【数据结构】位图与布隆过滤器
一、位图:
由题引入:
【问题】:给40亿个不重复的无符号整数,没排过序。给一个无符号整数,如何快速判断一个数是否在这40亿个数中。
如果将40亿个数按整型放入内存,显然不科学,就算内存足够,这样做也是浪费空间;排序也一样,存不下;如果用搜索树当然更不行,一个节点有左右孩子,数等,比16G还大,哈希桶也存不下,有一个指针,和数据。这时我们想到直接定址法的哈希,但是直接定地址法的哈希要开整形最大值那么大的整形的空间。42亿九千万个整形大概也就是16G多,存不下,但是我们想到只让判断这个数在或者不在两种状态,用一个比特位就可以表示,没有必要 开一个整形,这样就不需要16G,只需16G/4/8=500M,这时我们的内存就可以存下,这就是所说的位图。
【解决思路】:用一个比特位表示一个数,存在的话该位上就置为1,不在的话置为0;这样40亿个数需要40亿个比特位,换算一下也就是500M,相对于16G来说,大大节省了空间。
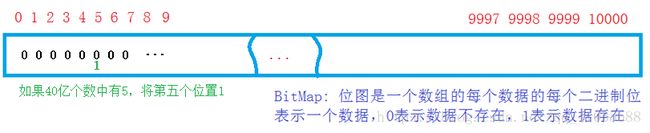
注意:位图也是一种直接定址法的哈希。本质是用一个数组,但是用一个比特位来表示一种状态,0表示不存在,1表示存在。当然只适合判断,查找整形数据是否存在,且只能对整数进行处理。
【参考代码】:
typedef struct BitMapNode
{
char* bit; //指向N位组成的空间
size_t N; //总的位数
}BitMap;
//位图初始化
void BitMapInit(BitMap* pbm, size_t len)
{
assert(pbm);
//加一为了使得在为某数寻址时,统一,即向上取整
// 假如len为25,25/8=4,但是要5个字节才能存的下
pbm->bit = (char*)malloc(((len>>3)+1));
assert(pbm->bit);
memset(pbm->bit,0, sizeof((len>>3)+1));
pbm->N = len;
}
//位图销毁
void BitMapDestroy(BitMap* pbm)
{
assert(pbm);
free(pbm->bit);
pbm->bit = NULL;
pbm->N = 0;
printf("销毁成功\n");
}
//位图
void BitMapSet(BitMap* pbm, int x)
{
assert(pbm);
int index = x >> 3;
int num = x % 8;
pbm->bit[index] |= (1<<num);
}
void BitMapReset(BitMap* pbm, int x)
{
assert(pbm);
int index = x >> 3;
int num = x % 8;
pbm->bit[index] &= ~(1<<num);
}
int BitMapTest(BitMap* pbm, int x)
{
assert(pbm);
int index = x >> 3;
int num = x % 8;
return (pbm->bit[index]&(1<<num)) == 1;
}
void TestBitMap()
{
BitMap bm;
BitMapInit(&bm,10);
BitMapSet(&bm,78);
BitMapSet(&bm, 99);
BitMapSet(&bm, 55);
BitMapSet(&bm, 76);
BitMapSet(&bm,12);
printf(" %d ",BitMapTest(&bm,99));
BitMapReset(&bm,78);
printf(" %d ",BitMapTest(&bm,78));
BitMapDestroy(&bm);
}
优点:(1)相对来说节省了不少空间。当需要处理的数量级较大时,这个优点显露无疑。(2)查找、删除效率高。位图只是在创建的时候开辟空间消耗时间,但是当位图创建完成后查找、删除只需一步操作。
缺点: 不能判断字符串是否存在
【问题】给定100亿个数据,找到只出现一次的整数
【解决思路】:
( 100亿整数需要多少内存呢?一个整数4个字节,100亿个整数400亿个字节,1G是10^9个字节,那么400亿个字节就是大约40G的内存,我们根本没有这么大的内存,所以只能另想办法了。
【解决方法】:
解决方法一:
1.将100亿个整数切分成100份,每份大约500MB
2.将每一份加载到内存中放在一个哈希表中,通过哈希表找出只出现一次的数
3.将100份中所有只出现一次的数合并在一起
解决方法二:
利用位图,所谓的位图,是利用一个bit 位来保存一个数据的状态,该数据在,则用1表示,不在,则用0表示。这里有100亿个数据,如果按照一个比特位来保存数据的话,需要512M空间的大小。而这里要统计数据出现的次数,我们知道,数据可能出现0次,可能出现1次,也可能出现多次,那么我们可以用两个比特位来表示数据存储的次数,即00表示0次,01表示出现1次,10表示数据出现多次,11则不表示任何状态,也就需要1G大小的内存空间,刚好够使用。这样我们利用位图就可以找到出现一次的整数。时间复杂度为O(n),空间复杂度为O(1);
二、 布隆过滤器
【问题】在40亿个字符串集合中,快速判断一个字符串在或者不在?
