KNN实验
这篇博文我们来学习KNN
具体文件与代码可以从我的GitHub地址获取
https://github.com/liuzuoping/MeachineLearning-Case
k-means实验
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import KMeans
from sklearn.datasets import make_blobs
plt.figure(figsize=(12, 12))
# 选取样本数量
n_samples = 1500
# 选取随机因子
random_state = 170
# 获取数据集
X, y = make_blobs(n_samples=n_samples, random_state=random_state)
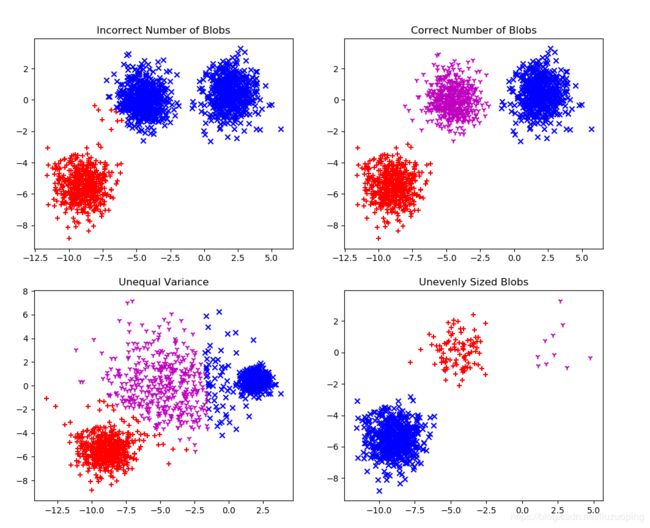
# 聚类数量不正确时的效果
y_pred = KMeans(n_clusters=2, random_state=random_state).fit_predict(X)
plt.subplot(221)
plt.scatter(X[y_pred==0][:, 0], X[y_pred==0][:, 1], marker='x',color='b')
plt.scatter(X[y_pred==1][:, 0], X[y_pred==1][:, 1], marker='+',color='r')
plt.title("Incorrect Number of Blobs")
# 聚类数量正确时的效果
y_pred = KMeans(n_clusters=3, random_state=random_state).fit_predict(X)
plt.subplot(222)
plt.scatter(X[y_pred==0][:, 0], X[y_pred==0][:, 1], marker='x',color='b')
plt.scatter(X[y_pred==1][:, 0], X[y_pred==1][:, 1], marker='+',color='r')
plt.scatter(X[y_pred==2][:, 0], X[y_pred==2][:, 1], marker='1',color='m')
plt.title("Correct Number of Blobs")
# 类间的方差存在差异的效果
X_varied, y_varied = make_blobs(n_samples=n_samples,
cluster_std=[1.0, 2.5, 0.5],
random_state=random_state)
y_pred = KMeans(n_clusters=3, random_state=random_state).fit_predict(X_varied)
plt.subplot(223)
plt.scatter(X_varied[y_pred==0][:, 0], X_varied[y_pred==0][:, 1], marker='x',color='b')
plt.scatter(X_varied[y_pred==1][:, 0], X_varied[y_pred==1][:, 1], marker='+',color='r')
plt.scatter(X_varied[y_pred==2][:, 0], X_varied[y_pred==2][:, 1], marker='1',color='m')
plt.title("Unequal Variance")
# 类的规模差异较大的效果
X_filtered = np.vstack((X[y == 0][:500], X[y == 1][:100], X[y == 2][:10]))
y_pred = KMeans(n_clusters=3, random_state=random_state).fit_predict(X_filtered)
plt.subplot(224)
plt.scatter(X_filtered[y_pred==0][:, 0], X_filtered[y_pred==0][:, 1], marker='x',color='b')
plt.scatter(X_filtered[y_pred==1][:, 0], X_filtered[y_pred==1][:, 1], marker='+',color='r')
plt.scatter(X_filtered[y_pred==2][:, 0], X_filtered[y_pred==2][:, 1], marker='1',color='m')
plt.title("Unevenly Sized Blobs")
plt.show()
系统聚类实验
import numpy as np
import matplotlib.pyplot as plt
from sklearn.cluster import AgglomerativeClustering
from sklearn.datasets import make_blobs
plt.figure(figsize=(12, 12))
# 选取样本数量
n_samples = 1500
# 选取随机因子
random_state = 170
# 获取数据集
X, y = make_blobs(n_samples=n_samples, random_state=random_state)
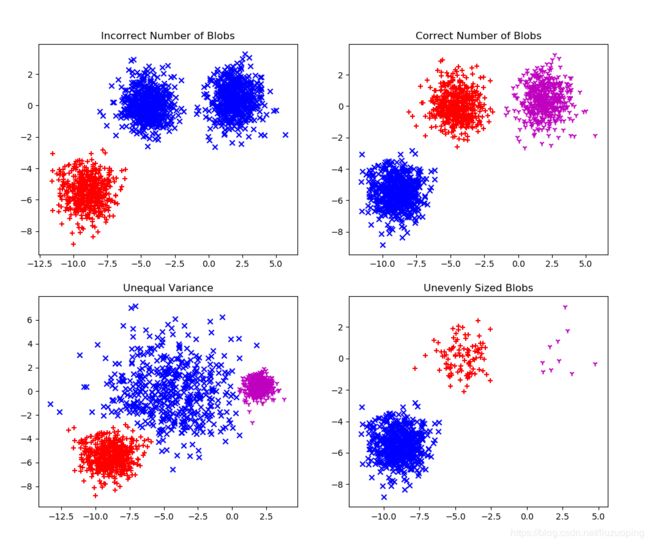
# 聚类数量不正确时的效果
y_pred = AgglomerativeClustering(affinity='euclidean',linkage='ward',n_clusters=2).fit_predict(X)
# 选取欧几里德距离和离差平均和法
plt.subplot(221)
plt.scatter(X[y_pred==0][:, 0], X[y_pred==0][:, 1], marker='x',color='b')
plt.scatter(X[y_pred==1][:, 0], X[y_pred==1][:, 1], marker='+',color='r')
plt.title("Incorrect Number of Blobs")
# 聚类数量正确时的效果
y_pred = AgglomerativeClustering(affinity='euclidean',linkage='ward',n_clusters=3).fit_predict(X)
plt.subplot(222)
plt.scatter(X[y_pred==0][:, 0], X[y_pred==0][:, 1], marker='x',color='b')
plt.scatter(X[y_pred==1][:, 0], X[y_pred==1][:, 1], marker='+',color='r')
plt.scatter(X[y_pred==2][:, 0], X[y_pred==2][:, 1], marker='1',color='m')
plt.title("Correct Number of Blobs")
# 类间的方差存在差异的效果
X_varied, y_varied = make_blobs(n_samples=n_samples,
cluster_std=[1.0, 2.5, 0.5],
random_state=random_state)
y_pred = AgglomerativeClustering(affinity='euclidean',linkage='ward',n_clusters=3).fit_predict(X_varied)
plt.subplot(223)
