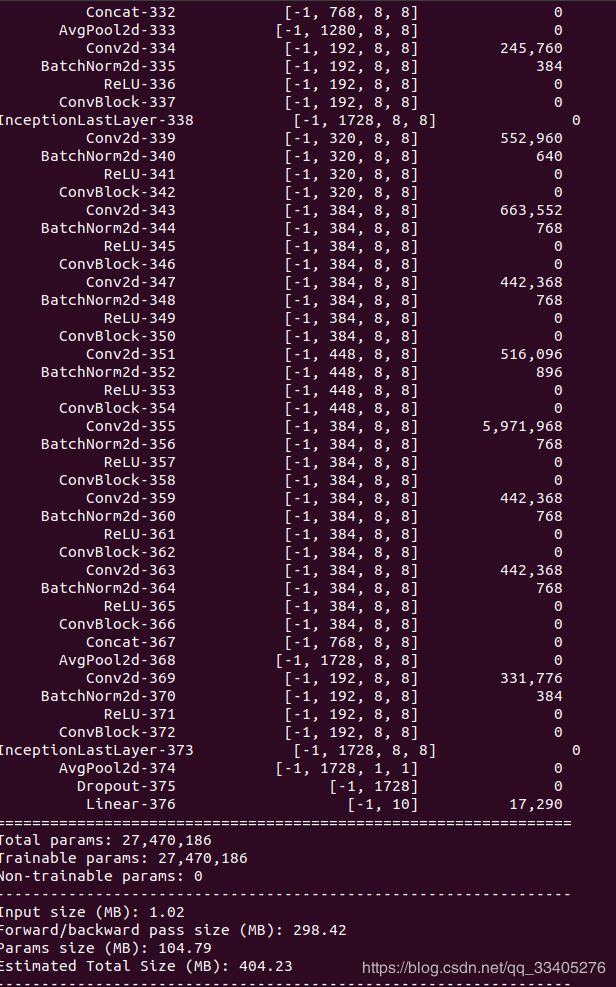
pytorch实现InceptionV3模型,Cifar10数据集测试
1、GoogleNet的InceptionV3结构
Google的InceptionV3版本以前的模型,有着以下改进部分:
前期模型构造,自己在V1、V2版本中并没有加入BN,加快模型收敛,这是考虑模型更深更广,训练难度大,而且也容易出现差错,自己也考虑在V2、V1模型加入BN,具体的测试对比和代码会将其放在github上。
# 自己封装的BN+ReLU模型
#
class ConvBlock(nn.Module):
def __init__(self,in_channel,out_channel,k,s,p,bias=False):
super(ConvBlock,self).__init__()
self.conv =nn.Sequential( nn.Conv2d(
in_channel,out_channel,kernel_size=k,stride=s, padding=p,bias=bias),
nn.BatchNorm2d(out_channel),
nn.ReLU(inplace=True),
)
def forward(self,x):
x = self.conv(x)
return x模型有着以下分支改进:
class InceptionV3base(nn.Module):
def __init__(self, in_channel,layers=[64,48,64,64,96,96,32] ):
super(InceptionV3base,self).__init__()
self.branch1 = nn.Sequential(
nn.Conv2d(in_channel,layers[0],kernel_size=1,stride=1,padding=0 ,bias=False),
nn.BatchNorm2d(layers[0]),
nn.ReLU(inplace=True),
)
self.branch2 = nn.Sequential(
nn.Conv2d(in_channel,layers[1],1,stride=1,padding=0,bias=False),
nn.BatchNorm2d(layers[1]),
nn.ReLU(inplace=True),
nn.Conv2d(layers[1],layers[2],5,stride=1,padding=2,bias=False),
nn.BatchNorm2d(layers[2]),
nn.ReLU(True),
)
self.branch3 = nn.Sequential(
nn.Conv2d(in_channel,layers[3],kernel_size=1,stride=1,padding=0,bias=False),
nn.BatchNorm2d(layers[3]),
nn.ReLU(inplace=True),
nn.Conv2d(layers[3],layers[4],kernel_size=3,stride=1,padding=1,bias=False),
nn.BatchNorm2d(layers[4]),
nn.ReLU(inplace=True),
nn.Conv2d(layers[4],layers[5],kernel_size=3,stride=1,padding=1,bias=False),
nn.BatchNorm2d(layers[5]),
nn.ReLU(inplace=True),
)
self.branch4 = nn.Sequential(
nn.AvgPool2d(kernel_size=3,stride=1,padding=1),
nn.Conv2d(in_channel,layers[6],1,stride=1,padding=0,bias=False),
nn.BatchNorm2d(layers[6]),
nn.ReLU(inplace=True),
)
def forward(self,x):
b1 = self.branch1(x)
b2 = self.branch2(x)
b3 = self.branch3(x)
b4 = self.branch4(x)
return torch.cat([b1,b2,b3,b4],dim=1)模型中为我们提供一个novel思路用1*7 和7*1 的并行网络结构去代替7*7结构,这里实际上减少了大量的参数计算,也放大我们的视野提取更多特征:
#
# # 1*7 and 7*1 block
#
class InceptionV3Block(nn.Module):
def __init__(self,in_channel,layers=[192,128,128,192,128,128,128,128,192,192],block=ConvBlock):
super(InceptionV3Block,self).__init__()
self.branch1 = nn.Sequential(
block(in_channel,layers[0],1,1,0),)
self.branch2 = nn.Sequential(
block(in_channel,layers[1],1,1,0),
block(layers[1],layers[2],(1,7),1,(0,3)),
block(layers[2],layers[3],(7,1),1,(3,0)),
)
self.branch3 = nn.Sequential(