这个题我们也可以用位图,可是这是字符串又不是整数,我们可以把字符串通过在字符串哈希转换为整数。可是这时候会产生哈希冲突,会产生误判,一个数明明没在,却判断为在,于是我们可以将一个元素经过不同的哈希函数,映射到多个位置,如果这几个位置上都为1,我们就认为这个元素存在,如果有一个位为0,就表示不存在。这就是所谓的布隆。
布隆:是位图+字符串哈希的结合。基本思想是:通过一个哈希函数将一个元素映射到一个位置,我们只要判断这个位置是不是存在,就能判断是否存在,但是由于哈希冲突的原因,不同的元素经过哈希函数会映射到相同的哈希地址,导致误判,为了缓解误判,我们将一个元素经过多个散列函数映射到多个位置上,如果这多个位都存在,我们认为存在,如果有一个位不存在,则不存在。
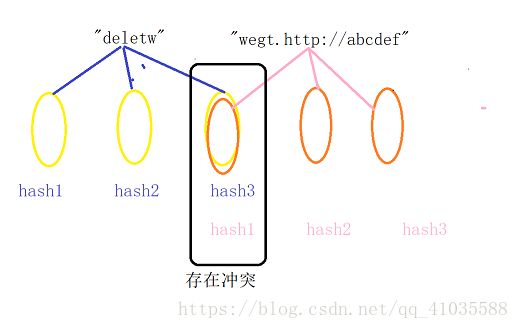
注意:布隆过滤器是存在不准确,不存在准确。
【参考代码】:
typedef char* DataType;
typedef struct BloomFilterNode
{
BitMap Bloom;
}BloomFilter;
//哈希函数1
int HashFunc1(DataType x)
{
int index = 0;
int *p = x;
while (*p)
{
index = index * 131 + *p;
p++;
}
return index;
}
//哈希函数2
int HashFunc2(DataType x)
{
int index = 0;
int *p = x;
while (*p)
{
index = index * 1331 + *p;
p++;
}
return index;
}
//哈希函数3
int HashFunc3(DataType x)
{
int index = 0;
int *p = x;
while (*p)
{
index = index * 13322 + *p;
p++;
}
return index;
}
//布隆过滤器初始化
void BloomFilterInit(BloomFilter* bf, size_t len)
{
assert(bf);
BitMapInit(&bf->Bloom, len * 5);
}
//布隆过滤器销毁
void BloomFilterDestroy(BloomFilter* bf)
{
assert(bf);
BitMapDestroy(&bf->Bloom);
}
//布隆过滤器计数
void BloomFilterSet(BloomFilter* bf, DataType x)
{
assert(bf);
int hash1 = HashFunc1(x) % bf->Bloom.N;
int hash2 = HashFunc2(x) % bf->Bloom.N;
int hash3 = HashFunc3(x) % bf->Bloom.N;
BitMapSet(&bf->Bloom, hash1);
BitMapSet(&bf->Bloom, hash2);
BitMapSet(&bf->Bloom, hash3);
}
//布隆过滤器重置
void BloomFilteReset(BloomFilter* bf, DataType x); //不支持
//布隆过滤器测试
int BloomFilterTest(BloomFilter* bf, DataType x)
{
assert(bf);
int hash1 = HashFunc1(x) % bf->Bloom.N;
if (BitMapTest(&bf->Bloom, hash1) == 0)
{
return 0;
}
int hash2 = HashFunc2(x) % bf->Bloom.N;
if (BitMapTest(&bf->Bloom, hash2) == 0)
{
return 0;
}
int hash3 = HashFunc3(x) % bf->Bloom.N;
if (BitMapTest(&bf->Bloom, hash3) == 0)
{
return 0;
}
return 1;//这是不确定的
}
//测试
void TestBloomFilter()
{
BloomFilter bf;
BloomFilterInit(&bf, 10);
BloomFilterSet(&bf, "scadcascs");
BloomFilterSet(&bf, "school");
BloomFilterSet(&bf, "urlur");
BloomFilterSet(&bf, "sort");
printf("%d\n", BloomFilterTest(&bf, "sdsd"));
printf("%d\n", BloomFilterTest(&bf, "school"));
printf("%d\n", BloomFilterTest(&bf, "sort"));
BloomFilterDestroy(&bf);
}
优点:
- 相比于其它的数据结构,布隆过滤器在空间和时间方面都有巨大的优势。布隆过滤器存储空间和插入/查询时间都是常数;另外, Hash 函数相互之间没有关系,方便由硬件并行实现;布隆过滤器不需要存储元素本身,在某些对保密要求非常严格的场合有优势;布隆过滤器可以表示全集,其它任何数据结构都不能.
