0x00 目标
学习目标有四个:
无量纲化:最值归一化、均值方差归一化及sklearn中的Scaler;
缺失值处理;
处理分类型特征:编码与哑变量;
处理连续型特征:二值化与分段。
0x01 归一化
在量纲(指物理量的基本属性)不同的情况下进行建模,不能反映样本中每一个特征的重要程度,所以就需要数据归一化。
常用的两种数据归一化:
最值归一化(normalization): 把所有数据映射到0-1之间。最值归一化的使用范围是特征的分布具有明显边界的(分数0~100分、灰度0~255),受outlier的影响比较大。

均值方差归一化(standardization): 把所有数据归一到均值为0方差为1的分布中。适用于数据中没有明显的边界,有可能存在极端数据值的情况。
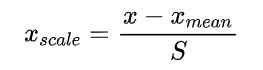
实际归一化时可能出现的小陷阱:建模时要将数据集划分为训练数据集&测试数据集,训练数据集进行归一化处理,需要计算出训练数据集的均值train_mean和方差std_train。在对测试数据集进行归一化时,仍要使用训练数据集的均值和方差。
因为测试数据是模拟的真实环境,真实环境中可能无法得到均值和方差,对数据进行归一化。只能够使用公式(x_test - mean_train) / std_train并且,数据归一化也是算法的一部分,针对后面所有的数据,也应该做相同处理。
0x02 KD树( kNN优化 )
2.1KD树原理
KD树是一种二叉树,是一种对k维空间中的实例点进行存储以便对其进行快速检索的树形数据结构,表示对k维空间的一个划分。
k-d tree是每个节点均为k维样本点的二叉树,其上的每个样本点代表一个超平面,该超平面垂直于当前划分维度的坐标轴,并在该维度上将空间划分为两部分,一部分在其左子树,另一部分在其右子树。即若当前节点的划分维度为d,其左子树上所有点在d维的坐标值均小于当前值,右子树上所有点在d维的坐标值均大于等于当前值,本定义对其任意子节点均成立。
2.2 KD树的构建
常规构建过程:
1.循环依序取数据点的各维度来作为切分维度,
2.取数据点在该维度的中值作为切分超平面,
3.将中值左侧的数据点挂在其左子树,将中值右侧的数据点挂在其右子树,
4.递归处理其子树,直至所有数据点挂载完毕。
对于构建过程,有两个优化点:
选择切分维度:根据数据点在各维度上的分布情况,方差越大,分布越分散,从方差大的维度开始切分,有较好的切分效果和平衡性。
确定中值点:预先对原始数据点在所有维度进行一次排序,存储下来,然后在后续的中值选择中,无须每次都对其子集进行排序,提升了性能。也可以从原始数据点中随机选择固定数目的点,然后对其进行排序,每次从这些样本点中取中值,来作为分割超平面。该方式在实践中被证明可以取得很好性能及很好的平衡性。
2.3 KD树的检索
引用:

0x03 特征工程
数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。由此可见,特征工程在机器学习中占有相当重要的地位。
特征工程是利用数据领域的相关知识来创建能够使机器学习算法达到最佳性能的特征的过程。
特征工程又包含了Data PreProcessing(数据预处理)、Feature Extraction(特征提取)、Feature Selection(特征选择)和Feature construction(特征构造)等子问题,而数据预处理又包括了数据清洗和特征预处理等子问题,本章内容主要讨论数据预处理的方法及实现。
3.1 特征预处理介绍
特征预处理包括无量纲化、特征分桶、统计变换和特征编码等步骤:
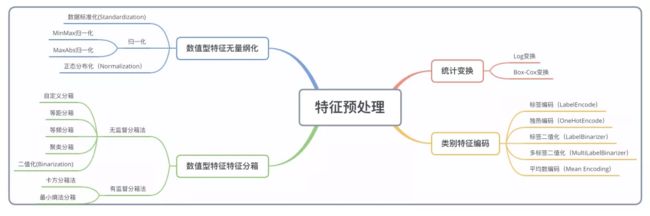
3.2数值型特征无量纲化
无量纲化使不同规格的数据转换到同一规格。常见的无量纲化方法有标准化和归一化。
数据标准化的原因:
某些算法要求样本具有零均值和单位方差;
