python 3爬取 全国高校对四川历年招生数据(文理省控线,文理专业线)存入Excel表
由于我们的acm的指导老师对项目组布置的一个高考志愿学校推荐系统,是大数据和机器学习的结合,我负责的是爬取数据,给机器学习小组用,网页数据不在你搜索当前学校网页上看到的那样,是通过js生成的。数据来源:https://gkcx.eol.cn/soudaxue/queryschool.html,这个网址的数据相对来说很齐全....目前来说能够找到高校录取数据最多的网址。
提示:由于网站更新,采用ajax异步请求数据(网页源代码没有数据)然后加载到网页中,所以本博客源码没法使用,但是爬取逻辑思路还是很重要的,可以供大家学习,需要更新后能用的代码请点击传送门:https://blog.csdn.net/memory_qianxiao/article/details/88767327,最新分析以及可使用代码,供大家参考。
环境:python3.6 +pycharm或者你喜欢的编译器
第三方库:requests(网页请求库),Beautifulsoup(网页解析库),re(正则解析提取库),xlwt(python操作excel库)
这里我先放出效果图镇楼:(楼主爬了一下午加晚上才爬取了800多所高校数据,估计需要两天才能跑完...)

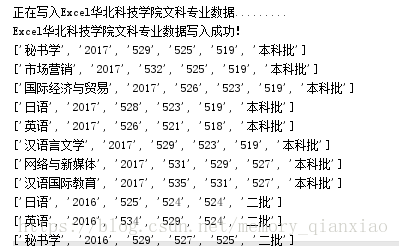

首先我们会输入学校,输入学校之后进入学校主页,就能看到部分数据。这里我就随便点了一个。

而我们需要的数据是录取分数线,专业录取分数线(可以点击更多看到,也可以点击上面的各省录取线,专业录取线)
而我们查询学校的网址是:
https://gkcx.eol.cn/soudaxue/queryschool.html&keyWord1=输入的学校名字
然后就会进入上图那样的主页,看到部分数据。然后我们看网址:
https://gkcx.eol.cn/schoolhtm/schoolTemple/school140.htm 发现,school后面跟了一个数字,140这个就是学校的id,每个学校对应了一个id,当我们输入名字的时候,就找到了一个id。我们需要学校id进入学校主页,因为你只输入关键字是不能进入到主页的,当你手动点击那个连接才能进入,而这个连接就是带学校id。那怎么获取学校的id呢,那就是输入关键字,手动点击进入学校以后看到网址就有了。废话了这么多,原来还需要手动点!!!!那太难受了,能不能程序自动了?
反正博主是没法~~~~哈哈,(当初我开始的我还把每个学校的名字爬下来,打算通过名字,输入,然后获取id)然而网页输入关键字后,就没有你需要的东西~~难不难受?是通过js生成的...
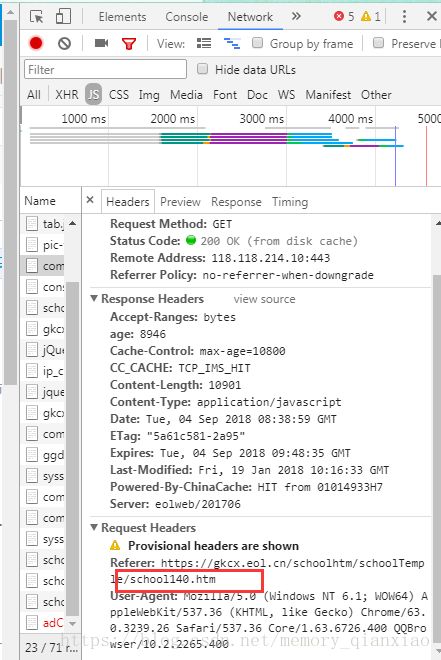
按F12进入network在js里面最后一个能看到我们需要的网址,但是源网页没有,没有!没有!也就是你通过程序关键字输入的返回的网页代码没有的,既然没有怎么提取?