block(in_channel,layers[4],1,1,0),
block(layers[4],layers[5],(7,1),1,(3,0)),
block(layers[5],layers[6],(1,7),1,(0,3)),
block(layers[6],layers[7],(7,1),1,(3,0)),
block(layers[7],layers[8],(1,7),1,(0,3)),
)
self.branch4 = nn.Sequential(
nn.AvgPool2d(3,1,padding=1),
block(in_channel,layers[9],1,1,0),
)
def forward(self,x):
b1 = self.branch1(x)
b2 = self.branch2(x)
b3 = self.branch3(x)
b4 = self.branch4(x)
return torch.cat([b1,b2,b3,b4],dim=1)
#同样在相对于V2模型中也是有着一个stride_block//2结构,这里有着两者的对比,实际上V3使用在1*7and7*1结构去替代了3*3,视野更加大,这在2016年以后的Semantic Segment中去提取特征中应用很广,这里大家可以最近一篇Huikai Wu ...:FastFCN:Rethinking Dilated Convlution in the Backbone for Semantic Segment:
class Inceptionv2_dicount(nn.Module):
def __init__(self,in_channel,layers=[128,160,64,96,96]):
super(Inceptionv2_dicount,self).__init__()
self.branch1 = nn.Sequential(
nn.Conv2d(in_channel,layers[0],1,stride=1,padding=0,bias=False),
nn.ReLU6(inplace=True),
nn.Conv2d(layers[0],layers[1],3, stride=2,padding=1,bias=False),
nn.ReLU6(inplace=True),
)
self.branch2 = nn.Sequential(
nn.Conv2d(in_channel,layers[2],1,stride=1,padding=0,bias=False),
nn.ReLU6(True),
nn.Conv2d(layers[2],layers[3],3,stride=1,padding=1,bias=False),
nn.ReLU6(inplace=True),
nn.Conv2d(layers[3],layers[4],3,stride=2,padding=1,bias=False),
nn.ReLU6(inplace=True),
)
self.branch3 = nn.Sequential(
nn.MaxPool2d(3,stride=2,padding=1),
)
def forward(self,x):
b1 = self.branch1(x)
b2 = self.branch2(x)
b3 = self.branch3(x)
return torch.cat([b1,b2,b3],dim=1)
# InceptionV3 减去2的结构
class InceptionV3Substraction(nn.Module):
def __init__(self,in_channel,layers=[192,320,192,192,192,192],block=ConvBlock):
super(InceptionV3Substraction,self).__init__()
self.branch1 = nn.Sequential(
block(in_channel,layers[0],1,1,0),
block(layers[0],layers[1],3,2,0),
)
self.branch2 = nn.Sequential(
block(in_channel,layers[2],1,1,0),
block(layers[2],layers[3],(1,7),1,(0,3)),
block(layers[3],layers[4],(7,1),1,(3,0)),
block(layers[4],layers[5],(3,3),2,0),
)
self.branch3 = nn.Sequential(
nn.MaxPool2d(3,stride=2,padding=0),
)
def forward(self,x):
b1 = self.branch1(x)
b2 = self.branch2(x)
b3 = self.branch3(x)
return torch.cat([b1,b2,b3],dim=1)最低层并行特征提取结构:
class InceptionLastLayer(nn.Module):
def __init__(self,in_channel,layers=[320,384,384,448,384,384,384,192],block=ConvBlock,concat=Concat):
super(InceptionLastLayer,self).__init__()
self.branch1 = nn.Sequential(
block(in_channel,layers[0],1,1,0),
)
self.branch2 = nn.Sequential(
