从索引出发理解几种常用的数据结构
文章目录
- 位图 Bitmap 与布隆过滤器 Bloom Filter
- 问题牵引:
- 利用位图解决问题:
- 布隆过滤器
- MYSQL的数据库索引-B+树
- 写入数据变慢的原因和解决:
- 删除数据变慢的原因和解决:
- 为什么需要索引?
- 索引的需求定义(设计索引的过程中,需要考虑到的一些因素)
- 1. 功能性需求
- 2.非功能性需求
- 构建索引常用的数据结构有哪些?
- 实践案例(待填充)
位图 Bitmap 与布隆过滤器 Bloom Filter
问题牵引:
假设我们有 1 千万个整数,整数的范围在 1 到 1 亿之间。如何快速查找某个整数是否在这 1 千万个整数中呢?
利用位图解决问题:
当然,这个问题可以用散列表来解决。不过,我们可以使用一种比较“特殊”的散列表,那就是位图。我们申请一个大小为 1 亿(这里就应该想到,如数据的范围过大,特殊的数组都无法申请的问题)、数据类型为1个二进制位的数组。我们将这 1 千万个整数作为数组下标,将对应的数组值设置成 1。比如,整数 5 对应下标为 5 的数组值设置为 1,也就是 array[5]=1。
当我们查询某个整数 K 是否在这 1 千万个整数中的时候,我们只需要将对应的数组值 array[K] 取出来,看是否等于 1。如果等于 1,那说明 1 千万整数中包含这个整数 K;相反,就表示不包含这个整数 K。
这就是位图!!!
很明显,这样子的方式,在一定的场景下,是非常节省内存的呐
布隆过滤器
布隆过滤器的提出就是为了解决上面所遇到的问题(数据的范围过大,特殊的数组都无法申请的问题).其实就是对位图这种数据结构的一种改进而已
还是刚刚那个例子,数据个数是 1 千万,数据的范围是 1 到 10 亿。布隆过滤器的做法是,我们仍然使用一个 1 亿个二进制大小的位图,然后通过哈希函数,对数字进行处理,让它落在这 1 到 1 亿范围内。比如我们把哈希函数设计成 f(x)=x%n。其中,x 表示数字,n 表示位图的大小(1 亿),也就是,对数字跟位图的大小进行取模求余。
不过,你肯定会说,哈希函数会存在冲突的问题啊,一亿零一和 1 两个数字,经过你刚刚那个取模求余的哈希函数处理之后,最后的结果都是 1。这样我就无法区分,位图存储的是 1 还是一亿零一了。
为了降低这种冲突概率,当然我们可以设计一个复杂点、随机点的哈希函数(这里我觉得不对,你设计的再随机也会发生冲突的啊)。除此之外,还有其他方法吗?我们来看布隆过滤器的处理方法。既然一个哈希函数可能会存在冲突,那用多个哈希函数一块儿定位一个数据,是否能降低冲突的概率呢?我来具体解释一下,布隆过滤器是怎么做的。
我们使用 K 个哈希函数,对同一个数字进行求哈希值,那会得到 K 个不同的哈希值,我们分别记作 X1X1,X2X2,X3X3,…,XKXK。我们把这 K 个数字作为位图中的下标,将对应的 BitMap[X1X1],BitMap[X2X2],BitMap[X3X3],…,BitMap[XKXK] 都设置成 true,也就是说,我们用 K 个二进制位,来表示一个数字的存在。
当我们要查询某个数字是否存在的时候,我们用同样的 K 个哈希函数,对这个数字求哈希值,分别得到 Y1Y1,Y2Y2,Y3Y3,…,YKYK。我们看这 K 个哈希值,对应位图中的数值是否都为 true,如果都是 true,则说明,这个数字存在,如果有其中任意一个不为 true,那就说明这个数字不存在。
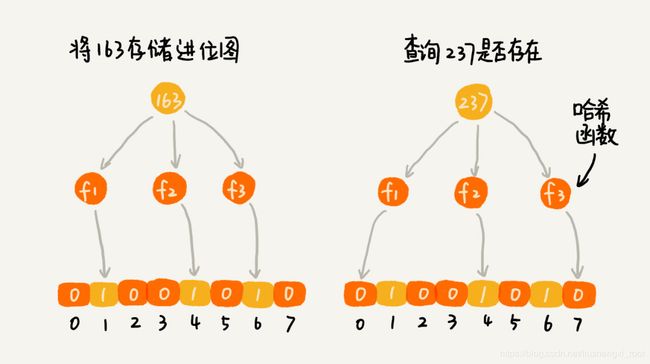
上图的237就是不存在的.