缺点:
- 布隆过滤器的缺点和优点一样明显。误算率是其中之一。随着存入的元素数量增加,误算率随之增加。但是如果元素数量太少,则使用散列表足矣。另外,一般情况下不能从布隆过滤器中删除元素。 我们很容易想到把位列阵变成整数数组,每插入一个元素相应的计数器加1, 这样删除元素时将计数器减掉就可以了。然而要保证安全的删除元素并非如此简单。首先我们必须保证删除的元素的确在布隆过滤器里面。 这一点单凭这个过滤器是无法保证的。另外计数器回绕也会造成问题。
【问题一】怎样降低误判的概率?
答:多个哈希函数进行映射
【问题二】有一份黑名单,为了降低冲突的可能性,我们需要看某个记录是否在黑名单中?
【解决方法】:
首先布隆过滤器底层搭载的是位图,但是有不同的哈希函数。
先将记录转化为整型数字,假设有5种不同的方式,即用5个比特位来表示是否有这个人,此时冲突的概率会大大降低。若5个bit为全为1,则这个人有可能在黑名单中,若有一个为0,则这个人一定不在黑名单中。
布隆过滤器判断不存在一定是准确的,但是判断存在可能不准确。
三、大数据处理问题
1.给一个超过100G大小的log file, log中存着IP地址, 设计算法找到出现次数最多的IP地址?!
2.与上题条件相同,如何找到top K的IP?如何直接用Linux系统命令实现?!
3.给定100亿个整数,设计算法找到只出现一次的整数!
4.给两个文件,分别有100亿个整数,我们只有1G内存,如何找到两个文件交集!
5.1个文件有100亿个int,1G内存,设计算法找到出现次数不超过2次的所有整数!
6.给两个文件,分别有100亿个url,我们只有1G内存,如何找到两个文件交集?分别给出精确算法和近似算法!
7.如何扩展BloomFilter使得它支持删除元素的操作?如何扩展BloomFilter使得它支持计数操作?!
8.给上千个文件,每个文件大小为1K—100M。给n个词,设计算法对每个词找到所有包含它文件,你只有100K内存!
9.有一个词典,包含N个英文单词,现在任意给一个字符串,设计算法找出包含这个字符串的所有英文单词!
第1题、给一个超过100G大小的log file, log中存着IP地址, 设计算法找到出现次数最多的IP地址
- 这是一个大小为100G的一个日志文件,主要问题就是一般的计算机内存肯定放不下;第一个想到的办法就是切分,把100G的文件切成100份,然后把这100个文件当作是大小为100的哈希表,而每份只有1G的大小,就可以依次读入内存进行处理。题目要求是:找到出现次数最多的IP地址,那么文件中肯定存在大量的相同IP地址,思路是让相同的IP存入同一文件,这时又要用到哈希字符串函数,就是上面布隆过滤器用到的转换函数,由相同的IP转换得到的key值一定相同,然后根据index = key%100决定存在于哪一个文件中,而相同的IP也就进入了同一个文件。
- 然后对单个文件进行处理,找出这个文件中出现次数最多的IP,以IP为key值,value记录出现的次数,用key_value结构的搜索树就可以很快找出来,然后用MAX记录下来,读入下一个文件,然后比较MAX值,遇到更大的就更新,最后得到的MAX就是这个100G文件中出现次数最多的IP地址。
这个题目中的重点思想就是哈希切分。
第2题、一个超过100G大小的log file, 存着IP地址,找到top K的IP。如何直接用Linux系统命令实现?