block(in_channel,layers[1],1,1,0),
block(layers[1],layers[2],(1,3),1,(0,1)),
block(layers[2],layers[3],(3,1),1,(1,0)),
)
self.branch3 = nn.Sequential(
block(in_channel,layers[4],(3,3),1,1),
concat(layers[4],[layers[5],layers[6]] ),
)
self.branch4 = nn.Sequential(
nn.AvgPool2d(3,1,padding=1),
block(in_channel,layers[7],1,1,0),)
def forward(self,x):
b1 = self.branch1(x)
b2 = self.branch2(x)
b3 = self.branch3(x)
b4 = self.branch4(x)
return torch.cat([b1,b2,b3,b4],dim=1)2、整体网络实现
"""
InceptionV3 model from http://arxiv.org/abs/1512.00567.
"""
class ConvBlock(nn.Module):
def __init__(self,in_channel,out_channel,k,s,p,bias=False):
super(ConvBlock,self).__init__()
self.conv =nn.Sequential( nn.Conv2d(
in_channel,out_channel,kernel_size=k,stride=s, padding=p,bias=bias),
nn.BatchNorm2d(out_channel),
nn.ReLU(inplace=True),
)
def forward(self,x):
x = self.conv(x)
return x
class InceptionV3base(nn.Module):
def __init__(self, in_channel,layers=[64,48,64,64,96,96,32] ):
super(InceptionV3base,self).__init__()
self.branch1 = nn.Sequential(
nn.Conv2d(in_channel,layers[0],kernel_size=1,stride=1,padding=0 ,bias=False),
nn.BatchNorm2d(layers[0]),
nn.ReLU(inplace=True),
)
self.branch2 = nn.Sequential(
nn.Conv2d(in_channel,layers[1],1,stride=1,padding=0,bias=False),
nn.BatchNorm2d(layers[1]),
nn.ReLU(inplace=True),
nn.Conv2d(layers[1],layers[2],5,stride=1,padding=2,bias=False),
nn.BatchNorm2d(layers[2]),
nn.ReLU(True),
)
self.branch3 = nn.Sequential(
nn.Conv2d(in_channel,layers[3],kernel_size=1,stride=1,padding=0,bias=False),
nn.BatchNorm2d(layers[3]),
nn.ReLU(inplace=True),
nn.Conv2d(layers[3],layers[4],kernel_size=3,stride=1,padding=1,bias=False),
nn.BatchNorm2d(layers[4]),
nn.ReLU(inplace=True),
nn.Conv2d(layers[4],layers[5],kernel_size=3,stride=1,padding=1,bias=False),
nn.BatchNorm2d(layers[5]),
nn.ReLU(inplace=True),
)
self.branch4 = nn.Sequential(
nn.AvgPool2d(kernel_size=3,stride=1,padding=1),
nn.Conv2d(in_channel,layers[6],1,stride=1,padding=0,bias=False),
nn.BatchNorm2d(layers[6]),
nn.ReLU(inplace=True),
)
def forward(self,x):
b1 = self.branch1(x)
b2 = self.branch2(x)
b3 = self.branch3(x)
b4 = self.branch4(x)
return torch.cat([b1,b2,b3,b4],dim=1)
class InceptionV3_discount(nn.Module):
def __init__(self,in_channel,layers=[384,64,96,96],block=ConvBlock):
super(InceptionV3_discount,self).__init__()
self.branch1 = nn.Sequential(
block(in_channel,layers[0],3,2,0),
)
self.branch2 = nn.Sequential(