需要消除样本不同属性具有不同量级时的影响。
归一化有可能提高精度;
数量级的差异将导致量级较大的属性占据主导地位,从而与实际情况相悖(比如这时实际情况是值域范围小的特征更重要);
数量级的差异将导致迭代收敛速度减慢;
当使用梯度下降法寻求最优解时,很有可能走“之字型”路线(垂直等高线走),从而导致需要迭代很多次才能收敛;
依赖于样本距离的算法对于数据的数量级非常敏感。
3.2.1 数据标准化(Standardization)
标准化的前提是特征值服从正态分布,标准化后,其转换成标准正态分布。
基于原始数据的均值(mean)和标准差(standarddeviation)进行数据的标准化。将A的原始值x使用z-score标准化到x’。z-score标准化方法适用于属性A的最大值和最小值未知的情况,或有超出取值范围的离群数据的情况。
标准化公式:
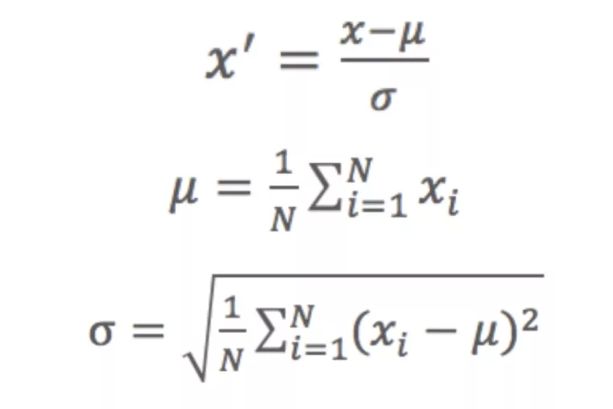
均值和标准差都是在样本集上定义的,而不是在单个样本上定义的。标准化是针对某个属性的,需要用到所有样本在该属性上的值。
优点:
Z-Score最大的优点就是简单,容易计算,Z-Score能够应用于数值型的数据,并且不受数据量级的影响,因为它本身的作用就是消除量级给分析带来的不便。
缺点:
估算Z-Score需要总体的平均值与方差,但是这一值在真实的分析与挖掘中很难得到,大多数情况下是用样本的均值与标准差替代;
Z-Score对于数据的分布有一定的要求,正态分布是最有利于Z-Score计算的;
Z-Score消除了数据具有的实际意义,Z-Score的结果只能用于比较数据间的结果,数据的真实意义还需要还原原值;
在存在异常值时无法保证平衡的特征尺度。
3.2.2 归一化
1)MinMax归一化
区间缩放法利用了边界值信息,将属性缩放到[0,1]。
公式:
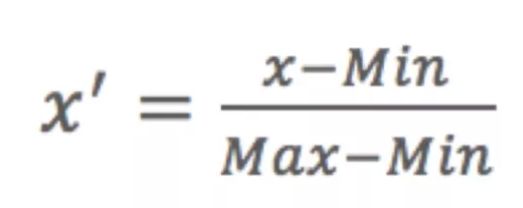
缺点:
这种方法有一个缺陷就是当有新数据加入时,可能导致max和min的变化,需要重新定义;
MinMaxScaler对异常值的存在非常敏感。
2)MaxAbs归一化
单独地缩放和转换每个特征,使得训练集中的每个特征的最大绝对值将为1.0,将属性缩放到[-1,1]。它不会移动/居中数据,因此不会破坏任何稀疏性。
MaxAbs公式:
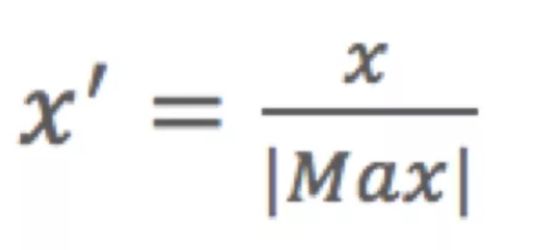
缺点:
这种方法有一个缺陷就是当有新数据加入时,可能导致max和min的变化,需要重新定义;
MaxAbsScaler与先前的缩放器不同,绝对值映射在[0,1]范围内。
在仅有正数据时,该缩放器的行为MinMaxScaler与此类似,因此也存在大的异常值。
3.2.3 正态分布化(Normalization)
正则化的过程是将每个样本缩放到单位范数(每个样本的范数为1),如果使用二次型(点积)或者其它核方法计算两个样本之间的相似性时这个方法会很有用。
该方法是文本分类和聚类分析中经常使用的向量空间模型(Vector Space Model)的基础。
Normalization主要思想是对每个样本计算其p-范数,然后对该样本中每个元素除以该范数,这样处理的结果是使得每个处理后样本的p-范数(l1-norm,l2-norm)等于1。
公式:
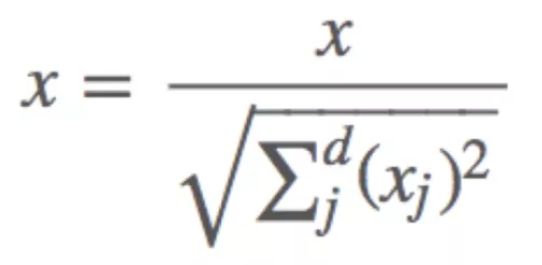
3.2.4 标准化与归一化对比
相同点:
它们的相同点在于都能取消由于量纲不同引起的误差;都是一种线性变换,都是对向量X按照比例压缩再进行平移。
不同点:
目的不同,归一化是为了消除纲量压缩到[0,1]区间;标准化只是调整特征整体的分布;
归一化与最大,最小值有关;标准化与均值,标准差有关;
归一化输出在[0,1]之间;标准化无限制。
使用范围:
如果对输出结果范围有要求,用归一化;
如果数据较为稳定,不存在极端的最大最小值,用归一化;