这一题条件同上一题,不同的是由求次数最多的一个改为求次数最多的前K个。思路同上题,哈希切分然后用堆排序,还是以IP为key值,然后统计各个文件中每个IP出现的次数(方法同第一题,也就是说每个文件建一颗搜索树), 然后取其中的K个(key_value结构)结点以次数建一个最小堆;然后将其余的节点依次与堆顶节点比较,如果大于堆顶节点,与其一换,交换之后对堆进行一次向下调整,保证堆顶元素仍是堆中最小,直到所有IP都比较完。然后堆中的就是top K个IP了。
这题是个典型的top K问题,重点是建小堆,然后交换堆顶元素。
第3题、给定100亿个整数,找到只出现一次的整数
与上面同样的一个问题是100亿整数这样一个庞大的数字,大约是35G的大小。但是整数能表示的最大范围也就是2的32次方 那么大约就是16G的大小,那么剩下的就都是重复的数,这道题没有规定死内存大小,但是16G还是比较大,浪费内存资源,如何继续缩小内存,还是利用位图思想。与前例腾讯笔试题不同的是,这里需要区分更多的状态,我们需要表示的状态有:00不存在, 01出现一次,10出现多次(>=2次),11不表示。也就是说我们需要用两个比特位来表示一个数的状态,然后遍历一遍位图找到状态为01的数,就是只出现一次的整数。
这个题重点是两个比特位的位图思想。
第4题、两个文件,分别有100亿个整数,我们只有1G内存,找到两个文件的交集
- 此题初始思路同上,建立位图,不在赘述,这里主要讲求交集。可以对其中一个文件建立位图,然后从另一个文件中依次取数据,判断是否在位图中。数据判断完存在的即为交集。另一种思路,如果这里还有1G的内存的话,可以给两个文件分别键位图,然后比较对应的数据位。
- 第二种方法是哈希切分,将两个文件都切分为1000小份,每个文件的大小就几十兆的样子,分别对两个对文件里的整数进行哈希分配,即将所有整数模除1000,使相同的数进入相同的文件,然后分别拿A哈希切分好的第一个文件和B哈希切分好的第一个文件对比,找出交集存到一个新文件中,依次类推,直到2000个文件互相比较完。
这个题重点是位图思想和哈希切分。
第5题、1个文件有100亿个int,1G内存,找到出现次数不超过2次的所有整数
这个题思路同第三题,用两个比特位表示的位图,我们需要表示的状态有:00不存在, 01出现1次,10出现2次,11出现多次(>2次)。
这个题重点也是两个比特位的位图思想。
第6题、两个文件,分别有100亿个url,我们只有1G内存,找到两个文件交集,分别给出精确算法和近似算法。
与第四题类似只是这里存的是URL,所以要用布隆过滤器。近似算法是,将一个文件内容存到布隆过滤器中,方法如上面介绍的布隆过滤器中的一样,然后从另一个文件中一个个的取URL判断是否在布隆中存在的就是交集。为什么布隆过滤器是近似算法,是因为它的不存在是确定的,存在是不确定的,即一个字符串对应5个位, 如果有一个位为0,则这字符串肯定不存在,如果一个字符串对应的5个位都为1,但是这个字符串却不 一定存在,因为可能这5个位都是被其它字符串的对应位置为1的,这就是其中的哈希冲突问题。
精确算法同第四题的方法二,哈希切分。
第7题、扩展BloomFilter使得它支持删除元素的操作或支持计数操作
因为布隆过滤器的一个Key对应多个位,所以如果要删除的话,就会有些麻烦,不能单纯的将对应位全部置为0,因为可能还有其它key对应这些位,所以,需要对每一个位进行引用计数,以实现删除的操作。因为需要每一个对应位都需要一个计数,所以每一位至少需要一个int,那么我们就不得不放弃位图了,也就是放弃了最小的空间消耗,我们需要直接以一个就像数组一样的实现,只不过数组的内容存放的是引用计数。
第8题、给上千个文件,每个文件大小为1K—100M。给n个词,设计算法对每个词找到所有包含它的文件,你只有100K内存!