对于两个不同的数字来说,经过一个哈希函数处理之后,可能会产生相同的哈希值。但是经过 K 个哈希函数处理之后,K 个哈希值都相同的概率就非常低了。尽管采用 K 个哈希函数之后,两个数字哈希冲突的概率降低了,但是,这种处理方式又带来了新的问题,那就是容易误判。我们看下面这个例子。
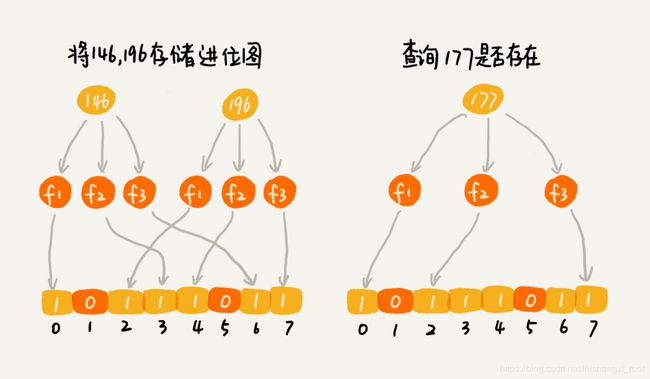
布隆过滤器的误判有一个特点,那就是,它只会对存在的情况有误判。如果某个数字经过布隆过滤器判断不存在,那说明这个数字真的不存在,不会发生误判;如果某个数字经过布隆过滤器判断存在,这个时候才会有可能误判,有可能并不存在。不过,只要我们调整哈希函数的个数、位图大小跟要存储数字的个数之间的比例,那就可以将这种误判的概率降到非常低。(这个是真的吗?我有点不相信)
尽管布隆过滤器会存在误判,但是,这并不影响它发挥大作用。很多场景对误判有一定的容忍度。比如搜索引擎,如果发生误判,漏掉一个URL的话,也不是什么大事情,是可以容忍的,毕竟网页太多了,搜索引擎也不可能 100% 都爬取到。
这就是布隆过滤器!!!
MYSQL的数据库索引-B+树
mysql常用的查询语句主要有:
根据某个值查找数据,比如
select * from user where id=1234;
根据区间值来查找某些数据,比如
select * from user where id > 1234 and id < 2345。
目前使用经过改造后的二叉查找树来分析问题:
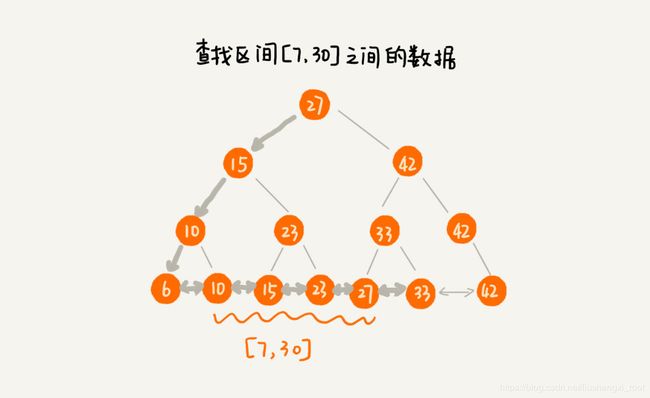
改造之后,如果我们要求某个区间的数据。我们只需要拿区间的起始值,在树中进行查找,当查找到某个叶子节点之后,我们再顺着链表往后遍历,直到链表中的结点数据值大于区间的终止值为止。所有遍历到的数据,就是符合区间值的所有数据。
但是如果数据很多,将索引放在内存中很显然是很浪费内存的啦.那只好放在硬盘中了
这种将索引存储在硬盘中的方案,尽管减少了内存消耗,但是在数据查找的过程中,需要读取磁盘中的索引,因此数据查询效率就相应降低很多。
二叉查找树,经过改造之后,支持区间查找的功能就实现了。不过,为了节省内存,如果把树存储在硬盘中,那么每个索引节点的读取(或者访问),都对应一次磁盘 IO 操作。树的高度就等于每次查询数据时磁盘 IO 操作的次数。
很显然如何减少访问磁盘的次数是关键,也就是降低树的高度,如何降低高度,那自然是多叉!!!