如果数据存在异常值和较多噪音,用标准化,可以间接通过中心化避免异常值和极端值的影响。
应用场景:
在分类、聚类算法中,需要使用距离来度量相似性的时候(如SVM、KNN)、或者使用PCA技术进行降维的时候,标准化(Z-score standardization)表现更好;
在不涉及距离度量、协方差计算、数据不符合正太分布的时候,可以使用归一化方法。(比如图像处理中,将RGB图像转换为灰度图像后将其值限定在[0 255]的范围;)
基于树的方法不需要特征的归一化。(例如随机森林,bagging与boosting等方法。)
如果是基于参数的模型或者基于距离的模型,因为需要对参数或者距离进行计算,都需要进行归一化。
0x04 数值型特征特征分箱(数据离散化)
离散化是数值型特征非常重要的一个处理,其实就是要将数值型数据转化成类别型数据。连续值的取值空间可能是无穷的,为了便于表示和在模型中处理,需要对连续值特征进行离散化处理。
分箱的重要性及其优势:
离散特征的增加和减少都很容易,易于模型的快速迭代;
稀疏向量内积乘法运算速度快,计算结果方便存储,容易扩展;
离散化后的特征对异常数据有很强的鲁棒性;
对于线性模型,表达能力受限;单变量离散化为N个后,每个变量有单独的权重,相当于模型引入了非线性,能够提升模型表达能力,加大拟合;
离散化后可以进行特征交叉,由M+N个变量变为M*N个变量,进一步引入非线性,提升表达能力;
特征离散化后,模型会更稳定;(怎么划分区间是门学问)
特征离散化以后,起到了简化了逻辑回归模型的作用,降低了模型过拟合的风险;
可以将缺失作为独立的一类带入模型;
将所有变量变换到相似的尺度上。
4.1 无监督分箱法
4.1.1 自定义分箱
自定义分箱,是指根据业务经验或者常识等自行设定划分的区间,然后将原始数据归类到各个区间中。
4.1.2 等距分箱
按照相同宽度将数据分成几等份。缺点,是受到异常值的影响比较大。
4.1.3 等频分箱
将数据分成几等份,每等份数据里面的个数是一样的。区间的边界值要经过选择,使得每个区间包含大致相等的实例数量。
4.1.4 聚类分箱
基于k均值聚类的分箱:k均值聚类法将观测值聚为k类,但在聚类过程中需要保证分箱的有序性:第一个分箱中所有观测值都要小于第二个分箱中的观测值,第二个分箱中所有观测值都要小于第三个分箱中的观测值,等。
实现步骤:
0.对预处理后的数据进行归一化处理;
1.将归一化处理过的数据,应用k-means聚类算法,划分为多个区间:采用等距法设定k-means聚类算法的初始中心,得到聚类中心;
2.在得到聚类中心后将相邻的聚类中心的中点作为分类的划分点,将各个对象加入到距离最近的类中,从而将数据划分为多个区间;
3.重新计算每个聚类中心,然后重新划分数据,直到每个聚类中心不再变化,得到最终的聚类结果。
4.1.5 二值化(Binarization)
二值化可以将数值型(numerical)的feature进行阀值化得到boolean型数据。这对于下游的概率估计来说可能很有用(比如:数据分布为Bernoulli分布时)。
定量特征二值化的核心在于设定一个阈值,大于阈值的赋值为1,小于等于阈值的赋值为0。
4.2 有监督分箱法
4.2.1 卡方分箱法
自底向上的(即基于合并的)数据离散化方法。它依赖于卡方检验:具有最小卡方值的相邻区间合并在一起,直到满足确定的停止准则。
基本思想
对于精确的离散化,相对类频率在一个区间内应当完全一致。因此,如果两个相邻的区间具有非常类似的类分布,则这两个区间可以合并;否则,它们应当保持分开。而低卡方值表明它们具有相似的类分布。
实现步骤:
0.预先定义一个卡方的阈值;
1.初始化;根据要离散的属性对实例进行排序,每个实例属于一个区间;
2.合并区间;计算每一对相邻区间的卡方值;将卡方值最小的一对区间合并。
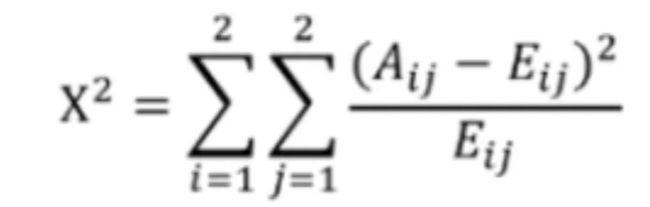
阈值的意义
