Window使用idea操作spark连接hive
首先说下这样做的好处,不用每次都打成jar包在集群测试,直接在本地就可以测试。
平台环境:hadoop 2.6.0-CDH5.7 Hive 1.1.0 Spark 1.6.0 Scala 2.11.5
项目环境:jdk 1.8 scala2.11.0
1.创建新工程
1.创建一个maven工程,不做赘述。
工程目录结构如下:
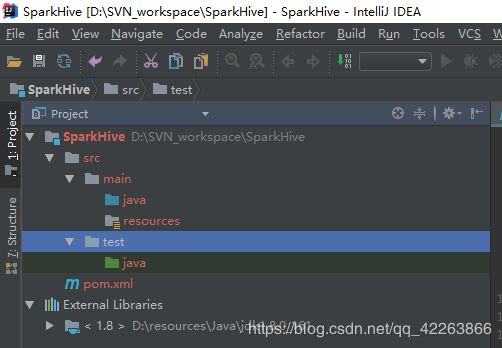
2.配置环境
1.左上角File ->Project Structure ->Modules
添加依赖环境 scala-sdk-2.11.0
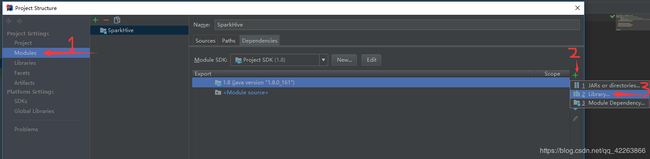
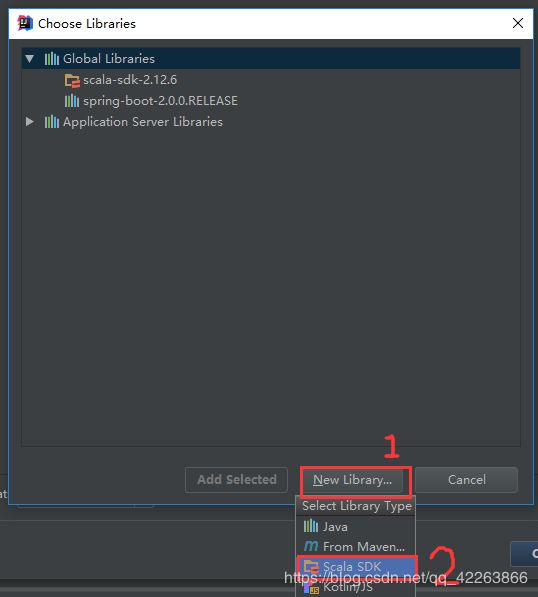
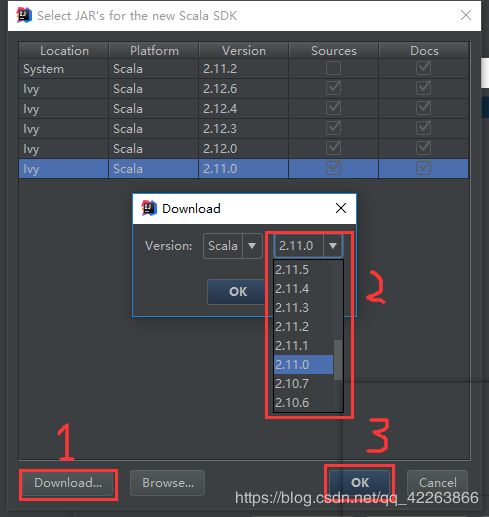
2.选中刚才下的scala-sdk-2.11.0 ->Add selected 添加
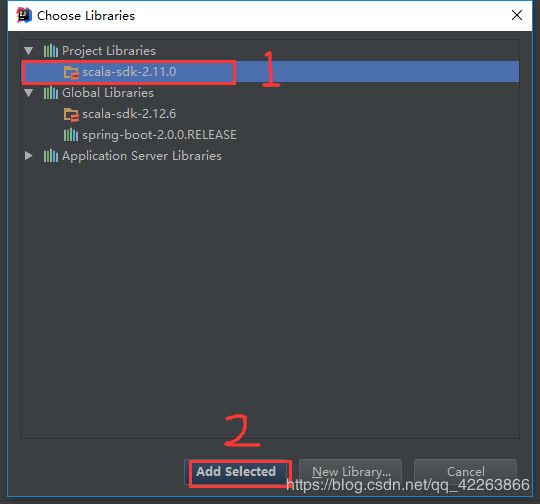
回到 project structure->Apply。工程环境即可看到scala-sdk-2.11.0
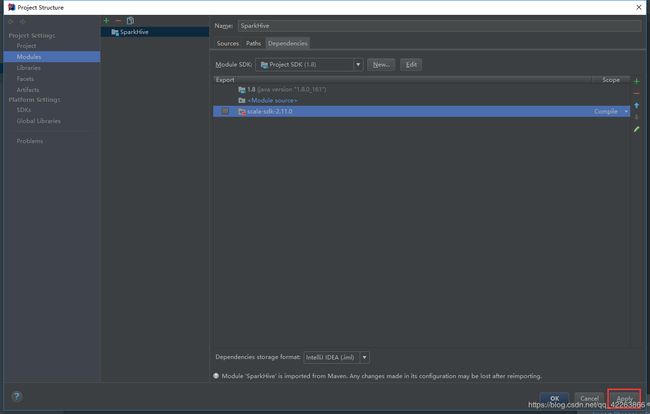
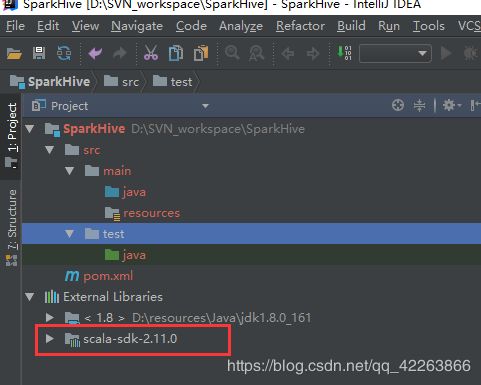
3.在Project Structuer 添加 scala 文件夹
右击main->New Folder 命名为scala
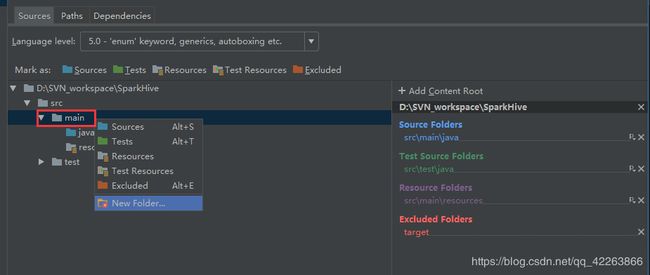
选中scala文件夹 点击上面Sources,一定要设置,不然无法在scala目录下创建scala Class
点击Aplly
创建scala object
4.配置本地HADOOP_HOME
下载winutils的windows的版本,地址:https://github.com/srccodes/hadoop-common-2.2.0-bin,直接下载此项目的zip包,下载后是文件名是hadoop-common-2.2.0-bin-master.zip,随便解压到一个目录 例如:(D:\profile\)
方法1:加入代码
System.setProperty("hadoop.home.dir", "D:\\profile\\hadoop-common-2.2.0-bin-master")
方法2:设置环境变量
增加用户变量HADOOP_HOME,值是下载的zip包解压的目录(D:\jars\hadoop-common-2.2.0-bin-master),然后在系统变量path里增加%HADOOP_HOME%\bin 即可
原因:程序需要根据HADOOP_HOME找到winutils.exe,由于win并没有配置该环境变量,所以程序报 null\bin\winutils.exe
5.配置pom.xml
1.6.0
2.10
org.apache.spark
spark-core_${scala.version}
${spark.version}
org.apache.spark
spark-streaming_${scala.version}
${spark.version}
org.apache.spark
spark-sql_${scala.version}
${spark.version}
org.apache.spark
spark-hive_${scala.version}
${spark.version}
org.apache.spark
spark-mllib_${scala.version}
${spark.version}
6.将hive-conf下hive-site.xml;hadoop-conf下core-site.xml;hdfs-conf下hfds-site.xml 放入工程目录resources下
将hive-site.xml复制到Spark-Home/conf目录下 重启集群生效