所以博主的解决办法是暴力搜索,所以曾经acm经历带来的好处,算法学的不怎么样,但是思想还是受影响的,于是博主就手动输入ID从1开始尝试,然后id间距增大。最终经过博主的不断尝试,发现一个规律:ID是从30开始的到2577之间的才是有效的。
也就是我们需要学校的数据开始网址:https://gkcx.eol.cn/schoolhtm/schoolTemple/school30.htm ****北京工业大学
结束网址:https://gkcx.eol.cn/schoolhtm/schoolTemple/school2577.htm ***三亚理工职业学院
所以我们for循环一次,30到2578id就能遍历所有高校主页,然后请求这个url就ok。
for i in range(532,2577):
url="https://gkcx.eol.cn/schoolhtm/schoolTemple/school"+str(i)+".htm"当我们有了每个学校的url以后,就能请求的网页中找到省控线网址(默认是地址学校所在省,默认理科,默认年份2017年)
所以我们需要通过程序进入每个学校主页,爬取这些数据,顺便把学校名字和地址也爬取了,存入一个列表,后面就能用。
这里贴出爬取省控线网址,专业线网址,学校,名字。采用re和beaufifulsoup合用的方式,不懂用法的请百度。

提出后这些网址后,你发现不全,不能请求,还需要在前面添加 https://gkcx.eol.cn,才能够正常访问我们需要的网页。
def search_University(url,info):
try:
html=GetHtml(url)
soup=BeautifulSoup(html,"html.parser")
pattern=re.compile(r"var schoolname='([\u4e00-\u9fa5]{1,20}?)'")
university_name=re.findall(pattern,html)
if university_name!=[]:
info.append(university_name[0])
soup1 = soup.find_all("a")
for a_xian in soup1:
if a_xian.string=='各省录取线':
#print(a_xian['href'])
info.append(a_xian['href'])
if a_xian.string=='专业录取线':
#print(a_xian['href'])
info.append(a_xian['href'])
except:
print("Error")
接下来我们会爬取历年文理科对四川省控线,数据如下边这样。
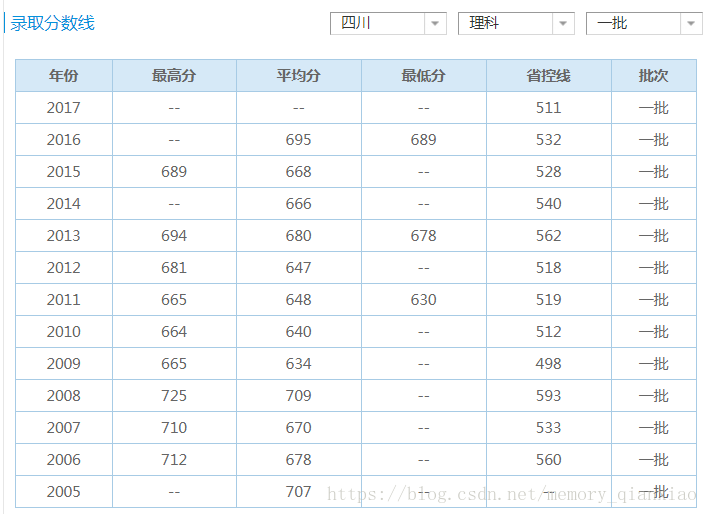
我们需要的省控线参数有地区(默认是学习所在省),文理科(默认理科),批次(默认一批)。
接下来是分析重点:
我们点击四川省,文理都点一些,批次我点击本科一批,二批,三批,专科批,发现网址如下:
一批:https://gkcx.eol.cn/schoolhtm/schoolAreaPoint/30/10005/10035/10036.htm
二本:https://gkcx.eol.cn/schoolhtm/schoolAreaPoint/30/10005/10035/10037.htm
三本:https://gkcx.eol.cn/schoolhtm/schoolAreaPoint/770/10005/10035/10038.htm
专科:https://gkcx.eol.cn/schoolhtm/schoolAreaPoint/770/10005/10035/10155.htm最后我再说下点击那么多网址总结规律(acm思想锻炼的还是可以的):
ttps://gkcx.eol.cn/schoolhtm/schoolAreaPoint/**学校ID**770/**省份**10005/**文理**10034/**批次10036.htm
770是学校ID,1005是四川省的代码,10034是文科,10035是理科,一批:10036,二批:10037,三批:10038,专科批:10155
所以我们需要请求的省份,文理,批次都可以改动请求,然后提取数据。这里直接给出提取的源码省控线的源码
def search_University(url,info):
try:
html=GetHtml(url)
soup=BeautifulSoup(html,"html.parser")
pattern=re.compile(r"var schoolname='([\u4e00-\u9fa5]{1,20}?)'")