如果我们将 m 叉树实现 B+ 树索引,用代码实现出来,就是下面这个样子(假设我们给 int 类型的数据库字段添加索引,所以代码中的 keywords 是 int 类型的):
/**
* 这是 B+ 树非叶子节点的定义。
*
* 假设 keywords=[3, 5, 8, 10]
* 4 个键值将数据分为 5 个区间:(-INF,3), [3,5), [5,8), [8,10), [10,INF)
* 5 个区间分别对应:children[0]...children[4]
*
* m 值是事先计算得到的,计算的依据是让所有信息的大小正好等于页的大小:
* PAGE_SIZE = (m-1)*4[keywordss 大小]+m*8[children 大小]
*/
public class BPlusTreeNode {
public static int m = 5; // 5 叉树
public int[] keywords = new int[m-1]; // 键值,用来划分数据区间
public BPlusTreeNode[] children = new BPlusTreeNode[m];// 保存子节点指针
}
/**
* 这是 B+ 树中叶子节点的定义。
*
* B+ 树中的叶子节点跟内部结点是不一样的,
* 叶子节点存储的是值,而非区间。
* 这个定义里,每个叶子节点存储 3 个数据行的键值及地址信息。
*
* k 值是事先计算得到的,计算的依据是让所有信息的大小正好等于页的大小:
* PAGE_SIZE = k*4[keyw.. 大小]+k*8[dataAd.. 大小]+8[prev 大小]+8[next 大小]
*/
public class BPlusTreeLeafNode {
public static int k = 3;
public int[] keywords = new int[k]; // 数据的键值
public long[] dataAddress = new long[k]; // 数据地址
public BPlusTreeLeafNode prev; // 这个结点在链表中的前驱结点
public BPlusTreeLeafNode next; // 这个结点在链表中的后继结点
}
说实话,代码我并没有看的很懂,下来再看一下,问一下别人.
对于相同个数的数据构建 m 叉树索引,m 叉树中的 m 越大,那树的高度就越小,那 m 叉树中的 m 是不是越大越好呢?到底多大才最合适呢?
不管是内存中的数据,还是磁盘中的数据,操作系统都是按页(一页大小通常是 4KB,这个值可以通过 getconfig PAGE_SIZE 命令查看)来读取的,一次会读一页的数据。如果要读取的数据量超过一页的大小,就会触发多次 IO 操作。所以,我们在选择 m 大小的时候,要尽量让每个节点的大小等于一个页的大小。读取一个节点,只需要一次磁盘 IO 操作。
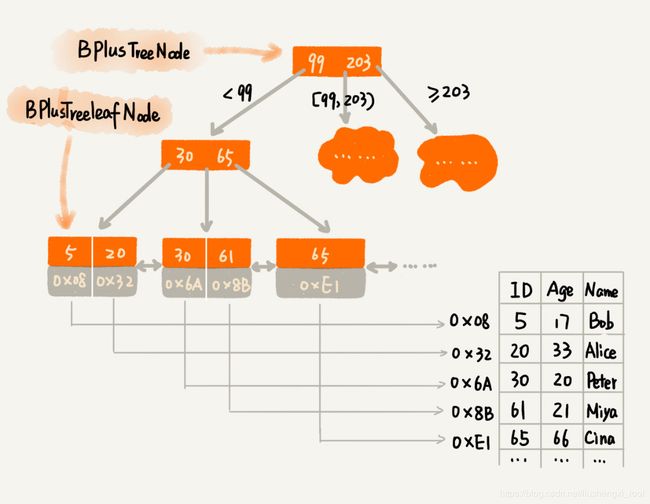
尽管索引可以提高数据库的查询效率,但是,作为一名开发工程师,你应该也知道,索引有利也有弊,它也会让写入数据和删除数据的效率下降。这是为什么呢?这里是因为索引也需要动态更新
写入数据变慢的原因和解决:
对于一个 B+ 树来说,m 值是根据页的大小事先计算好的,也就是说,每个节点最多只能有 m 个子节点。在往数据库中写入数据的过程中,这样就有可能使索引中某些节点的子节点个数超过 m,这个节点的大小超过了一个页的大小,读取这样一个节点,就会导致多次磁盘 IO 操作。我们该如何解决这个问题呢?
