Spark基准测试平台BigDataBench使用教程
【Spark从菜鸟到入门】
- Spark初体验——wordcount词频统计
- Spark基础知识学习
- Spark单机版环境搭建
- Spark源码学习
- Spark分布式环境搭建
- Spark基准测试平台BigDataBench使用教程
1. BigDataBench简介
大数据系统的蓬勃发展催生了大数据基准测试的研究,如何公正地评价不同的大数据系统以及怎样根据需求选取合适的系统成为了热点问题.BigDataBench是一个跨系统、体系结构、数据管理 3个领域的大数据基准测试开源程序集.它覆盖5个典型的应用领域(搜索引擎、电子商务、社交网络、多媒体、生物信息),包含结构化、半结构化、非结构化的数据类型,涵盖离线分析、交互式分析、在线服务、Nosql这4种负载类型.目前包含14个真实数据集、3种类型的数据生成工具以及33个负载的不同软件栈实现.BigDataBench已广泛应用到学术界和工业界,应用案例包括负载分析、体系结构设计、系统优化等.基于 BigDataBench,中国信息通信研究院联合中国科学院计算技术研究所、华为等国内外知名公司和科研机构共同制定了国内首个工业标准的大数据平台性能评测标准[1].
论文所述大致步骤:
BigDataBench从5个典型的应用场景出发,选取了14个真实数据集和33个负载.针对不同的评测需求,具有不同的评测方法.以下主要分为5个基本的步骤来介绍其使用方法.
(1)根据评测需求选取合适的数据集以及对应负载(负载就是指对应程序)
(2)部署集群环境并下载安装BigDataBench
(3)使用数据生成工具BDGS生成指定规模的数据集
(5)运行负载并调优
(5)采集试验数据分析并得到评测结果
根据评测的指标和评测的目的菜鸡实验数据,如负载运行时间、吞吐量、系统层行为特征等,得出评测结果
简单来说:我们可以用它来生成一定规模的相同数据集,测试相同案例来进行平台性能的横向对比。
2. 使用教程
2.1 环境准备
(1)先启动Hadoop集群:
cd /usr/local/hadoop/
sbin/start-all.sh
(2)启动Master节点
在Master节点主机上运行如下命令:
cd /usr/local/spark/
sbin/start-master.sh
(3)启动所有Slave节点
在Master节点主机上运行如下命令:
sbin/start-slaves.sh
2.2 下载BigDataBench&&环境配置
官网链接:http://prof.ict.ac.cn/

对于spark平台的基准测试,去官网下载 BigDataBench_V5.0_Spark.tar.gz
ps: 虽然是说的V5.0.解压之后笔者发现还是V4.0
解压

配置文件
将conf.properties文件补充完整,一般是一些环境变量,比如spark_home/hadoop_home/scala_home等等,这些环境变量如果你之前有配过的话,可以在系统文件中找到。
比如我的相关配置就全都在 ~/.bashrc文件里。(要用sudo才能编辑哦)
conf.properties

~/.bashrc

2.3 编译gsl包
GSL(GNU Scientific Library)是一个 C 写成的用于科学计算的库,有超过1000个函数,该库提供了关于数学计算的很多方面,Matlab的大部分函数几乎都能借助它实现,可以在数值计算中省却很多事情。关于GSL的详细功能。
!!我之前,由于没有进行这一步,直接运行数据生成的脚本文件,就一直报这个错:
./gen_random_text: error while loading shared libraries: libgsl.so.0: cannot open...
大概是说,gen_random_text文件执行的时候找不到对应的动态链接库。加上我发现gen_random_text对应路径下竟然有一个gsl-1.15的压缩包??莫非要我先解压?于是我解压了尝试之下还是不行。后来才去查的gsl,原来是要先安装这个库。(笔者解压完了之后把文件名改成了gsl)
cd gsl
sudo ./configure
sudo make
sudo make install
3. 数据集生成
注意运行实例大部分都在MicroBenchmark文件夹中,使用-ls命令
并且每个文件夹里都有数据生成文件以及运行示例,这里以wordcount为例:

生成指定大小数据集
./genData_WordCount.sh
输入想要生成的GB大小,静静等待就行,你也可以打开50070端口,查看数据生成的情况。
这条命令结束之后,你可能会遇到两种错误:
如果遇到错误1
let not found
代表无法解析let命令,只需要把sh文件里面的第一行改成#!/bin/sh 改成#!/bin/bash即可。
如果遇到错误2
找不到spark/wordcount/data路径等诸如此类的错误
请打开对应的gen_data.sh文件,你会发现

注意最后几行,数据是要直接传到指定的hdfs路径下的,所以如果根目录没有 /spark 当然会报这个错误!
解决方案也很简单,直接建一个spark文件夹就行,之后的此类错误也是一样处理。
cd /usr/local/hadoop/bin
hadoop dfs -mkdir /spark
等结束就能在50070端口的webUI上看到最终生成的数据集
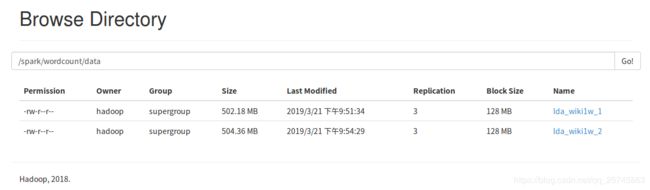
4. 运行测试用例
./run_WordCount.sh
生成的结果:

[1]詹剑锋,高婉铃,王磊,李经伟,魏凯,罗纯杰,韩锐,田昕晖,姜春宇.BigDataBench:开源的大数据系统评测基准[J].计算机学报,2016,39(01):196-211.