university_name=re.findall(pattern,html)
if university_name!=[]:
info.append(university_name[0])
soup1 = soup.find_all("a")
for a_xian in soup1:
if a_xian.string=='各省录取线':
#print(a_xian['href'])
info.append(a_xian['href'])
if a_xian.string=='专业录取线':
#print(a_xian['href'])
info.append(a_xian['href'])
except:
print("Error")
def get_schoolAreaPoint(info):
school_point_url="https://gkcx.eol.cn"+info[1].strip()
school_specialty_point_url="https://gkcx.eol.cn"+info[2].strip()
#把省控线切割为列表
s1=school_point_url.split('/')
#把省份变为四川
s1[-3]='10005'
#把专业线切割为列表
s2 = school_specialty_point_url.split('/')
#文理科数据存放列表
infolist_like=[]
infolist_wenke=[]
# 把列表合成字符网址
url='/'.join(s1)
html=GetHtml(url)
#地址
soup = BeautifulSoup(html, "html.parser")
soup1=soup.find_all('span')
adress=''
for i in soup1:
if i.string!=None and '号' in list(i.string):
adress=i.string
#print(adress)
#**************理科省控线*****************#
#本科一批
flag1=True
soup2 = soup.find_all('tr')
for i in soup2:
for j in i:
if j.string=='暂时没有数据':
flag1=False
if flag1:
for i in soup2:
l=[]
cont=0
for j in i:
cont+=1
if cont==10 and j.string not in['年份','最高分','平均分','最低分','省控线','批次']:
l.append(j.span.string[:3])
elif j!='\n' and j.string not in['年份','最高分','平均分','最低分','省控线','批次']:
l.append(j.string)
if l!=[]:
infolist_like.append(l)
# 本科二批
flag2=True
s1[-1]='10037.htm'
url='/'.join(s1)
html=GetHtml(url)
soup=BeautifulSoup(html,'html.parser')
soup2 = soup.find_all('tr')
for i in soup2:
for j in i:
if j.string=='暂时没有数据':
flag2=False
if flag2:
for i in soup2:
l = []
cont = 0
for j in i:
cont += 1
if cont == 10 and j.string not in ['年份', '最高分', '平均分', '最低分', '省控线', '批次']:
l.append(j.span.string[:3])
elif j != '\n' and j.string not in ['年份', '最高分', '平均分', '最低分', '省控线', '批次']:
l.append(j.string)
if l != []:
infolist_like.append(l)
#本科三批
flag3 = True
s1[-1] = '10038.htm'
url='/'.join(s1)
html= GetHtml(url)
soup = BeautifulSoup(html, 'html.parser')
soup2 = soup.find_all('tr')
for i in soup2:
for j in i:
if j.string == '暂时没有数据':
flag3 = False
if flag3:
for i in soup2:
l = []
cont = 0
for j in i:
cont += 1
if cont == 10 and j.string not in ['年份', '最高分', '平均分', '最低分', '省控线', '批次']:
l.append(j.span.string[:3])
elif j != '\n' and j.string not in ['年份', '最高分', '平均分', '最低分', '省控线', '批次']:
l.append(j.string)
if l != []:
infolist_like.append(l)
#专科批
flag4 = True
s1[-1] = '10155.htm'
url = '/'.join(s1)
html = GetHtml(url)
soup = BeautifulSoup(html, 'html.parser')
soup2 = soup.find_all('tr')
for i in soup2:
for j in i:
if j.string == '暂时没有数据':
flag4 = False
if flag4:
for i in soup2:
l = []
cont = 0
for j in i:
if cont == 10 and j.string not in ['年份', '最高分', '平均分', '最低分', '省控线', '批次']:
l.append(j.span.string[:3])
elif j != '\n' and j.string not in ['年份', '最高分', '平均分', '最低分', '省控线', '批次']:
l.append(j.string)
if l != []:
infolist_like.append(l)
for i in infolist_like:
print(i)
print("正在写入Excrl%s理科数据............"%info[0])
#创建工作簿((理科)指定编码
file=xlwt.Workbook(encoding='utf-8')
#创建表
table1=file.add_sheet(info[0]+'理科线')
value=['年份','最高分','平均分','最低分','省控线','批次','通讯地址']
table1.col(6).width=256*20
for i in range(len(value)):
table1.write(0,i,value[i])
table1.write(1,6,adress)
for i in range(len(infolist_like)):
for j in range(len(infolist_like[i])):
table1.write(i+1,j,infolist_like[i][j])
#*********************文科省控线*****************************#
#把理科转变成文科
s1[-2]='10034'
s1[-1]='10036.htm'
url = '/'.join(s1)
html = GetHtml(url)
soup=BeautifulSoup(html,'html.parser')
# 本科一批
flag1 = True
soup2 = soup.find_all('tr')
for i in soup2:
for j in i:
if j.string == '暂时没有数据':
flag1 = False
if flag1:
for i in soup2:
l = []
cont = 0
for j in i:
cont += 1
if cont == 10 and j.string not in ['年份', '最高分', '平均分', '最低分', '省控线', '批次']:
l.append(j.span.string[:3])
elif j != '\n' and j.string not in ['年份', '最高分', '平均分', '最低分', '省控线', '批次']:
l.append(j.string)
if l != []:
infolist_wenke.append(l)
# 本科二批
flag2 = True
s1[-1] = '10037.htm'
url = '/'.join(s1)
html = GetHtml(url)
soup = BeautifulSoup(html,'html.parser')
soup2 = soup.find_all('tr')
for i in soup2:
for j in i:
if j.string == '暂时没有数据':
flag2 = False
if flag2:
for i in soup2:
l = []
cont = 0
for j in i:
cont += 1
if cont == 10 and j.string not in ['年份', '最高分', '平均分', '最低分', '省控线', '批次']:
l.append(j.span.string[:3])
elif j != '\n' and j.string not in ['年份', '最高分', '平均分', '最低分', '省控线', '批次']:
l.append(j.string)
if l != []:
infolist_wenke.append(l)
# 本科三批
flag3 = True
s1[-1] = '10038.htm'
url='/'.join(s1)
html = GetHtml(url)
soup = BeautifulSoup(html, 'html.parser')
soup2 = soup.find_all('tr')
for i in soup2:
for j in i:
if j.string == '暂时没有数据':
flag3 = False
if flag3:
for i in soup2:
l = []
cont = 0
for j in i:
cont += 1
if cont == 10 and j.string not in ['年份', '最高分', '平均分', '最低分', '省控线', '批次']:
l.append(j.span.string[:3])
elif j != '\n' and j.string not in ['年份', '最高分', '平均分', '最低分', '省控线', '批次']:
l.append(j.string)
if l != []:
infolist_wenke.append(l)
# 专科批
flag4 = True
s1[-1] = '10155.htm'
url = '/'.join(s1)
html = GetHtml(url)
soup = BeautifulSoup(html, 'html.parser')
soup2 = soup.find_all('tr')
for i in soup2:
for j in i:
if j.string == '暂时没有数据':
flag4 = False
if flag4:
for i in soup2:
l = []
cont = 0
for j in i:
if cont == 10 and j.string not in ['年份', '最高分', '平均分', '最低分', '省控线', '批次']:
l.append(j.span.string[:3])
elif j != '\n' and j.string not in ['年份', '最高分', '平均分', '最低分', '省控线', '批次']:
l.append(j.string)
if l != []:
infolist_wenke.append(l)
for i in infolist_wenke:
print(i)
#创建文科省控
print("正在写入Excel%s文科数据........."%info[0])
table2=file.add_sheet("%s文科数据"%info[0])
