Redis的复制
1 概念
Redis的复制也就是我们所说的主从复制,主机数据更新后根据配置和策略,
自动同步到备机的master/slaver机制,Master以写为主,Slave以读为主
2 读写分离
2.1 主从的配置
2.1.1主从库的配置
配从(库)不配主(库)
从库配置:slaveof 主库IP 主库端口
2.1.2 配置文件的修改
基础配置
- 拷贝3个redis.conf文件(服从一主二仆原则)

- 开启daemonize yes

- pid文件名字对应好端口的名字,方便区分
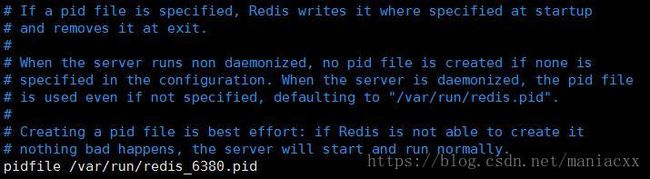
- 指定端口

- log文件名字对应好端口的名字,方便区分

- dump.rdb名字对应好端口的名字,方便区分

2.2 常用三种方式
2.2.1 一主二仆
1 初始状态,三个都为主
可使用info replication来查看当前端口对应得到状态,示例将开三个端口:6379,6380,6381。
//6379
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:0
master_replid:e7075862a06877b2d5e78a5143ed0d7e66089507
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
//6380
127.0.0.1:6380> info replication
# Replication
role:master
connected_slaves:0
master_replid:f853487a56e63c3409b590ce252cc36b010f3c76
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:0
//6381
127.0.0.1:6381> info replication
# Replication
role:master
connected_slaves:0
master_replid:764f1fd849a30ea30b644aea659b892257a23e36
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:0
second_repl_offset:-1
repl_backlog_active:0
repl_backlog_size:1048576
repl_backlog_first_byte_offset:0
repl_backlog_histlen:02.使用指令,设置为一主二仆
使用指令slaveof 主库IP 主库端口,将6380,6381设置为仆从6379的状态
//6380
127.0.0.1:6380> SLAVEOF 127.0.0.1 6379
OK
127.0.0.1:6380> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:up
master_last_io_seconds_ago:9
master_sync_in_progress:0
slave_repl_offset:238
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:5d415780db7c9123f7eb5d245c11099780acffc3
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:238
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:238
//6381
127.0.0.1:6381> SLAVEOF 127.0.0.1 6379
OK
127.0.0.1:6381> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:up
master_last_io_seconds_ago:5
master_sync_in_progress:0
slave_repl_offset:224
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:5d415780db7c9123f7eb5d245c11099780acffc3
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:224
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:29
repl_backlog_histlen:196
//6379
127.0.0.1:6379> info replication
# Replication
role:master
connected_slaves:2
slave0:ip=127.0.0.1,port=6380,state=online,offset=252,lag=1
slave1:ip=127.0.0.1,port=6381,state=online,offset=252,lag=0
master_replid:5d415780db7c9123f7eb5d245c11099780acffc3
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:252
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:2523.问题解决
- 切入点问题?slave1、slave2是从头开始复制还是从切入点开始复制?比如在6380和6381成为6379的仆从之前,6379已经存在k1 k2 k3,三个键,那仆从能不能读取?
- 事实上6380和6381成为仆从以后是可以读取6379内所有的内容的,所有,在成为仆从之前就生成的值,也是能够访问的
- 从机是否可以写?set可否?
- 从机不可写
127.0.0.1:6380> set k5 v5
(error) READONLY You can't write against a read only slave.- 主机shutdown后情况如何?从机是上位还是原地待命
- 从机原地待命,等待主机归来,master_link_status属性从up变为down,表示主机脱离
127.0.0.1:6380> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:down
master_last_io_seconds_ago:-1
master_sync_in_progress:0
slave_repl_offset:2727
master_link_down_since_seconds:151
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:5d415780db7c9123f7eb5d245c11099780acffc3
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:2727
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:2727- 主机又回来了后,主机新增记录,从机还能否顺利复制?
- 能
- 其中一台从机down后情况如何?依照原有它能跟上大部队吗?
- 从机down掉以后,重启,会脱离,状态再次变为master,只保留之前复制的数据,主机新写入的复制不了,使用指令重新成为从机可继续跟随。
2.2.2 薪火相传
上一个Slave可以是下一个slave的Master,Slave同样可以接收其他
slaves的连接和同步请求,那么该slave作为了链条中下一个的master,
可以有效减轻master的写压力中途变更转向:会清除之前的数据,重新建立拷贝最新的
slaveof 新主库IP 新主库端口
127.0.0.1:6380> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6379
master_link_status:up
master_last_io_seconds_ago:8
master_sync_in_progress:0
slave_repl_offset:115430
slave_priority:100
slave_read_only:1
connected_slaves:1
slave0:ip=127.0.0.1,port=6381,state=online,offset=115430,lag=0
master_replid:89f0f0cbe814779a443a1a54c71aa6d5cad4d788
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:115430
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:115430
2.2.3 反客为主
指令:SLAVEOF no one
使当前数据库停止与其他数据库的同步,转成主数据库
解除跟随主机,变为主机状态
127.0.0.1:6380> SLAVEOF no one
OK
127.0.0.1:6380> info replication
# Replication
role:master
connected_slaves:0
master_replid:f272fe00de976f312c06ee06104007eb0c8824b2
master_replid2:89f0f0cbe814779a443a1a54c71aa6d5cad4d788
master_repl_offset:116463
second_repl_offset:116464
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:1
repl_backlog_histlen:116463
2.3 复制原理
- slave启动成功连接到master后会发送一个sync命令
- Master接到命令启动后台的存盘进程,同时收集所有接收到的用于修改数据集命令,在后台进程执行完毕之后,master将传送整个数据文件到slave,以完成一次完全同步
- 全量复制:而slave服务在接收到数据库文件数据后,将其存盘并加载到内存中。
- 增量复制:Master继续将新的所有收集到的修改命令依次传给slave,完成同步
- 但是只要是重新连接master,一次完全同步(全量复制)将被自动执行
2.4 哨兵模式
反客为主的自动版,能够后台监控主机是否故障,如果故障了根据投票数自动将从库转换为主库。
使用流程
2.4.1 调整结构为一主两仆
如6379为主,6380和6381为仆。
2.4.2 新建sentinel.conf文件
自定义的/myredis目录下新建sentinel.conf文件,名字绝不能错,并配置内容
内容:例sentinel monitor host6378 127.0.0.1 6379 1
表示设置127.0.0.1 下的6379端口为主机,最后一个1表示当主机出意外以后,哨兵对从机进行投票,当投票大于一票的时候,此从机变为新的主机,另一个从机跟随这个新主机。
2.4.3 启动哨兵
指令:[root@duan bin]# redis-sentinel /usr/local/bin/sentinel.conf
2.4.4 关闭哨兵
关闭哨兵模式:redis-cli -p 26379 shutdown
//启动后的界面
7234:X 10 Aug 11:26:03.593 # WARNING: The TCP backlog setting of 511 cannot be enforced because /proc/sys/net/core/somaxconn is set to the lower value of 128.
7234:X 10 Aug 11:26:03.596 # Sentinel ID is abc27b6f9376f04b2b9b85b33bb3d8b884d485ce
7234:X 10 Aug 11:26:03.596 # +monitor master host6378 127.0.0.1 6379 quorum 1
7234:X 10 Aug 11:26:03.597 * +slave slave 127.0.0.1:6381 127.0.0.1 6381 @ host6378 127.0.0.1 6379
7234:X 10 Aug 11:26:03.599 * +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ host6378 127.0.0.1 6379
7234:X 10 Aug 11:27:24.164 # +sdown master host6378 127.0.0.1 6379
7234:X 10 Aug 11:27:24.164 # +odown master host6378 127.0.0.1 6379 #quorum 1/1
7234:X 10 Aug 11:27:24.164 # +new-epoch 1
2.4.4 投票新选
将原来的主机shutdown以后,哨兵就会对从机进行投票
//主机shutdown
127.0.0.1:6379> SHUTDOWN
not connected> exit
//哨兵界面开始投票
7234:X 10 Aug 11:27:24.164 # +try-failover master host6378 127.0.0.1 6379
7234:X 10 Aug 11:27:24.166 # +vote-for-leader abc27b6f9376f04b2b9b85b33bb3d8b884d485ce 1
7234:X 10 Aug 11:27:24.166 # +elected-leader master host6378 127.0.0.1 6379
7234:X 10 Aug 11:27:24.166 # +failover-state-select-slave master host6378 127.0.0.1 6379
7234:X 10 Aug 11:27:24.221 # +selected-slave slave 127.0.0.1:6381 127.0.0.1 6381 @ host6378 127.0.0.1 6379
7234:X 10 Aug 11:27:24.221 * +failover-state-send-slaveof-noone slave 127.0.0.1:6381 127.0.0.1 6381 @ host6378 127.0.0.1 6379
7234:X 10 Aug 11:27:24.280 * +failover-state-wait-promotion slave 127.0.0.1:6381 127.0.0.1 6381 @ host6378 127.0.0.1 6379
7234:X 10 Aug 11:27:24.567 # +promoted-slave slave 127.0.0.1:6381 127.0.0.1 6381 @ host6378 127.0.0.1 6379
7234:X 10 Aug 11:27:24.567 # +failover-state-reconf-slaves master host6378 127.0.0.1 6379
7234:X 10 Aug 11:27:24.652 * +slave-reconf-sent slave 127.0.0.1:6380 127.0.0.1 6380 @ host6378 127.0.0.1 6379
7234:X 10 Aug 11:27:25.621 * +slave-reconf-inprog slave 127.0.0.1:6380 127.0.0.1 6380 @ host6378 127.0.0.1 6379
7234:X 10 Aug 11:27:25.621 * +slave-reconf-done slave 127.0.0.1:6380 127.0.0.1 6380 @ host6378 127.0.0.1 6379
7234:X 10 Aug 11:27:25.687 # +failover-end master host6378 127.0.0.1 6379
7234:X 10 Aug 11:27:25.687 # +switch-master host6378 127.0.0.1 6379 127.0.0.1 6381
7234:X 10 Aug 11:27:25.687 * +slave slave 127.0.0.1:6380 127.0.0.1 6380 @ host6378 127.0.0.1 6381
7234:X 10 Aug 11:27:25.688 * +slave slave 127.0.0.1:6379 127.0.0.1 6379 @ host6378 127.0.0.1 6381
7234:X 10 Aug 11:27:55.760 # +sdown slave 127.0.0.1:6379 127.0.0.1 6379 @ host6378 127.0.0.1 6381
7234:X 10 Aug 11:30:18.171 # -sdown slave 127.0.0.1:6379 127.0.0.1 6379 @ host6378 127.0.0.1 6381
//最后6381成为新主机,6380成为6381的从机2.4.5 如果之前的master重启回来,会成为新主机的从机
//哨兵界面
7234:X 10 Aug 11:30:28.168 * +convert-to-slave slave 127.0.0.1:6379 127.0.0.1 6379 @ host6378 127.0.0.1 6381
//6379端口界面
127.0.0.1:6379> info replication
# Replication
role:slave
master_host:127.0.0.1
master_port:6381
master_link_status:up
master_last_io_seconds_ago:1
master_sync_in_progress:0
slave_repl_offset:17185
slave_priority:100
slave_read_only:1
connected_slaves:0
master_replid:39221b8f7cc8c8348f10a75b1696237e1b096a4a
master_replid2:0000000000000000000000000000000000000000
master_repl_offset:17185
second_repl_offset:-1
repl_backlog_active:1
repl_backlog_size:1048576
repl_backlog_first_byte_offset:16897
repl_backlog_histlen:289
注:一组sentinel能同时监控多个Master
3 复制的缺点
由于所有的写操作都是先在Master上操作,然后同步更新到Slave上,所以从Master同步到Slave机器有一定的延迟,当系统很繁忙的时候,延迟问题会更加严重,Slave机器数量的增加也会使这个问题更加严重。