牛客网上的解析:
0: 用一个文件info 准备用来保存n个词和包含其的文件信息。
1 : 首先把n个词分成x份。对每一份用生成一个布隆过滤器(因为对n个词只生成一个布隆过滤器,内存可能不够用)。把生成的所有布隆过滤器存入外存的一个文件Filter中。
2:将内存分为两块缓冲区,一块用于每次读入一个布隆过滤器,一个用于读文件(读文件这个缓冲区使用相当于有界生产者消费者问题模型来实现同步),大文件可以分为更小的文件,但需要存储大文件的标示信息(如这个小文件是哪个大文件的)。
3:对读入的每一个单词用内存中的布隆过滤器来判断是否包含这个值,如果不包含,从Filter文件中读取下一个布隆过滤器到内存,直到包含或遍历完所有布隆过滤器。如果包含,更新info 文件。直到处理完所有数据。删除Filter文件。
备注:
1:关于布隆过滤器:其实就是一张用来存储字符串hash值的BitMap.
2:可能还有一些细节问题,如重复的字符串导致的重复计算等要考虑一下。
第9题、有一个词典,包含N个英文单词,现在任意给一个字符串,设计算法找出包含这个字符串的所有英文单词!
思路:用kmp算法或者字典树,KMP算法可见我的另一篇文章:字符串模式匹配问题
第10题、使用位图法判断整形数组是否存在重复
判断集合中存在重复是常见编程任务之一,当集合中数据量比较大时我们通常希望少进行几次扫描,这时双重循环法就不可取了。
位图法比较适合于这种情况,它的做法是按照集合中最大元素max创建一个长度为max+1的新数组,然后再次扫描原数组,遇到几就给新数组的第几位置上1,如遇到 5就给新数组的第六个元素置1,这样下次再遇到5想置位时发现新数组的第六个元素已经是1了,这说明这次的数据肯定和以前的数据存在着重复。这种给新数组初始化时置零其后置一的做法类似于位图的处理方法故称位图法。它的运算次数最坏的情况为2N。如果已知数组的最大值即能事先给新数组定长的话效率还能提高一倍。
第11题、已知某个文件内包含一些电话号码,每个号码为8位数字,统计不同号码的个数。
8位最多99 999 999,大概需要99m个bit,大概10几m字节的内存即可。 (可以理解为从0-99 999 999的数字,每个数字对应一个Bit位,所以只需要99M个Bit==1.2MBytes,这样,就用了小小的1.2M左右的内存表示了所有的8位数的电话)
第12题、给40亿个不重复的unsigned int的整数,没排过序的,然后再给一个数,如何快速判断这个数是否在那40亿个数当中?
bitmap算法就好办多了。申请512M的内存,一个bit位代表一个unsigned int值,读入40亿个数,设置相应的bit位;读入要查询的数,查看相应bit位是否为1,为1表示存在,为0表示不存在。
Note: unsigned int最大数为2^32 - 1,所以需要2^32 - 1个位,也就是(2^32 - 1) / 8 /10 ^ 9G = 0.5G内存。
逆向思维优化:usinged int只有接近43亿(unsigned int最大值为232-1=4294967295,最大不超过43亿),所以可以用某种方式存没有出现过的3亿个数(使用数组{大小为3亿中最大的数/8 bytes}存储),如果出现在3亿个数里面,说明不在40亿里面。3亿个数存储空间一般小于40亿个。(xx存储4294967296需要512MB, 存储294967296只需要35.16MBxx)
第13题、给定一个数组a,求所有和为SUM的两个数。
如果数组都是整数(负数也可以,将所有数据加上最小的负数x,SUM += 2x就可以了)。如a = [1,2,3,4,7,8],先求a的补数组[8,7,6,5,2,1],开辟两个数组b1,b2(最大数组长度为SUM/8/2{因为两数满足和为SUM,一个数 < SUM / 2,另一个数也就知道了},这样每个b数组最大内存为SUM/(821024*1024) = 128M),使用bitmap算法和数组a分别设置b1b2对应的位为1,b1b2相与就可以得到和为SUM的两个数其中一个数了。