plt.scatter(X_varied[y_pred==0][:, 0], X_varied[y_pred==0][:, 1], marker='x',color='b')
plt.scatter(X_varied[y_pred==1][:, 0], X_varied[y_pred==1][:, 1], marker='+',color='r')
plt.scatter(X_varied[y_pred==2][:, 0], X_varied[y_pred==2][:, 1], marker='1',color='m')
plt.title("Unequal Variance")
# 类的规模差异较大的效果
X_filtered = np.vstack((X[y == 0][:500], X[y == 1][:100], X[y == 2][:10]))
y_pred = AgglomerativeClustering(affinity='euclidean',linkage='ward',n_clusters=3).fit_predict(X_filtered)
plt.subplot(224)
plt.scatter(X_filtered[y_pred==0][:, 0], X_filtered[y_pred==0][:, 1], marker='x',color='b')
plt.scatter(X_filtered[y_pred==1][:, 0], X_filtered[y_pred==1][:, 1], marker='+',color='r')
plt.scatter(X_filtered[y_pred==2][:, 0], X_filtered[y_pred==2][:, 1], marker='1',color='m')
plt.title("Unevenly Sized Blobs")
plt.show()
密度聚类模型
import numpy as np
from sklearn.cluster import DBSCAN
from sklearn import metrics
from sklearn.datasets.samples_generator import make_blobs
from sklearn.preprocessing import StandardScaler
##############################################################################
# 获取make_blobs数据
centers = [[1, 1], [-1, -1], [1, -1]]
X, labels_true = make_blobs(n_samples=750, centers=centers, cluster_std=0.4,
random_state=0)
# 数据预处理
X = StandardScaler().fit_transform(X)
##############################################################################
# 执行DBSCAN算法
db = DBSCAN(eps=0.3, min_samples=10).fit(X)
core_samples_mask = np.zeros_like(db.labels_, dtype=bool)
# 标记核心对象,后面作图需要用到
core_samples_mask[db.core_sample_indices_] = True
# 算法得出的聚类标签,-1代表样本点是噪声点,其余值表示样本点所属的类
labels = db.labels_
# 获取聚类数量
n_clusters_ = len(set(labels)) - (1 if -1 in labels else 0)
# 输出算法性能的信息
print('Estimated number of clusters: %d' % n_clusters_)
print("Homogeneity: %0.3f" % metrics.homogeneity_score(labels_true, labels))
print("Completeness: %0.3f" % metrics.completeness_score(labels_true, labels))
print("V-measure: %0.3f" % metrics.v_measure_score(labels_true, labels))
print("Adjusted Rand Index: %0.3f"
% metrics.adjusted_rand_score(labels_true, labels))
print("Adjusted Mutual Information: %0.3f"
% metrics.adjusted_mutual_info_score(labels_true, labels))
print("Silhouette Coefficient: %0.3f"
% metrics.silhouette_score(X, labels))
##############################################################################
# 绘图
import matplotlib.pyplot as plt
# 黑色用作标记噪声点
unique_labels = set(labels)
colors = plt.cm.Spectral(np.linspace(0, 1, len(unique_labels)))
i = -1
# 标记样式,x点表示噪声点
marker = ['v','^','o','x']
for k, col in zip(unique_labels, colors):
if k == -1:
# 黑色表示标记噪声点.
col = 'k'
class_member_mask = (labels == k)
i += 1
if (i>=len(unique_labels)):
i = 0
# 绘制核心对象
xy = X[class_member_mask & core_samples_mask]
plt.plot(xy[:, 0], xy[:, 1], marker[i], markerfacecolor=col,
markeredgecolor='k', markersize=14)
# 绘制非核心对象
xy = X[class_member_mask & ~core_samples_mask]
plt.plot(xy[:, 0], xy[:, 1], marker[i], markerfacecolor=col,
markeredgecolor='k', markersize=6)
plt.title('Estimated number of clusters: %d' % n_clusters_)
plt.show()

Estimated number of clusters: 3
Homogeneity: 0.953
Completeness: 0.883
V-measure: 0.917
Adjusted Rand Index: 0.952
Adjusted Mutual Information: 0.883
D:\Anaconda\anaconda\lib\site-packages\sklearn\metrics\cluster\supervised.py:746: FutureWarning: The behavior of AMI will change in version 0.22. To match the behavior of ‘v_measure_score’, AMI will use average_method=‘arithmetic’ by default.
FutureWarning)
Silhouette Coefficient: 0.626