value = ['年份', '最高分', '平均分', '最低分', '省控线', '批次', '通讯地址']
table2.col(6).width = 256 * 20
for i in range(len(value)):
table2.write(0, i, value[i])
table2.write(1, 6, adress)
for i in range(len(infolist_wenke)):
for j in range(len(infolist_wenke[i])):
table2.write(i + 1, j, infolist_wenke[i][j])上面的代码是可一直把最开始网址配合上面两个的函数,先把url传到search_University(url,info),然后再把info给
get_schoolAreaPoint(info)这个函数,就能打印保存Excel表了。接下来该爬取每个高校对四川的专业线:
专业线有三个参数,地区(默认所在高校的省份,),文理(默认理科),年份(默认2017)
方法同上,我们点击多个地区,年份,文理,分析得到网址,分析如下:

https://gkcx.eol.cn/schoolhtm/specialty/30/10035/specialtyScoreDetail_2017_10005.htm30是院校代码,10035是理科,10034文科,2017是年份,1005是省份代码
所以还是改网址,然后对改动后的网址进行访问,就能得到我们需要的网址,然后进行数据提取。
还是提出源代码:
#**********************每个高校对四川招生的专业录取线******************************
#专业数据是2008到2017
infolist_specialtyScore=[]
#2017理科
s2[-1]='specialtyScoreDetail_2017_10005.htm'
url='/'.join(s2)
html=GetHtml(url)
soup=BeautifulSoup(html,'html.parser').find_all('tr')
for i in soup:
l=[]
cont=0
for j in i:
cont+=1
if j.string not in ['专业名称', '年份', '最高分', '平均分', '最低分', '录取批次', '\n', '暂时没有数据', ' ', '']:
if cont==12:
l.append(j.string.strip())
else: l.append(j.string)
if l!=[]:
infolist_specialtyScore.append(l)
# 2016理科
s2[-1] = 'specialtyScoreDetail_2016_10005.htm'
url = '/'.join(s2)
html = GetHtml(url)
soup = BeautifulSoup(html, 'html.parser').find_all('tr')
for i in soup:
l = []
cont = 0
for j in i:
cont += 1
if j.string not in ['专业名称', '年份', '最高分', '平均分', '最低分', '录取批次', '\n', '暂时没有数据', ' ', '']:
if cont == 12:
l.append(j.string.strip())
else:
l.append(j.string)
if l != []:
infolist_specialtyScore.append(l)
# 2015理科
s2[-1] = 'specialtyScoreDetail_2015_10005.htm'
url = '/'.join(s2)
html = GetHtml(url)
soup = BeautifulSoup(html, 'html.parser').find_all('tr')
for i in soup:
l = []
cont = 0
for j in i:
cont += 1
if j.string not in ['专业名称', '年份', '最高分', '平均分', '最低分', '录取批次', '\n', '暂时没有数据', ' ', '']:
if cont == 12:
l.append(j.string.strip())
else:
l.append(j.string)
if l != []:
infolist_specialtyScore.append(l)
# 2014理科
s2[-1] = 'specialtyScoreDetail_2014_10005.htm'
url = '/'.join(s2)
html = GetHtml(url)
soup = BeautifulSoup(html, 'html.parser').find_all('tr')
for i in soup:
l = []
cont = 0
for j in i:
cont += 1
if j.string not in ['专业名称', '年份', '最高分', '平均分', '最低分', '录取批次', '\n', '暂时没有数据', ' ', '']:
if cont == 12:
l.append(j.string.strip())
else:
l.append(j.string)
if l != []:
infolist_specialtyScore.append(l)
# 2013理科
s2[-1] = 'specialtyScoreDetail_2013_10005.htm'
url = '/'.join(s2)
html = GetHtml(url)
soup = BeautifulSoup(html, 'html.parser').find_all('tr')
for i in soup:
l = []
cont = 0
for j in i:
cont += 1
if j.string not in ['专业名称', '年份', '最高分', '平均分', '最低分', '录取批次', '\n', '暂时没有数据', ' ', '']:
if cont == 12:
l.append(j.string.strip())