类别和属性独立时,有90%的可能性,计算得到的卡方值会小于4.6。大于阈值4.6的卡方值就说明属性和类不是相互独立的,不能合并。如果阈值选的大,区间合并就会进行很多次,离散后的区间数量少、区间大。
注意:
ChiMerge算法推荐使用0.90、0.95、0.99置信度,最大区间数取10到15之间;
也可以不考虑卡方阈值,此时可以考虑最小区间数或者最大区间数。指定区间数量的上限和下限,最多几个区间,最少几个区间;
对于类别型变量,需要分箱时需要按照某种方式进行排序。
4.2.2 最小熵法分箱
需要使总熵值达到最小,也就是使分箱能够最大限度地区分因变量的各类别。
熵是信息论中数据无序程度的度量标准,提出信息熵的基本目的是找出某种符号系统的信息量和冗余度之间的关系,以便能用最小的成本和消耗来实现最高效率的数据存储、管理和传递。
数据集的熵越低,说明数据之间的差异越小,最小熵划分就是为了使每箱中的数据具有最好的相似性。给定箱的个数,如果考虑所有可能的分箱情况,最小熵方法得到的箱应该是具有最小熵的分箱。
0x05 sklearn中的数据预处理和特征工程,补充
5.1 sklearn数据预处理和特征工程相关的模块
sklearn六大板块中有两块都是关于数据预处理和特征工程的,两个板块互相交互,为建模之前的全部工程打下基础。

模块preprocessing:几乎包含数据预处理的所有内容
模块Impute:填补缺失值专用
模块feature_selection:包含特征选择的各种方法的实践
模块decomposition:包含降维算法
5.2 缺失值
impute.SimpleImputer
class sklearn.impute.SimpleImputer(missing_values=nan, strategy=’mean’, fill_value=None, verbose=0, copy=True)
对比不同的缺失值填补方式对数据的影响。这个类是专门用来填补缺失值的。它包括四个重要参数:
参数含义&输入
missing_values:告诉SimpleImputer,数据中的缺失值长什么样,默认空值np.nan
strategy:我们填补缺失值的策略,默认均值。 输入“mean”使用均值填补(仅对数值型特征可用) 输入“median"用中值填补(仅对数值型特征可用) 输入"most_frequent”用众数填补(对数值型和字符型特征都可用) 输入“constant"表示请参考参数“fill_value"中的值(对数值型和字符型特征都可用)
fill_value:当参数startegy为”constant"的时候可用,可输入字符串或数字表示要填充的值,常用0
copy默认为True:将创建特征矩阵的副本,反之则会将缺失值填补到原本的特征矩阵中去。
5.3 处理分类型特征:编码与哑变量
在机器学习中,大多数算法,譬如逻辑回归,支持向量机SVM,k近邻算法等都只能够处理数值型数据,不能处理文字,在sklearn当中,除了专用来处理文字的算法,其他算法在fit的时候全部要求输入数组或矩阵,也不能够导入文字型数据(其实手写决策树和普斯贝叶斯可以处理文字,但是sklearn中规定必须导入数值型)。然而在现实中,许多标签和特征在数据收集完毕的时候,都不是以数字来表现的。在这种情况下,为了让数据适应算法和库,我们必须将数据进行编码,即是说,将文字型数据转换为数值型。
preprocessing.LabelEncoder:标签专用,能够将分类转换为分类数值
preprocessing.OrdinalEncoder:特征专用,能够将分类特征转换为分类数值
preprocessing.OneHotEncoder:独热编码,创建哑变量
参考阅读:
1.《机器学习的敲门砖:归一化与KD树》
2.《特征工程系列:特征预处理(上)》
3.《sklearn中的数据预处理和特征工程》
延伸阅读:
特征工程系列:特征筛选的原理与实现(上)
特征工程系列:特征筛选的原理与实现(下)
特征工程系列:数据清洗
代码另附。