hbase操作详情
1、启动hbase客户端
./bin/hbase shell
 2、查看当前状态
2、查看当前状态
status

3、建表和列族
create 'tabx','cf1'
create 'tabx4', {NAME => 'cf1', VERSIONS => 3}

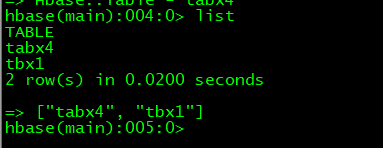
 4、查看列表:
4、查看列表:
list
5、查看结构
describe ‘tabx4’ 或desc ‘tabx4’
 6、put添加
6、put添加
Put命令参数说明:表名,键值,列族,列明,值
put ‘tabx4’,‘rk1’,‘cf1:c1’,‘v111111’
 7、扫描全表
7、扫描全表
scan ‘tabx4’
 8、获取某个键对应的值
8、获取某个键对应的值
get ‘tabx4’,‘rk1’
 有两列:
有两列:

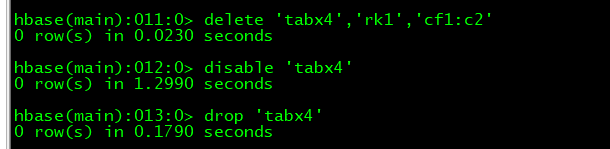
9、删除
delete ‘tabx4’,‘rk1’,‘cf1:c2’
disable ‘tabx4’
drop ‘tabx4’
10、指定VERSIONS建表
create 'testtable',{NAME=>'colfam1',VERSIONS=>3},{NAME=>'colfam2',VERSIONS=>1}
put 'testtable','myrow-1','colfam1:q1','value-1'
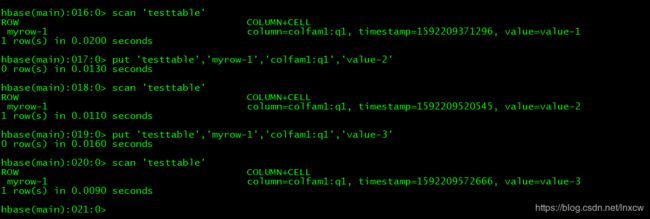
 11、直接使用scan而不加RAW=>true只能查询到最新版本的数据
11、直接使用scan而不加RAW=>true只能查询到最新版本的数据
scan 'testtable'
put 'testtable','myrow-1','colfam1:q1','value-2'
scan 'testtable'
put 'testtable','myrow-1','colfam1:q1','value-3'
scan 'testtable'
 12、可以在查询时加上RAW=>true来开启对历史版本数据的查询,VERSIONS=>3指定查询最新的几个版本的数据
12、可以在查询时加上RAW=>true来开启对历史版本数据的查询,VERSIONS=>3指定查询最新的几个版本的数据
scan ‘testtable’,{RAW=>true,VERSIONS=>3}
 13、退出hbase
13、退出hbase
exit
14、停止hbase
bin/stop-hbase.sh
hive操作:
 建表:
建表:
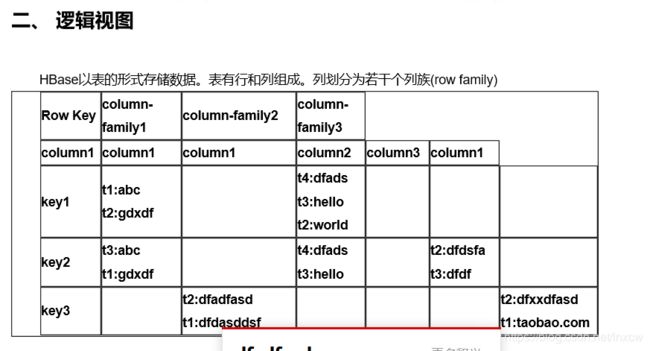
create 'hbase' ,{NAME=>'column-family1',VERSIONS=>3},{NAME=>'column-family2',VERSIONS=>3},{NAME=>'column-family3',VERSIONS=>3},{NAME=>'column-family4',VERSIONS=>3},{NAME=>'column-family5',VERSIONS=>3},{NAME=>'column-family6',VERSIONS=>3}
插入数据:
hbase(main):010:0> put 'hbase','key1','column-family1:t1','abc'
0 row(s) in 0.0240 seconds
hbase(main):011:0> put 'hbase','key1','column-family1:t2','gdxdf'
0 row(s) in 0.0050 seconds
hbase(main):012:0> put 'hbase','key2','column-family1:t3','gdxdf'
0 row(s) in 0.0040 seconds
hbase(main):013:0> put 'hbase','key2','column-family1:t1','abc'
0 row(s) in 0.0050 seconds
hbase(main):015:0> put 'hbase','key3','column-family2:t1','dfdasddsf'
0 row(s) in 0.0090 seconds
hbase(main):016:0> put 'hbase','key3','column-family2:t2','dfadfasd'
0 row(s) in 0.0050 seconds
hbase(main):018:0>put 'hbase','key1','column-family3:t2','world'
