Python网络爬虫学习笔记(五)
微信公众号文章爬取
以搜狗的微信搜索平台“http://weixin.sogou.com/”作为爬取入口,可以在搜索栏输入相应关键词来搜索相关微信公众号文章。我们以“机器学习”作为搜索关键词。可以看到搜索后的地址栏中内容为:
http://weixin.sogou.com/weixin?query=%E6%9C%BA%E5%99%A8%E5%AD%A6%E4%B9%A0&_sug_type_=&sut=1872&lkt=1%2C1529474894686%2C1529474894686&s_from=input&_sug_=n&type=2&sst0=1529474894795&page=2&ie=utf8&w=01019900&dr=1
通过观察,可以发现这么几个关键字段:
- type:控制检索信息的类型
- query:我们请求的搜索关键词
- page:控制页数
所以我们的网址结构可以构造为:
http://weixin.sogou.com/weixin?query=关键词&type=2&page=页码
然后,我们在每一个搜索页中爬取文章的思路是:
- 检索对应关键词得到的相应文章检索结果,并在该页面中将文章的链接提取出来
- 在文章的链接被提取之后,根据这些链接地址采集文章中的具体标题和内容
通过查看文章列表页的源代码可以找到相应文章的URL以及要爬取的内容,列表页面如下:
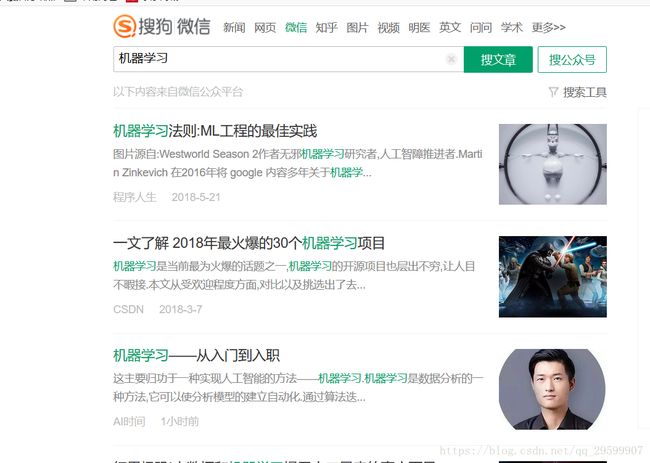
其中第一篇文章网址部分的源代码如下所示:
<div class="txt-box"> <h3> <a target="_blank" href="http://mp.weixin.qq.com/s?src=11&timestamp=1529474952&ver=949&signature=0bbGQd97t*BtkXHX8hm*5vzOJ5hP1xbyB-3Uda9BFURTSjUQi4GblEvJ5N1n3ERmEaIxk*y4uUHTN2PWAtwK4cHgTKKwehJDvUTi2Vb1dKjQ7TiUbYdsLJw4gxgb9DUP&new=1" id="sogou_vr_11002601_title_0" uigs="article_title_0" data-share="http://weixin.sogou.com/api/share?timestamp=1529474952&signature=qIbwY*nI6KU9tBso4VCd8lYSesxOYgLcHX5tlbqlMR8N6flDHs4LLcFgRw7FjTAOL84YqNadLQbOP2kLzeSXg42xKPjfOjB5HhrM9TPeVO8bQk02VHQRG*fTRKtIwL-rwPTOtpxH1qlGsRcpIT2RBRWAFmXKNr0J1vxWeDWjdaeaV7pdssvO5SYGM9-NiPIYrMQxFYhkweFryNOZhhuN4KQ8UuVMubqqxvnWtm6rWeA="><em>机器学习em>法则:ML工程的最佳实践a> h3> <p class="txt-info" id="sogou_vr_11002601_summary_0">图片源自:Westworld Season 2作者无邪<em>机器学习em>研究者,人工智障推进者.Martin Zinkevich 在2016年将 google 内容多年关于<em>机器学em>...p> <div class="s-p" t="1526875397"> <a class="account" target="_blank" id="sogou_vr_11002601_account_0" i="oIWsFt4wkuRLzlie2VEGsSMcZtQY" href="http://mp.weixin.qq.com/profile?src=3&timestamp=1529474952&ver=1&signature=xzEqAcKcWSNpWzpYj*V3TBENWQeDjz*mAl9WqGMKejsjIRG414KwgKlQ5SL4liA46lS4OB26i*ogELrshujJIg==" data-headimage="http://wx.qlogo.cn/mmhead/Q3auHgzwzM7hzd0AzpaOelnG1Mf6mgjOibSYtz4QiclQibAsOBtQL0kicg/0" data-isV="1" uigs="article_account_0">程序人生a><span class="s2"><script>document.write(timeConvert('1526875397'))script>span> <div class="moe-box"> <span style="display:none;" class="sc"><a data-except="1" class="sc-a" href="javascript:void(0)" uigs="share_0">a>span><span style="display:none;" class="fx"><a data-except="1" class="fx-a" href="javascript:void(0)" uigs="like_0">a>span> div> div>
所以我们可以将提取文章网址的正则表达式构造为:
'
这样就可以根据相关函数与代码提取出指定页数的文章网址。但是根据正则表达式提取出的网址不是真实地址,会出现参数错误。提取出的地址比真实地址多了一些“&;”字符串,我们通过url.replace("amp;","")去掉多余字符串。
这样就提取了文章的地址,可以根据文章地址爬取相应网页,并通过代理服务器的方法,解决官方屏蔽IP的问题。
整个爬取微信文章的思路如下:
- 建立三个自定义函数:实现使用代理服务器爬去指定网址并返回结果;实现获得多个页面的所有文章链接;实现根据文章链接爬取指定标题和内容并写入文件中。
- 使用代理服务器爬取指定网址的内容
- 实现获取多个页面的所有文章链接时,需要对关键词使用urllib.request.quote(key)进行编码,并通过for循环一次爬取各页的文章中设置的服务器函数实现。
- 实现根据文章链接爬取指定标题和内容写入对应文件,使用for循环一次爬取。
- 代码中如果发生异常,要进行延时处理。
具体代码如下:
import re
import time
import urllib.request
import urllib.error
#模拟成浏览器
headers=("User-Agent","Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/55.0.2883.87 Safari/537.36")