实际上,处理思路并不复杂。我们只需要将这个节点分裂成两个节点。但是,节点分裂之后,其上层父节点的子节点个数就有可能超过 m 个。不过这也没关系,我们可以用同样的方法,将父节点也分裂成两个节点。这种级联反应会从下往上,一直影响到根节点。这个分裂过程,你可以结合着下面这个图一块看,会更容易理解(图中的 B+ 树是一个三叉树。我们限定叶子节点中,数据的个数超过 2 个就分裂节点;非叶子节点中,子节点的个数超过 3 个就分裂节点)。
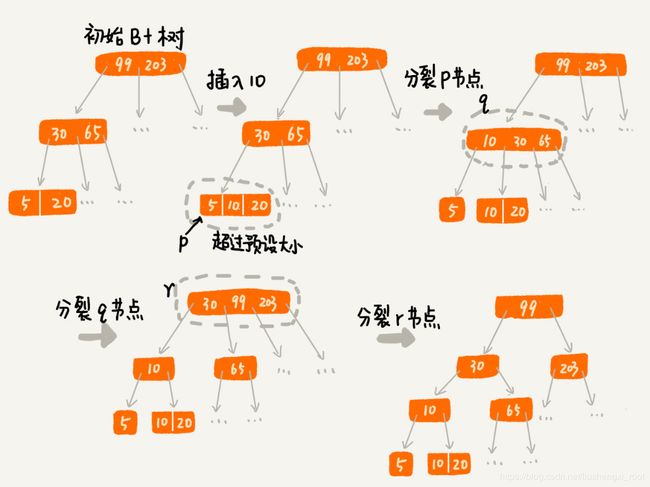
删除数据变慢的原因和解决:
我们在删除某个数据的时候,也要对应的更新索引节点。频繁的数据删除,就会导致某些结点中,子节点的个数变得非常少,长此以往,如果每个节点的子节点都比较少,势必会影响索引的效率。
我们可以设置一个阈值。在 B+ 树中,这个阈值等于 m/2。如果某个节点的子节点个数小于 m/2,我们就将它跟相邻的兄弟节点合并。不过,合并之后结点的子节点个数有可能会超过 m。针对这种情况,我们可以借助插入数据时候的处理方法,再分裂节点。
文字描述不是很直观,我举了一个删除操作的例子,你可以对比着看下(图中的 B+ 树是一个五叉树。我们限定叶子节点中,数据的个数少于 2 个就合并节点;非叶子节点中,子节点的个数少于 3 个就合并节点。)。
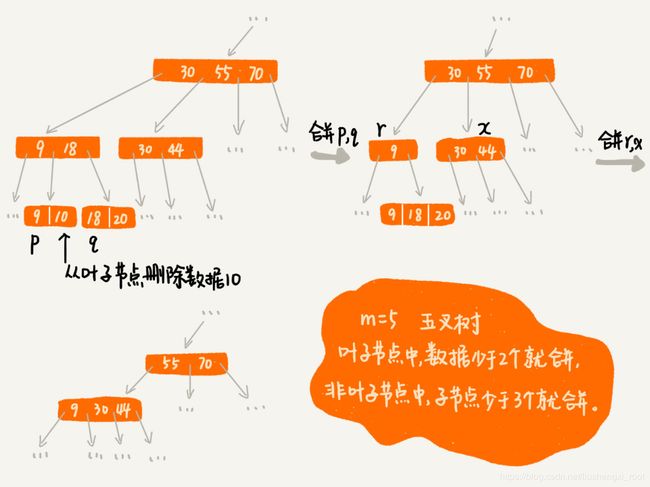
以上就是关于B+树在数据库索引中的讲解了
为了加速数据库中数据的查找速度,我们常用的处理思路是,对表中数据创建索引。那你是否思考过,数据库索引是如何实现的呢?底层使用的是什么数据结构和算法呢?
为什么需要索引?