0 row(s) in 0.0210 seconds
hbase(main):019:0> put 'hbase','key1','column-family3:t3','hello'
0 row(s) in 0.0040 seconds
hbase(main):020:0> put 'hbase','key1','column-family3:t4','asia'
0 row(s) in 0.0070 seconds
hbase(main):021:0> put 'hbase','key2','column-family3:t4','asia'
0 row(s) in 0.0080 seconds
hbase(main):022:0> put 'hbase','key2','column-family3:t3','hello'
0 row(s) in 0.0070 seconds
hbase(main):027:0> put 'hbase','key1','column-family3:t1','hbase'
0 row(s) in 0.0080 seconds
hbase(main):028:0> put 'hbase','key1','column-family3:t2','hhbase'
0 row(s) in 0.0090 seconds
hbase(main):029:0> put 'hbase','key2','column-family4:t2','hhb'
0 row(s) in 0.0060 seconds
hbase(main):030:0> put 'hbase','key2','column-family4:t3','dfdf'
0 row(s) in 0.0040 seconds
hbase(main):031:0> put 'hbase','key3','column-family5:t3','hhb'
0 row(s) in 0.0070 seconds
hbase(main):032:0> put 'hbase','key3','column-family5:t2','hhbase'
0 row(s) in 0.0100 seconds
 备注:常用命令
备注:常用命令
HBase
启动HBase集群:
bin/start-hbase.sh
单独启动一个HMaster进程:
bin/hbase-daemon.sh start master
单独停止一个HMaster进程:
bin/hbase-daemon.sh stop master
单独启动一个HRegionServer进程:
bin/hbase-daemon.sh start regionserver
单独停止一个HRegionServer进程:
bin/hbase-daemon.sh stop regionserver
zookeeper
执行: zkServer.sh start 启动单个节点的zk服务
查看zk进程是否存在:jps ,发现一个进程 QuorumPeerMain
zkServer.sh status 查看该zk服务器是follower还是leader。
hdfs
start-dfs.sh
stop-dfs.sh
查看hdfs进程是否存在:jps
bin/hdfs zkfc -formatZK 在node01机器上进行zookeeper的初始化,其本质工作是创建对应的zookeeper节点
journalnode
sbin/hadoop-daemon.sh start journalnode 在hadoop里面,用于我们的元数据管理
bin/hdfs namenode -initializeSharedEdits -force node01机器上准备初始化journalNode
sbin/hadoop-daemon.sh start zkfc 在node01、node02上分别启动zkfc进程
yarn(mr)
start-yarn.sh
stop-yarn.sh
查看yarn进程是否存在:jps
jobhistory
mr-jobhistory-daemon.sh start historyserver
mr-jobhistory-daemon.sh stop historyserver
查看jobhistory进程是否存在:jps
flume
启动:flume-ng agent -n a1 -c conf -f conf/wifi.conf -Dflume.root.logger=INFO,console(已经配置flume的环境变量)
停止:以上启动方式是前台启动,可以直接按ctrl+C
hive
nohup hive --service hiveserver2
nohup hive --service metastore