block(in_channel,layers[1],1,1,0),
block(layers[1],layers[2],3,1,1),
block(layers[2],layers[3],3,2,0),
)
self.branch3 = nn.Sequential(
nn.MaxPool2d(3,2,padding=0),
)
def forward(self,x):
b1 = self.branch1(x)
b2 = self.branch2(x)
b3 = self.branch3(x)
return torch.cat([b1,b2,b3],dim=1)
#
# # 1*7 and 7*1 block
#
class InceptionV3Block(nn.Module):
def __init__(self,in_channel,layers=[192,128,128,192,128,128,128,128,192,192],block=ConvBlock):
super(InceptionV3Block,self).__init__()
self.branch1 = nn.Sequential(
block(in_channel,layers[0],1,1,0),)
self.branch2 = nn.Sequential(
block(in_channel,layers[1],1,1,0),
block(layers[1],layers[2],(1,7),1,(0,3)),
block(layers[2],layers[3],(7,1),1,(3,0)),
)
self.branch3 = nn.Sequential(
block(in_channel,layers[4],1,1,0),
block(layers[4],layers[5],(7,1),1,(3,0)),
block(layers[5],layers[6],(1,7),1,(0,3)),
block(layers[6],layers[7],(7,1),1,(3,0)),
block(layers[7],layers[8],(1,7),1,(0,3)),
)
self.branch4 = nn.Sequential(
nn.AvgPool2d(3,1,padding=1),
block(in_channel,layers[9],1,1,0),
)
def forward(self,x):
b1 = self.branch1(x)
b2 = self.branch2(x)
b3 = self.branch3(x)
b4 = self.branch4(x)
return torch.cat([b1,b2,b3,b4],dim=1)
#
#
# 3*3
#
class InceptionV3Substraction(nn.Module):
def __init__(self,in_channel,layers=[192,320,192,192,192,192],block=ConvBlock):
super(InceptionV3Substraction,self).__init__()
self.branch1 = nn.Sequential(
block(in_channel,layers[0],1,1,0),
block(layers[0],layers[1],3,2,0),
)
self.branch2 = nn.Sequential(
block(in_channel,layers[2],1,1,0),
block(layers[2],layers[3],(1,7),1,(0,3)),
block(layers[3],layers[4],(7,1),1,(3,0)),
block(layers[4],layers[5],(3,3),2,0),
)
self.branch3 = nn.Sequential(
nn.MaxPool2d(3,stride=2,padding=0),
)
def forward(self,x):
b1 = self.branch1(x)
b2 = self.branch2(x)
b3 = self.branch3(x)
return torch.cat([b1,b2,b3],dim=1)
class Concat(nn.Module):
def __init__(self,in_channel,layers=[384,384],block=ConvBlock):
super(Concat,self).__init__()
self.branch1 = nn.Sequential(
block(in_channel,layers[0],(1,3),1,(0,1)),
)
self.branch2 = nn.Sequential(
block(in_channel,layers[1],(3,1),1,(1,0)),
)
def forward(self,x):
b1 = self.branch1(x)
b2 = self.branch2(x)
return torch.cat([b1,b2],dim=1)
class InceptionLastLayer(nn.Module):
def __init__(self,in_channel,layers=[320,384,384,448,384,384,384,192],block=ConvBlock,concat=Concat):
super(InceptionLastLayer,self).__init__()
self.branch1 = nn.Sequential(
block(in_channel,layers[0],1,1,0),