在实际的软件开发中,业务纷繁复杂,功能千变万化,但是,万变不离其宗。如果抛开这些业务和功能的外壳,其实它们的本质都可以抽象为“对数据的存储和计算”。对应到数据结构和算法中,那“存储”需要的就是数据结构,“计算”需要的就是算法。
对于存储的需求,功能上无外乎增删改查。这其实并不复杂。但是,一旦存储的数据很多,那性能就成了这些系统要关注的重点,特别是在一些跟存储相关的基础系统(比如 MySQL 数据库、分布式文件系统等)、中间件(比如消息中间件 RocketMQ 等)中。
“如何节省存储空间、如何提高数据增删改查的执行效率”,这样的问题就成了设计的重点。而这些系统的实现,都离不开一个东西,那就是索引。不夸张地说,索引设计得好坏,直接决定了这些系统是否优秀。 索引这个概念,非常好理解。你可以类比书籍的目录来理解。如果没有目录,我们想要查找某个知识点的时候,就要一页一页翻。通过目录,我们就可以快速定位相关知识点的页数,查找的速度也会有质的提高。
索引的需求定义(设计索引的过程中,需要考虑到的一些因素)
对于系统的设计需求,我们一般可以从功能性需求和非功能性需求两方面来分析
- 插播:什么是 功能性需求和非功能性需求 ?
功能性需求:功能需求是指提供了什么服务,实现了什么功能。
非功能性需求:描述了一个系统的性能特点.
- 什么是 结构化数据和非结构化数据 ?
结构化数据:是指驻留在记录或文件中的固定字段中的任何数据。这包括关系数据库和电子表格中包含的数据。
非结构化数据:那些无法轻易分类并融入整齐盒子的东西:照片和图形图像,视频,流媒体仪器数据,网页,PDF文件,PowerPoint演示文稿,电子邮件,博客条目,维基和文字处理文档。
1. 功能性需求
-
数据是格式化数据还是非格式化数据?要构建索引的原始数据,类型有很多。我把它分为两类,一类是结构化数据,比如,MySQL 中的数据;另一类是非结构化数据,比如搜索引擎中网页。对于非结构化数据,我们一般需要做预处理,提取出查询关键词,对关键词构建索引。
-
数据是静态数据还是动态数据?如果原始数据是一组静态数据,也就是说,不会有数据的增加、删除、更新操作,所以,我们在构建索引的时候,只需要考虑查询效率就可以了。这样,索引的构建就相对简单些。不过,大部分情况下,我们都是对动态数据构建索引,也就是说,我们不仅要考虑到索引的查询效率,在原始数据更新的同时,我们还需要
动态地更新索引。支持动态数据集合的索引,设计起来相对也要更加复杂些。 -
索引存储在内存还是硬盘?如果索引存储在内存中,那查询的速度肯定要比存储在磁盘中的高。但是,如果原始数据量很大的情况下,对应的索引可能也会很大。这个时候,因为内存有限,我们可能就不得不将索引存储在磁盘中了。实际上,还有第三种情况,那就是一部分存储在内存,一部分存储在磁盘,这样就可以兼顾内存消耗和查询效率。
-
单值查找还是区间查找?所谓单值查找,也就是根据查询关键词等于某个值的数据。这种查询需求最常见(
map)。所谓区间查找,就是查找关键词处于某个区间值的所有数据。你可以类比 MySQL 数据库的查询需求,自己想象一下。实际上,不同的应用场景,查询的需求会多种多样。 -
单关键词查找还是多关键词组合查找?比如,搜索引擎中构建的索引,既要支持一个关键词的查找,比如“数据结构”,也要支持组合关键词查找,比如“数据结构 AND 算法”。对于单关键词的查找,索引构建起来相对简单些。对于多关键词查询来说,要分多种情况。像 MySQL 这种结构化数据的查询需求,我们可以实现针对多个关键词的组合,建立索引;对于像搜索引擎这样的非结构数据的查询需求,我们可以针对单个关键词构建索引,然后通过集合操作,比如求并集、求交集等,计算出多个关键词组合的查询结果。
2.非功能性需求
-
不管是存储在内存中还是磁盘中,索引对存储空间的消耗不能过大。如果存储在内存中,索引对占用存储空间的限制就会非常苛刻。毕竟内存空间非常有限,一个中间件启动后就占用几个 GB 的内存,开发者显然是无法接受的。如果存储在硬盘中,那索引对占用存储空间的限制,稍微会放宽一些。但是,我们也不能掉以轻心。因为,有时候,索引对存储空间的消耗会超过原始数据。(应该是在那里都是不允许的)
-
在考虑索引查询效率的同时,我们还要考虑索引的维护成本(专门针对动态数据)。索引的目的是提高查询效率,但是,基于动态数据集合构建的索引,我们还要考虑到,索引的维护成本。因为在原始数据动态增删改的同时,我们也需要动态的更新索引。而索引的更新势必会影响到增删改操作的性能。(咋不整个异步呐?)