opener=urllib.request.build_opener()
opener.addheaders=[headers]
urllib.request.install_opener(opener)
listurl=[]
"""使用代理服务器"""
def use_proxy(proxy_addr,url):
try:
proxy=urllib.request.ProxyHandler({'http':proxy_addr})
opener=urllib.request.build_opener(proxy,urllib.request.HTTPHandler)
urllib.request.install_opener(opener)
data=urllib.request.urlopen(url).read().decode('utf-8')
return data
except urllib.error.URLError as e:
if hasattr(e,"code"):
print(e.code)
if hasattr(e,"reason"):
print(e.reason)
time.sleep(10) #若出现异常,则延迟10秒执行
except Exception as e:
print("exception:"+str(e))
time.sleep(1) #若出现其他异常,则延迟1秒
"""获取所有文章链接"""
def getlisturl(key,pagestart,pageend,proxy):
try:
page=pagestart #初始化页码
keycode=urllib.request.quote(key) #编码关键词
pagecode=urllib.request.quote("&page") #因为有&所以要编码
for page in range(pagestart,pageend+1): #循环爬取每一页的文章链接
url="http://weixin.sogou.com/weixin?query="+keycode+"&type=2"+pagecode+str(page) #各页的url
data1=use_proxy(proxy,url) #使用代理服务器爬取该页所有内容
listurlpat='.*?(http://.*?)"' #用于过滤出文章链接的正则表达式
listurl.append(re.compile(listurlpat,re.S).findall(data1)) #获取每一页的文章链接,加入列表中
print("共获取"+str(len(listurl))+"页")
return listurl
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
time.sleep(10) # 若出现异常,则延迟10秒执行
except Exception as e:
print("exception:" + str(e))
time.sleep(1) # 若出现其他异常,则延迟1秒
"""通过文章链接获取对应内容"""
def getcontent(listurl,proxy):
pagenum=0
#设置本地文件中的开始html编码
#将'''包含的内容赋值给一个变量,即变量以引号内的格式存储字符串
html1='''
微信文章页面
'''
fh=open("D:\\PyCharm\\workplace\\Crawler\\WeChat\\1.html","wb")
fh.write(html1.encode("utf-8"))
fh.close()
fh=open("D:\\PyCharm\\workplace\\Crawler\\WeChat\\1.html","ab") #以写方式打开文件,以写入对应文章内容
#此时的listurl是一个二维列表,第一维是跟页码有关,第二维才是当前页码中的第几篇文章
for pagenum in range(0,len(listurl)):
for articlenum in range(0,len(listurl[pagenum])):
try:
url=listurl[pagenum][articlenum] #获取第pagenum页的第articlenum篇文章的url
url=url.replace("amp;","") #将正则表达式得到的url处理成真实的url
data=use_proxy(proxy,url) #获取文章内容
titlepat="(.*?) " #文章标题的正则表达式
contentpat='id="js_content">(.*?)id="js_sg_bar' #文章内容的正则表达式
title=re.compile(titlepat).findall(data)
content=re.compile(contentpat,re.S).findall(data)
#初始化标题内容
thistitle="此次没有获取到"
thiscontent="此次没有获取到"
if(title!=[]):
thistitle=title[0]
if(content!=[]):
thiscontent=content[0]
dataall="标题为:"+thistitle+"
内容为:"+thiscontent+"
" #将标题和内容赋值给dataall以存入文件
fh.write(dataall.encode("utf-8"))
print("第"+str(pagenum)+"个网页,第"+str(articlenum)+"篇文章处理")
except urllib.error.URLError as e:
if hasattr(e, "code"):
print(e.code)
if hasattr(e, "reason"):
print(e.reason)
time.sleep(10) # 若出现异常,则延迟10秒执行
except Exception as e:
print("exception:" + str(e))
time.sleep(1) # 若出现其他异常,则延迟1秒
fh.close()
#设置并写入本地文件的html后面结束部分代码
html2=''''''
fh=open("D:\\PyCharm\\workplace\\Crawler\\WeChat\\1.html","ab")
fh.write(html2.encode("utf-8"))
fh.close()
if __name__=='__main__':
key="机器学习"
proxy_addr = "115.212.37.207:9000"
pagestrat=1
pageend=2
listurl=getlisturl(key,pagestrat,pageend,proxy_addr)
getcontent(listurl,proxy_addr)