第14题、在2.5亿个整数中找出不重复的整数,注,内存不足以容纳这2.5亿个整数
- 解法一:将bit-map扩展一下,采用2-Bitmap(每个数分配2bit,00表示不存在,01表示出现一次,10表示多次,11无意义)进行,共需内存2^32 * 2 bit=1 GB内存,还可以接受。然后扫描这2.5亿个整数,查看Bitmap中相对应位,如果是00变01,01变10,10保持不变。所描完事后,查看bitmap,把对应位是01的整数输出即可。或者我们不用2bit来进行表示,我们用两个bit-map即可模拟实现这个2bit-map,都是一样的道理。
- 解法二:也可采用与第1题类似的方法,进行划分小文件的方法。然后在小文件中找出不重复的整数,并排序。然后再进行归并,注意去除重复的元素。
2.1 一个序列里除了一个元素,其他元素都会重复出现3次,设计一个时间复杂度与空间复杂度最低的算法,找出这个不重复的元素。
第15题、给一个超过100G的文件,文件中保存的是IP地址,设计算法找到出现次数最多的IP地址,并找出前topK的IP地址。
解决方法:
(1)我们可以从文件中拿出一条IP地址,将所有IP地址遍历一遍,和其他IP地址进行比较,统计次数。在这种方式下,时间复杂度是O(n^2); 但是由于文件太大,I/O操作过于频繁,操作效率不高。
(2)我们可以利用哈希的思想,将100G的文件先切割成110份,每份文件的大小是1G,分别编号;
将文件中的IP地址按照某种方式转化为整型,再设置哈希函数,将IP地址放入不同的文件编号中。
则同一个文件编号存放的IP地址要么相同要么不同。
我们要找出现次数最多的IP地址,可以将IP地址和出现的次数作为键值对封装在unordered_map中。
要找出前topK 的IP地址,我们可以采用堆排,首先取出10个IP地址建立小堆,然后每次取出一个IP地址和堆顶元素比较,如果比堆顶元素大,就交换,依次进行,知道全比较结束。
第16题、4.1个文件有100亿个int,1G内存,设计算法找到出现次数不超过2次的所有整数?
解决方法:借助位图解决。要解决找出只出现次数不超过2次的数字,我们可以增加位图状态,用两个比特位作为哈希映射的地址,我们可以让00(不存在)、01(只出现一次)、11(出现两次)、10(出现两次以上)。
建两个文件,设置一个值key,大于这个key的数进入第一个文件;小于key值的数进入第二个文件(设置的key尽量使得这两个文件中数的数目差不多)
将第一个文件中的所有数的状态存到一个位图中(第一个文件以位图存储大约需要9540多MB的内存),然后通过查找,找出文件一中出现次数不超过两次的所有整数
第二个文件和第一个文件方法一样
合并两个文件中所有找到的数
第17题、给两个文件,分别有100亿个query,我们只有1G内存,如何找到两个文件交集?分别给出精确算法和近似算法?
精确算法:哈希切分。和第三题哈希切割的方法是一样的,只需要将HashFunc变为处理字符串的即可。(query查询)
近似算法:布隆过滤器。将一个文件的query放在布隆过滤器中,然后在用另一个文件中的query去查布隆过滤器中存不存在。布隆过滤器查找存在是不精确的。
第18题、如何扩展BloomFilter使得它支持删除元素的操作?
因为一个布隆过滤器的key对应多个位,冲突的概率比较大,所以不支持删除,因为删除有可能影响到其他元素。如果要对其元素进行删除,就不得不对每一个位进行引用计数。将BloomFilter中的每一位扩展为一个计数器,记录有多少个hash函数映射到这一位;删除的时候,只有当引用计数变为0时,才真正将该位置为0否则减1即可。
第19题、如何扩展BloomFilter使得它支持引用计数操作?
将BloomFilter中的每一位扩展为一个计数器,每个输入元素都要把对应位置加1,从而支持计数操作。但是有一个问题,1个比特位只能是两个状态0和1,我们只能把位图扩大成1字节或者更多,1个字节仅仅能存放计数256,但代价依旧是浪费内存。
结语
在任何时候,都应该坚信坚毅的人生终将开除灿烂的花朵