构建索引常用的数据结构有哪些?
刚刚从很宏观的角度,总结了在索引设计的过程中,需要考虑的一些共性因素。现在,我们就来看,对于不同需求的索引结构,底层一般使用哪种数据结构。
实际上,常用来构建索引的数据结构,就是我们之前讲过的几种支持动态数据集合的数据结构。比如,散列表、红黑树、跳表、B+ 树。除此之外,位图、布隆过滤器可以作为辅助索引,有序数组可以用来对静态数据构建索引。
我们知道,散列表增删改查操作的性能非常好,时间复杂度是 O(1)。一些键值数据库,比如 Redis、Memcache,就是使用散列表来构建索引的。这类索引,一般都构建在内存中。
红黑树作为一种常用的平衡二叉查找树,数据插入、删除、查找的时间复杂度是 O(logn),也非常适合用来构建内存索引。Ext 文件系统中,对磁盘块的索引,用的就是红黑树。
B+ 树比起红黑树来说,更加适合构建存储在磁盘中的索引。B+ 树是一个多叉树,所以,对相同个数的数据构建索引,B+ 树的高度要低于红黑树。(时间复杂度与树高度的关系是:O(height))当借助索引查询数据的时候,读取 B+ 树索引,需要的磁盘 IO 次数更少。所以,大部分关系型数据库的索引,比如 MySQL、Oracle,都是用 B+ 树来实现的。
跳表也支持快速添加、删除、查找数据。而且,我们通过灵活调整索引结点个数和数据个数之间的比例,可以很好地平衡索引对内存的消耗及其查询效率。Redis 中的有序集合,就是用跳表来构建的。
插播:为什么 Redis 必须使用跳表来实现有序集合?
主要是为了支持按照区间查找数据
跳表的结构如下,不知道为什么,我老觉得这个很难实现,呜呜~_~:
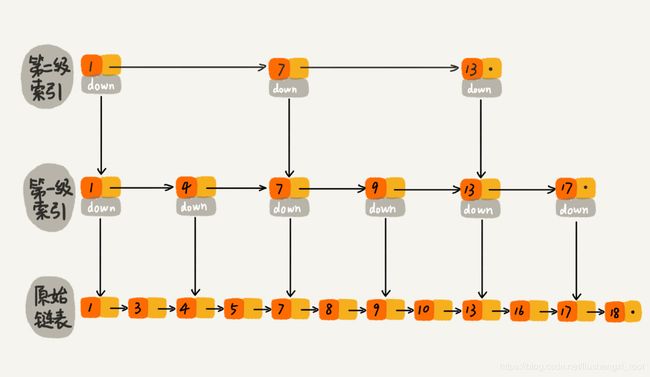
除了散列表、红黑树、B+ 树、跳表之外,位图和布隆过滤器这两个数据结构,也可以用于索引中,辅助存储在磁盘中的索引,加速数据查找的效率。我们来看下,具体是怎么做的?
我们知道,布隆过滤器有一定的判错率。但是,我们可以规避它的短处,发挥它的长处。尽管对于判定存在的数据,有可能并不存在,但是对于判定不存在的数据,那肯定就不存在。而且,布隆过滤器还有一个更大的特点,那就是内存占用非常少。我们可以针对数据,构建一个布隆过滤器,并且存储在内存中。当要查询数据的时候,我们可以先通过布隆过滤器,判定是否存在。如果通过布隆过滤器判定数据不存在,那我们就没有必要读取磁盘中的索引了。对于数据不存在的情况,数据查询就更加快速了。
实际上,有序数组也可以被作为索引。如果数据是静态的,也就是不会有插入、删除、更新操作,那我们可以把数据的关键词(查询用的)抽取出来,组织成有序数组,然后利用二分查找算法来快速查找数据。
实践案例(待填充)
参考自极客时间数据结构与算法之美