)
self.branch2 = nn.Sequential(
block(in_channel,layers[1],1,1,0),
block(layers[1],layers[2],(1,3),1,(0,1)),
block(layers[2],layers[3],(3,1),1,(1,0)),
)
self.branch3 = nn.Sequential(
block(in_channel,layers[4],(3,3),1,1),
concat(layers[4],[layers[5],layers[6]] ),
)
self.branch4 = nn.Sequential(
nn.AvgPool2d(3,1,padding=1),
block(in_channel,layers[7],1,1,0),)
def forward(self,x):
b1 = self.branch1(x)
b2 = self.branch2(x)
b3 = self.branch3(x)
b4 = self.branch4(x)
return torch.cat([b1,b2,b3,b4],dim=1)
Inceptionv3_shape = 299
class InceptionV3(nn.Module):
def __init__(self,num_class,block=ConvBlock,base=InceptionV3base,dicount=InceptionV3_discount,base7block=InceptionV3Block,
Substraction=InceptionV3Substraction,lastblock=InceptionLastLayer):
super(InceptionV3,self).__init__()
self.bottle = nn.Sequential(
block(3,32,3,2,0),
block(32,32,3,1,0),
block(32,64,3,1,1),
nn.MaxPool2d(3,2,padding=0),
block(64,80,1,1,0),
block(80,192,3,1,0),
nn.MaxPool2d(3,2,padding=0),
)
##### 192*35*35
self.layer1 = nn.Sequential(base(192))
self.layer2 = nn.Sequential(base(256,[64,48,64,64,96,96,64]))
self.layer3 = nn.Sequential(base(288,[64,48,64,64,96,96,64]))
self.layer4 = nn.Sequential(dicount(288))
self.layer5 = nn.Sequential(base7block(768))
self.layer6 = nn.Sequential(base7block(768,[192,160,160,192,160,160,160,160,192,192]))
self.layer7 = nn.Sequential(base7block(768,[192,160,160,192,160,160,160,160,192,192]))
self.layer8 = nn.Sequential(base7block(768,[192,192,192,192,192,192,192,192,192,192]))
self.layer9 = nn.Sequential(Substraction(768))
self.layer10 = nn.Sequential(
lastblock(1280),)
self.layer11 = nn.Sequential(lastblock(1728))
self.avg = nn.AvgPool2d(8,stride=1,padding=0)
self.fc = nn.Sequential(nn.Dropout(p=0.8),nn.Linear(1728,num_class),)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, (2. / n)**.5)
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m,nn.Linear):
m.weight.data.normal_(0,0.001)
m.bias.data.zero_()
def forward(self,x):
x = self.bottle(x)
x = self.layer1(x)
x = self.layer2(x)
x =self.layer3(x)
x = self.layer4(x)
x = self.layer5(x)
x =self.layer6(x)
x = self.layer7(x)
x = self.layer8(x)
x =self.layer9(x)
x =self.layer10(x)
x = self.layer11(x)
x = self.avg(x)
x = x.view(x.size(0),-1)
x =self.fc(x)
prob = F.softmax(x)
return x , prob4、实验测试
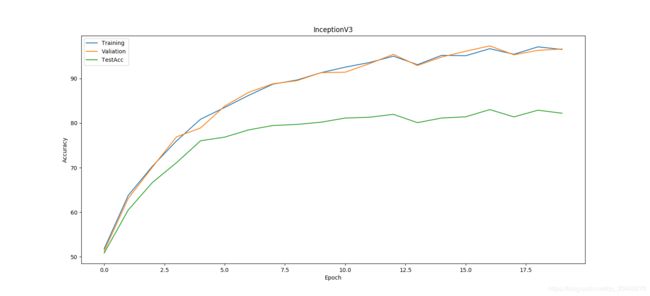
测试数据较大,自己只是在20epoch范围测试,但是后期自己会总结出,一些常见模型的训练对比和一些相关的数据,特征网络是我们在家下来工作中的基础,后面工作是否有效很大程度在于其backbone。