获取鸢尾花数据,设置训练集和测试集
from sklearn.datasets import load_iris
import numpy as np
import matplotlib.pyplot as plt
datas = load_iris()
x_data = datas['data'][0:150]
y_data = datas['target'][0:150]
x_train = x_data[0:150:2]
y_train = y_data[0:150:2]
x_test = x_data[1:150:2]
y_test = y_data[1:150:2]
y_data
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2,
2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2, 2])
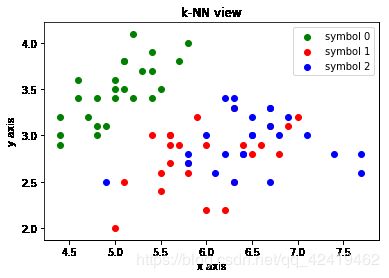
绘制数据集(以,前两个特征绘制在坐标系上)
plt.scatter(x_train[y_train==0,0],x_train[y_train==0,1],color='g',label="symbol 0")
plt.scatter(x_train[y_train==1,0],x_train[y_train==1,1],color='r',label="symbol 1")
plt.scatter(x_train[y_train==2,0],x_train[y_train==2,1],color='b',label="symbol 2")
plt.title("k-NN view")
plt.xlabel("x axis")
plt.ylabel("y axis")
plt.legend()
plt.show()
新增加一个数据(该数据是示例)判断其的类别为0 or 1 or 2(根据距离)
x = np.array([4.5023242,3.03123123,1.3023123,0.102123123])
plt.scatter(x_train[y_train==0,0],x_train[y_train==0,1],color='g',label="symbol 0")
plt.scatter(x_train[y_train==1,0],x_train[y_train==1,1],color='r',label="symbol 1")
plt.scatter(x_train[y_train==2,0],x_train[y_train==2,1],color='b',label="symbol 2")
plt.scatter(x[0],x[1],color='black',label="symbol ?")
plt.title("k-NN view")
plt.xlabel("x axis")
plt.ylabel("y axis")
plt.legend()
plt.show()

K-NN过程(训练)(计算距离,并将其存储到列表)
from math import sqrt
distances = []
for x0 in x_train:
d = sqrt(np.sum((x-x0)**2))
distances.append(d)
near = np.argsort(distances)
k = 3
topK_y = [y_train[i] for i in near[:k]]
topK_y
[0, 0, 0]
from collections import Counter
votes = Counter(topK_y)
votes
Counter({0: 3})
出预测的结果,0代表setosa,1代表versicolor,2代表virginica
result = votes.most_common(1)[0][0]
result
0
注意这里用的是上面的测试数据,但是步骤是重新开始的因为要一个个遍历测试集并将预测结果与源数据中的结果比较得出正确率统计测试数据的精度
count = 0
index = 0
for j in x_test:
distance = []
x = j;
for x1 in x_train:
t = sqrt(np.sum((x-x1)**2))
distance.append(t)
near = np.argsort(distance)
topK_y = [y_train[i] for i in near[:k]]
votes = Counter(topK_y)
result = votes.most_common(1)[0][0]
if y_test[index]==result:
count=count+1
index=index+1
else:
index=index+1
score=count/25
score
0.96