3.测试代码
import org.apache.spark.sql.hive.HiveContext
import org.apache.spark.{SparkConf, SparkContext}
object App {
def main(args: Array[String]): Unit = {
System.setProperty("hadoop.home.dir", "D:\\jars\\hadoop-2.2.0")
val conf = new SparkConf().setAppName("firstsparkapp").setMaster("local[*]")
val sc = new SparkContext(conf)
val hiveContext = new HiveContext(sc)
hiveContext.sql("use database_name")
hiveContext.sql("select * from user").show()
sc.stop()
}
}如果运气好,你的win配置和集群配置都配过会一次跑通,控制台会打印出user表的内容
报错
1:idea scala SDK版本需要与依赖scala jar包保持一致
报错:java.lang.NoSuchMethodError:scala,predef$.refArrayOps([Ljava/lang/Object;)Lscala/collection/mutable/ArrayOps;
ERROR Shell: Failed to locate the winutils binary in the hadoop binary path
可能原因:上述配置环境2.4处没配置正确。
java.lang.RuntimeException: java.lang.RuntimeException: The root scratch dir: /tmp/hive on HDFS should be writable.
修改hdfs上/tmp/hive 文件夹权限
[root@n1 ~]# hadoop fs -chmod -R 777 /tmp/hive
在hdfs-site.xml 添加如下内容,或者将你的dfs.permissinos 设为false。(目的:关闭hdfs的权限检查,在操作hdfs上的文件时不对当前用户做权限检查)
dfs.permissions
false
修改重启集群生效
不识别hive-site.xml配置的主机名
需要在hosts文件做映射
C:\Windows\System32\drivers\etc\hosts 文末添加如下内容
192.168.1.181 n1
192.168.1.182 n2
192.168.1.183 n3
无法删除 spark临时文件
ERROR ShutdownHookManager: Exception while deleting Spark temp dir: C:\Users\wgh\AppData\Local\Temp\spark-2920e89f-1a08-4f9a-b684-96a38637c3ee
不影响,win连接spark的bug
Permission denied: user=root, access=WRITE, inode=”/user”:hdfs:supergroup:dr
这个问题的原因是因为Idea在执行程序时,使用了系统用户作为向Hadoop进行写的用户了。比如,你的电脑系统用户是:administrator,而你的Hadoop用户是:hadoop,用户不一样,所以写不进去。
解决办法:设置“HADOOP_USER_NAME=hadoop”为环境变量。
设置的办法有两个:
在Idea里进行设置,点上面的“Edit Configurations”,然后选择要执行的Application,在右边进行设置“Environment Variables”。
设置完后,可以用System.getenv()方法进行测试,看是否能读取到。
spark初学者,有不对的地方请大牛指点指点。