else:
l.append(j.string)
if l != []:
infolist_specialtyScore.append(l)
# 2012理科
s2[-1] = 'specialtyScoreDetail_2012_10005.htm'
url = '/'.join(s2)
html = GetHtml(url)
soup = BeautifulSoup(html, 'html.parser').find_all('tr')
for i in soup:
l = []
cont = 0
for j in i:
cont += 1
if j.string not in ['专业名称', '年份', '最高分', '平均分', '最低分', '录取批次', '\n', '暂时没有数据', ' ', '']:
if cont == 12:
l.append(j.string.strip())
else:
l.append(j.string)
if l != []:
infolist_specialtyScore.append(l)
# 2011理科
s2[-1] = 'specialtyScoreDetail_2011_10005.htm'
url = '/'.join(s2)
html = GetHtml(url)
soup = BeautifulSoup(html, 'html.parser').find_all('tr')
for i in soup:
l = []
cont = 0
for j in i:
cont += 1
if j.string not in ['专业名称', '年份', '最高分', '平均分', '最低分', '录取批次', '\n', '暂时没有数据', ' ', '']:
if cont == 12:
l.append(j.string.strip())
else:
l.append(j.string)
if l != []:
infolist_specialtyScore.append(l)
# 2010理科
s2[-1] = 'specialtyScoreDetail_2010_10005.htm'
url = '/'.join(s2)
html = GetHtml(url)
soup = BeautifulSoup(html, 'html.parser').find_all('tr')
for i in soup:
l = []
cont = 0
for j in i:
cont += 1
if j.string not in ['专业名称', '年份', '最高分', '平均分', '最低分', '录取批次', '\n', '暂时没有数据', ' ', '']:
if cont == 12:
l.append(j.string.strip())
else:
l.append(j.string)
if l != []:
infolist_specialtyScore.append(l)
# 2009理科
s2[-1] = 'specialtyScoreDetail_2009_10005.htm'
url = '/'.join(s2)
html = GetHtml(url)
soup = BeautifulSoup(html, 'html.parser').find_all('tr')
for i in soup:
l = []
cont = 0
for j in i:
cont += 1
if j.string not in ['专业名称', '年份', '最高分', '平均分', '最低分', '录取批次', '\n', '暂时没有数据', ' ', '']:
if cont == 12:
l.append(j.string.strip())
else:
l.append(j.string)
if l != []:
infolist_specialtyScore.append(l)
# 2008理科
s2[-1] = 'specialtyScoreDetail_2008_10005.htm'
url = '/'.join(s2)
html = GetHtml(url)
soup = BeautifulSoup(html, 'html.parser').find_all('tr')
for i in soup:
l = []
cont = 0
for j in i:
cont += 1
if j.string not in ['专业名称', '年份', '最高分', '平均分', '最低分', '录取批次', '\n', '暂时没有数据',' ','']:
if cont == 12:
l.append(j.string.strip())
else:
l.append(j.string)
if l != []:
infolist_specialtyScore.append(l)
#创建理科专业表
print("正在写入Excel%s理科专业数据........."%info[0])
table3=file.add_sheet(info[0]+"理科专业线")
value=['专业','年份','最高分','平均分','最低分','录取批次']
for i in range(len(value)):
table3.write(0,i,value[i])
for i in range(len(infolist_specialtyScore)):
for j in range(len(infolist_specialtyScore[i])):
table3.write(i+1,j,infolist_specialtyScore[i][j])
print("Excel%s理科专业数据写入成功!" % info[0])
#**********文科********
# 2017文科
#转换为文科代码
infolist_specialtyScore=[]
s2[-2]='10034'
s2[-1] = 'specialtyScoreDetail_2017_10005.htm'
url = '/'.join(s2)
html = GetHtml(url)
soup = BeautifulSoup(html, 'html.parser').find_all('tr')
for i in soup:
l = []
cont = 0
for j in i:
cont += 1
if j.string not in ['专业名称', '年份', '最高分', '平均分', '最低分', '录取批次', '\n', '暂时没有数据', ' ', '']:
if cont == 12:
l.append(j.string.strip())
else:
l.append(j.string)
if l != []:
infolist_specialtyScore.append(l)
# 2016文科
s2[-1] = 'specialtyScoreDetail_2016_10005.htm'
url = '/'.join(s2)
html = GetHtml(url)
soup = BeautifulSoup(html, 'html.parser').find_all('tr')
for i in soup:
l = []
cont = 0
for j in i:
cont += 1
if j.string not in ['专业名称', '年份', '最高分', '平均分', '最低分', '录取批次', '\n', '暂时没有数据', ' ', '']:
if cont == 12:
l.append(j.string.strip())
else:
l.append(j.string)
if l != []:
infolist_specialtyScore.append(l)
# 2015文科
s2[-1] = 'specialtyScoreDetail_2015_10005.htm'
url = '/'.join(s2)
html = GetHtml(url)
soup = BeautifulSoup(html, 'html.parser').find_all('tr')
for i in soup:
l = []
cont = 0
for j in i:
cont += 1
if j.string not in ['专业名称', '年份', '最高分', '平均分', '最低分', '录取批次', '\n', '暂时没有数据', ' ', '']:
if cont == 12:
l.append(j.string.strip())
else:
l.append(j.string)
if l != []:
infolist_specialtyScore.append(l)
# 2014文科
s2[-1] = 'specialtyScoreDetail_2014_10005.htm'
url = '/'.join(s2)
html = GetHtml(url)
soup = BeautifulSoup(html, 'html.parser').find_all('tr')
for i in soup:
l = []
cont = 0
for j in i:
cont += 1
if j.string not in ['专业名称', '年份', '最高分', '平均分', '最低分', '录取批次', '\n', '暂时没有数据', ' ', '']:
if cont == 12:
l.append(j.string.strip())
else:
l.append(j.string)
if l != []:
infolist_specialtyScore.append(l)
# 2013文科
s2[-1] = 'specialtyScoreDetail_2013_10005.htm'
url = '/'.join(s2)
html = GetHtml(url)
soup = BeautifulSoup(html, 'html.parser').find_all('tr')
for i in soup:
l = []
cont = 0
for j in i:
cont += 1
if j.string not in ['专业名称', '年份', '最高分', '平均分', '最低分', '录取批次', '\n', '暂时没有数据', ' ', '']:
if cont == 12:
l.append(j.string.strip())
else:
l.append(j.string)
if l != []:
infolist_specialtyScore.append(l)
# 2012文科
s2[-1] = 'specialtyScoreDetail_2012_10005.htm'
url = '/'.join(s2)
html = GetHtml(url)
soup = BeautifulSoup(html, 'html.parser').find_all('tr')
for i in soup:
l = []
cont = 0
for j in i:
cont += 1
if j.string not in ['专业名称', '年份', '最高分', '平均分', '最低分', '录取批次', '\n', '暂时没有数据', ' ', '']:
if cont == 12:
l.append(j.string.strip())
else:
l.append(j.string)
if l != []:
infolist_specialtyScore.append(l)
# 2011文科
s2[-1] = 'specialtyScoreDetail_2011_10005.htm'
url = '/'.join(s2)
html = GetHtml(url)
soup = BeautifulSoup(html, 'html.parser').find_all('tr')
for i in soup:
l = []
cont = 0
for j in i:
cont += 1
if j.string not in ['专业名称', '年份', '最高分', '平均分', '最低分', '录取批次', '\n', '暂时没有数据', ' ', '']:
if cont == 12:
l.append(j.string.strip())
else:
l.append(j.string)
if l != []:
infolist_specialtyScore.append(l)
# 2010文科
s2[-1] = 'specialtyScoreDetail_2010_10005.htm'
url = '/'.join(s2)
html = GetHtml(url)
