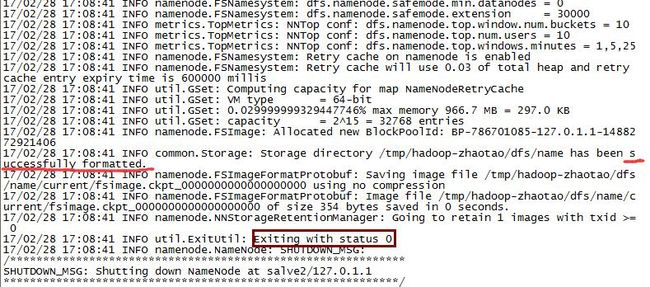
1.格式化hdfs文件系统
$>hadoop namenode -format
成功截图:
2.启动所有进程
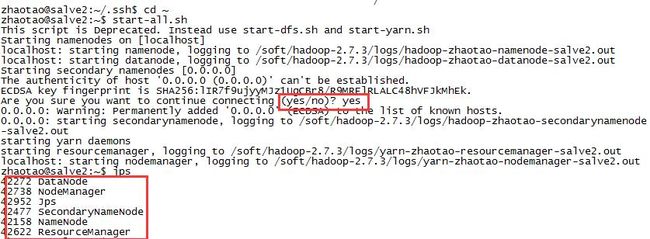
$>start-all.sh
位置在hadoop/sbin/start-all.sh
3.查看进程
$>jps
成功截图:
4.查看文件系统
$>hadoop fs -ls /
5.创建文件系统
$>hadoop fs -mkdir -p /user/lemon/data
$>hadoop fs -ls -R / 采用递归模式进行查看
效果图:
