ArrayList学习(源码解读笔记)
1.ArrayList:
简介: 底层由数组实现,是一个动态数组,可以自动扩容.
首先看一下继承实现关系:
![]()
可以看到继承了AbstractList,实现了List,RandomAccess,Cloneable,Serializable
逐一来说:
AbstractList: 首先可以看到是抽象类,但点进去看了之后会发现他只有一个抽象方法get():

这时我在想为什么只有get()用abstract修饰呢,于是看了下其他方法,发现一个事情,在AbstractList中,add,set等方法是直接抛异常的,表示有点看不懂.

于是我从网上查了一下UnsupportedOperationException异常,说是在执行Arrays.asList()会遇到;于是我点进去看了一下,

这下就很清晰了,他直接返回了一个new ArrayList<>(a);,但是这个arraylist是不是我们平时用的arrlist呢,大家接着点就会发现,其实并不是一个类,这个返回的ArrayList只是Arrays里的一个内部类而已

他也继承了AbstractList,但是并没有重写set等方法,因此他执行了父类的set方法,所以才会抛出异常.而我们平时使用的new ArrayList<>()是自己重写了set等方法的.并没有使用父类的方法

List:这个就不细说了,不过有一点疑问是AbstractList也实现了List,为何ArrayList还要再实现一边呢,看网上说法不一,留待以后研究吧.
RandomAccess: 点进去是空的… 表示有点懵,于是查了一下,它是一个标记接口,而LinkedList并没有实现该接口,在Collections下的binarySearch方法中有这样一行代码
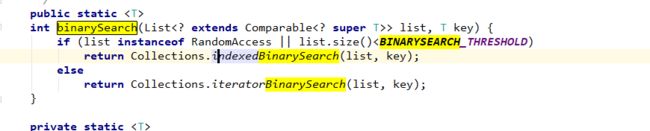
在二分查找的时候判断是否是RandomAccess的实例,不同的判断执行不同的方法(其中: BINARYSEARCH_THRESHOLD Collections的一个常量(5000),它是二分查找的阀值。)
然后看看两个方法的区别:

可以看出来indexedBinarySearch是通过get()访问元素,而iteratorBinarySearch是通过listIterator访问元素的,而两者有什么区别我也不知道.可以看看原博主链接RandomAccess接口理解,先留个坑,等回头再往深研究一下.
Cloneable: 点进去也是空的,应该也是一个标记接口,而clone方法直接定义在Object类中,clone必须要实现该接口,否则会报错CloneNotSupportedException;(对于clone了解不多,回头学习完更新)

而arrayList中也重写了clone方法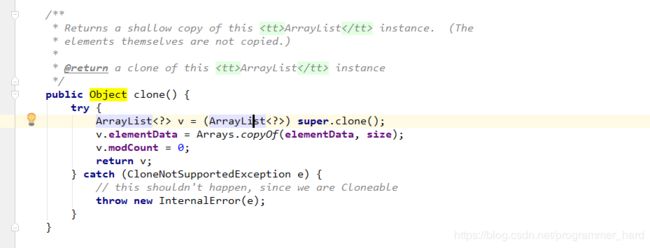
Serializable: 序列化,也是标记接口,
对象序列化是一个用于将对象状态转换为字节流的过程,可以将其保存到磁盘文件中或通过网络发送到任何其他程序;从字节流创建对象的相反的过程称为反序列化。而创建的字节流是与平台无关的,在一个平台上序列化的对象可以在不同的平台上反序列化.

序列化id,
如果用户没有自己声明一个serialVersionUID,接口会默认生成一个serialVersionUID
However, it is stronglyrecommended that all serializable classes explicitly declareserialVersionUID values, since the default serialVersionUID computation is highly sensitive to class details that may vary depending on compiler implementations, and can thus result in unexpectedInvalidClassExceptions during deserialization.
但是强烈建议用户自定义一个serialVersionUID,因为默认的serialVersinUID对于class的细节非常敏感,反序列化时可能会导致InvalidClassException这个异常。
顺便提一下transient关键字,它仅适用于变量,不适用于方法和类。代表不需要将该变量序列化.
今天先写到这,等下次学习的时候继续更新.