soup = BeautifulSoup(html, 'html.parser').find_all('tr')
for i in soup:
l = []
cont = 0
for j in i:
cont += 1
if j.string not in ['专业名称', '年份', '最高分', '平均分', '最低分', '录取批次', '\n', '暂时没有数据', ' ', '']:
if cont == 12:
l.append(j.string.strip())
else:
l.append(j.string)
if l != []:
infolist_specialtyScore.append(l)
# 2009文科
s2[-1] = 'specialtyScoreDetail_2009_10005.htm'
url = '/'.join(s2)
html = GetHtml(url)
soup = BeautifulSoup(html, 'html.parser').find_all('tr')
for i in soup:
l = []
cont = 0
for j in i:
cont += 1
if j.string not in ['专业名称', '年份', '最高分', '平均分', '最低分', '录取批次', '\n', '暂时没有数据', ' ', '']:
if cont == 12:
l.append(j.string.strip())
else:
l.append(j.string)
if l != []:
infolist_specialtyScore.append(l)
# 2008文科
s2[-1] = 'specialtyScoreDetail_2008_10005.htm'
url = '/'.join(s2)
html = GetHtml(url)
soup = BeautifulSoup(html, 'html.parser').find_all('tr')
for i in soup:
l = []
cont = 0
for j in i:
cont += 1
if j.string not in ['专业名称', '年份', '最高分', '平均分', '最低分', '录取批次', '\n', '暂时没有数据', ' ', '']:
if cont == 12:
l.append(j.string.strip())
else:
l.append(j.string)
if l != []:
infolist_specialtyScore.append(l)
# 创建理科专业表
print("正在写入Excel%s文科专业数据........." % info[0])
table4 = file.add_sheet(info[0] + "文科专业线")
value = ['专业', '年份', '最高分', '平均分', '最低分', '录取批次']
for i in range(len(value)):
table4.write(0, i, value[i])
for i in range(len(infolist_specialtyScore)):
for j in range(len(infolist_specialtyScore[i])):
table4.write(i + 1, j, infolist_specialtyScore[i][j])
print("Excel%s文科专业数据写入成功!" % info[0])
for i in infolist_specialtyScore:
print(i)最后把excel保存一下,就是镇楼图那样一个学校一个表,每个表四页,省控理科线,省控文科线,专业理科线,专业文科线。
D:\QQPCMgr(1)\Desktop\高校数据/'这个是我在桌面创建的一个文件夹的路径,可以不指定路径,就会保存到当前程序运行的目录下。
#指定保存路径
file.save('D:\QQPCMgr(1)\Desktop\高校数据/' + info[0] + '录取数据.xls')
print("%s所有数据写入成功!" % info[0])最后附上main函数,函数入口
def main():
#text=open("全国高校.txt",'r').readlines()
start=time.perf_counter()
for i in range(30,2577):
info = []
url="https://gkcx.eol.cn/schoolhtm/schoolTemple/school"+str(i)+".htm"
print(url)
search_University(url,info)
print(info)
#特殊判断个别院校与其他多数学校差别(没有歧视的意思,个别学校网址或者其他数据问题),就跳过,否则一大堆错误,处理的脑壳疼
if len(info)<3 or info[1].strip()==info[2].strip() or "http:" in info[1].strip().split('/'):
continue
get_schoolAreaPoint(info)
print("查询第%d个学校"%(int(i)-29))
end=time.perf_counter()
print("花费时间:%.2f"%(end-start))
if __name__ == '__main__':
main()
博主就不贴出完整源代码了,几乎都贴出来了,因为博主爬取的数据好给项目组用,如果有人确实需完整,留言,看到后博主会回复你,根据情况私给源代码。这里博主要说一下,尽管处理了大部分特殊情况的学校但程序还是停掉,这里博主每次请求一个学校的时候打印了网址,里面有id,只需要重新在for循环,左边改成断掉的id就可以继续了,至于为什么为这样,可能是windows长时间运行程序会崩溃或者是楼主没处理好数据,或者还是有特殊学校没处理掉,或者用法问题......如果博主的思维和代码对您有用,记得点赞。
----------------------------------------------------------------内容到此结束---------------------------------------------------------------------------------------