3、安装中文分词器
一、前言
为什么要在elasticsearch中要使用ik这样的中文分词呢,那是因为es提供的分词是英文分词,对于中文的分词就做的非常不好了,因此我们需要一个中文分词器来用于搜索和使用。
二、IK分词器的安装和使用
我们可以从官方github上下载该插件,我们下载对应于我们使用的es的版本的ik,注意选择与你安装的ElasticSearch版本对应的分词器。否则可能导致无法使用分词器。
中文分词器下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases
安装步骤
1、进入es的安装目录下的插件目录
cd /usr/local/elasticsearch-6.5.1/plugins/
2、创建ik目录
mkdir ik
3、上传ik分词器包,并解压
unzip elasticsearch-analysis-ik-6.5.1.zip
rm -rf elasticsearch-analysis-ik-6.5.1.zip
4、在es集群的各个机器都指定以上操作,然后重启es就可以使用改该分词器了
为了查看前台打印信息,注意不要使用后台启动的方式,以便确认分词器是否正确加载!!
干掉es
jps
kill -9 8104以前台的方式重启es
su - es
/usr/local/elasticsearch-6.5.1/bin/elasticsearch
su root
cd /usr/local/elasticsearch-6.5.1/elasticsearch-head/
grunt server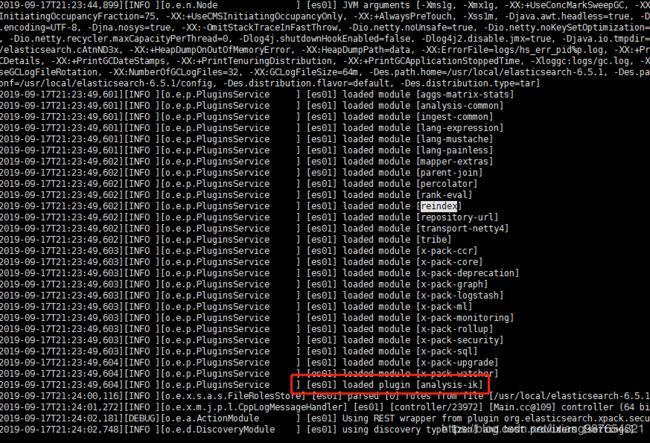


可以看到analysis-ik分词器已经被正确加载!
确认无误后以后台方式重启es
su - es
/usr/local/elasticsearch-6.5.1/bin/elasticsearch -d
su root
cd /usr/local/elasticsearch-6.5.1/elasticsearch-head/
grunt server
5、测试中文分词器
(1)测试分词器分词效果:“中华人民共和国,我爱你!”
curl -i -H "Content-Type: application/json" -XPOST 'http://192.168.12.150:9200/_analyze?pretty' -d '
{
"analyzer": "ik_max_word",
"text":"中华人民共和国,我爱你!"
}
'可以看到,语句被分析成如下多个关键词语
HTTP/1.1 200 OK
content-type: application/json; charset=UTF-8
content-length: 1554
{
"tokens" : [
{
"token" : "中华人民共和国",
"start_offset" : 0,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "中华人民",
"start_offset" : 0,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "中华",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "华人",
"start_offset" : 1,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "人民共和国",
"start_offset" : 2,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "人民",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 5
},
{
"token" : "共和国",
"start_offset" : 4,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 6
},
{
"token" : "共和",
"start_offset" : 4,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 7
},
{
"token" : "国",
"start_offset" : 6,
"end_offset" : 7,
"type" : "CN_CHAR",
"position" : 8
},
{
"token" : "我爱你",
"start_offset" : 8,
"end_offset" : 11,
"type" : "CN_WORD",
"position" : 9
},
{
"token" : "爱你",
"start_offset" : 9,
"end_offset" : 11,
"type" : "CN_WORD",
"position" : 10
}
]
}
可以看到分词器,被分为“中华人民共和国”、“中华人民”、“中华”、“华人”、“人民共和国”等常用的关键词语!
(2)测试分词器分词效果:“热烈庆祝中国建国70周年!”
curl -i -H "Content-Type: application/json" -XPOST 'http://192.168.12.150:9200/_analyze?pretty' -d '
{
"analyzer": "ik_max_word",
"text":"热烈庆祝中国建国70周年!"
}
'分析结果:
HTTP/1.1 200 OK
content-type: application/json; charset=UTF-8
content-length: 1378
{
"tokens" : [
{
"token" : "热烈庆祝",
"start_offset" : 0,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "热烈",
"start_offset" : 0,
"end_offset" : 2,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "庆祝",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "中国",
"start_offset" : 4,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "国建",
"start_offset" : 5,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "建国",
"start_offset" : 6,
"end_offset" : 8,
"type" : "CN_WORD",
"position" : 5
},
{
"token" : "70",
"start_offset" : 8,
"end_offset" : 10,
"type" : "ARABIC",
"position" : 6
},
{
"token" : "周年",
"start_offset" : 10,
"end_offset" : 12,
"type" : "COUNT",
"position" : 7
},
{
"token" : "周",
"start_offset" : 10,
"end_offset" : 11,
"type" : "COUNT",
"position" : 8
},
{
"token" : "年",
"start_offset" : 11,
"end_offset" : 12,
"type" : "COUNT",
"position" : 9
}
]
}6、使用中文分词器
curl -i -H "Content-Type: application/json" -XPUT 'http://192.168.12.150:9200/dys_wifi_alarm_latest/wifialarm/_mapping?pretty' -d '
{
"dynamic": "true",
"_source": {
"enabled": true
},
"properties": {
"id": {
"type": "keyword"
},
"alarmTime": {
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss"
},
"deviceId": {
"type": "keyword",
"copy_to": "full_search"
},
"deviceName": {
"type": "text",
"analyzer": "ik_max_word",
"copy_to": "full_search"
},
"deviceIp": {
"type": "ip",
"copy_to": "full_search"
},
"channel": {
"type": "short"
},
"longitude": {
"type": "float"
},
"latitude": {
"type": "float"
},
"altitude": {
"type": "float"
},
"type": {
"type": "integer"
},
"rssi": {
"type": "integer"
},
"wifi": {
"type": "keyword"
},
"extra": {
"type": "keyword"
},
"reserver1": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"reserver2": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"reserver3": {
"type": "text",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
},
"full_search": {
"type": "text",
"analyzer": "ik_max_word"
}
}
}'快来成为我的朋友或合作伙伴,一起交流,一起进步!:
QQ群:961179337
微信:lixiang6153
邮箱:[email protected]
公众号:IT技术快餐